
Adobe研究和德克萨斯大学奥斯汀分校的研究人员推出新型训练范式Self Forcing ,用于自回归视频扩散模型,旨在解决模型在训练和推理时的分布不一致问题(即暴露偏差问题),从而提高视频生成的质量和效率。
- GitHub:https://github.com/guandeh17/Self-Forcing
- 模型:https://huggingface.co/gdhe17/Self-Forcing
- Demo:https://huggingface.co/spaces/multimodalart/self-forcing
现有的视频生成模型主要分为两类:基于扩散模型的双向注意力模型和自回归模型。前者生成质量高但无法实时生成,后者可以实时生成但质量较低。Self Forcing 结合了两者的优点,通过在训练阶段模拟推理过程,使模型在推理时能够生成高质量的视频序列。

主要功能
- 实时视频生成:能够在单个 GPU 上以 17 FPS 的速度生成视频,延迟低于 1 秒,适合实时流媒体、游戏和世界模拟等应用场景。
- 高质量视频生成:生成的视频在视觉质量和语义对齐方面与现有的非因果扩散模型相当甚至更好,同时避免了传统自回归模型中的错误累积问题。
- 长视频生成:通过滚动键值(KV)缓存机制,能够高效地生成任意长度的视频,而无需重新计算缓存,保持了高吞吐量和时间复杂度。
主要特点
- 训练与推理一致性:Self Forcing 在训练阶段通过自回归展开(autoregressive rollout)生成视频,与推理过程完全一致,有效解决了暴露偏差问题。
- 高效训练策略:采用少步扩散模型和随机梯度截断策略,在保持性能的同时降低了计算成本,使训练过程更加高效。
- 灵活的分布匹配损失:支持多种分布匹配损失函数(如 DMD、SiD 和 GAN),可以根据不同的需求选择合适的损失函数来优化模型。
工作原理
- 自回归展开:在训练阶段,模型通过自回归展开生成每个视频帧,即每个帧的生成都基于之前由模型自身生成的帧,而不是真实的帧。这种策略使模型在训练过程中就能学习到如何处理自己的预测错误。
- 少步扩散模型:为了提高训练效率,Self Forcing 使用少步扩散模型来近似每个条件分布,减少了计算量。
- 随机梯度截断:为了避免在长序列上的梯度爆炸或消失问题,Self Forcing 在训练时随机选择一个扩散步骤作为最终输出,并限制梯度回传到该步骤,从而平衡了计算成本和性能。
- 滚动 KV 缓存机制:在生成长视频时,通过维护一个固定大小的 KV 缓存来存储最近帧的嵌入信息,当缓存满时移除最旧的条目,从而实现高效生成。
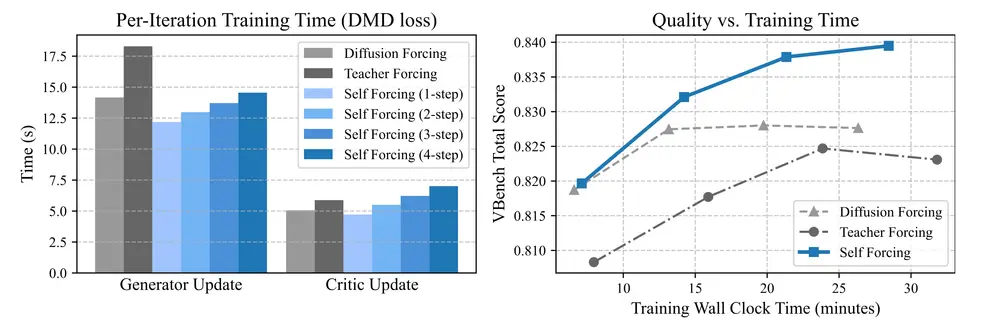
测试结果
- 性能指标:Self Forcing 的 chunk-wise 自回归模型在 VBench 评分中取得了最高分,同时实现了 17 FPS 的吞吐量和 0.69 秒的延迟。frame-wise 变体则在保持高质量的同时,提供了最低的延迟(0.45 秒)。
- 用户偏好研究:在用户偏好研究中,Self Forcing 的 chunk-wise 模型在与多个基线模型的比较中被用户更频繁地选择为更优的视频生成模型。
- 效率对比:Self Forcing 在训练效率上也表现出色,与 Teacher Forcing 和 Diffusion Forcing 相比,在相同的训练时间预算内能够达到更高的质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











