
可控超长视频生成(如生成1分钟以上、场景与动作精准可控的视频)是AI生成领域的核心挑战——现有方法在短视频生成中表现尚可,但扩展到长视频时,常出现时间不一致(帧间突变、物体位置漂移)与视觉质量下降(颜色偏移、细节扭曲)问题。
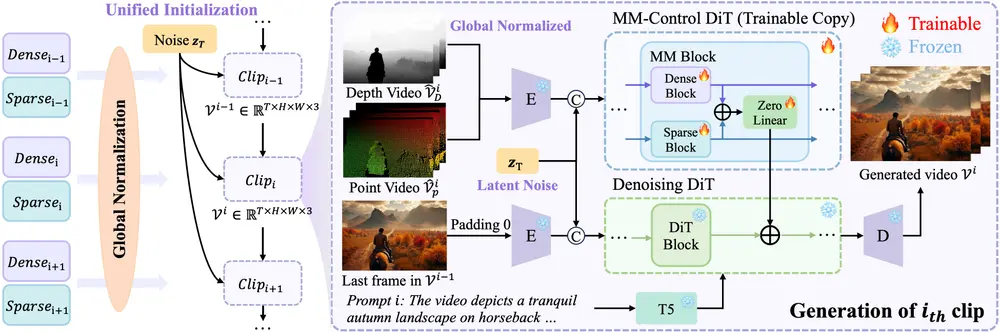
为此,南京大学、复旦大学、南洋理工大学、英伟达及上海人工智能实验室的研究团队,提出 LongVie 自回归端到端框架,通过“统一噪声初始化”“全局控制归一化”“多模态引导”“退化感知训练”四大核心设计,首次实现“1分钟可控长视频生成”,同时保持场景一致性与高视觉质量。团队还构建了 LongVGenBench 基准数据集,为长视频生成研究提供标准化测试平台。

核心痛点:长视频生成为何难?3大关键问题被锁定
研究团队通过对现有方法的拆解,发现长视频生成的瓶颈集中在三个关键因素,这些问题直接导致“时间不一致”与“质量下降”:
1. 独立的噪声初始化:帧间突变的根源
现有模型生成视频片段时,会为每个片段独立采样初始噪声(类似每次画画都用不同的“底稿”)。这种设计导致相邻片段的风格、物体细节难以衔接——例如前10秒的“红色汽车”,到11秒可能因噪声变化变成“橙色汽车”,出现明显帧间突变。
2. 独立的控制信号归一化:控制失效的关键
可控视频生成依赖外部控制信号(如深度图、关键点),但现有方法会对每个片段的控制信号“单独归一化”(例如片段1的“深度值0-100”对应“近-远”,片段2的“深度值0-50”也对应“近-远”)。这种不一致会导致控制信号“失效”——用户想让人物保持“抬手”动作,结果因归一化标准变化,人物手臂突然下垂。
3. 单模态引导的局限性:视觉质量易退化
多数模型仅依赖单一控制信号(如仅用深度图),若该信号存在噪声或细节缺失,生成视频会出现质量问题:例如深度图模糊时,视频中的栏杆可能扭曲、水波纹会失真;同时,单模态引导易导致模型“过度依赖”该信号,忽略其他视觉细节(如颜色、纹理),引发颜色漂移。

LongVie框架:4大核心设计,破解长视频生成难题
LongVie以“自回归端到端”为基础(即前一帧生成结果指导后一帧,无需拆分多个模块),通过四大设计针对性解决上述问题:
1. 统一噪声初始化:从源头保证帧间一致性
- 设计逻辑:生成整个长视频时,所有片段共享一个“初始噪声实例”,而非为每个片段独立采样;
- 具体操作:将初始噪声作为“全局种子”,后续所有片段的生成均基于该种子衍生,就像用同一本“底稿”画完整幅画;
- 效果:相邻片段的风格、物体细节(如颜色、形状)保持统一,彻底解决“帧间突变”问题,例如1分钟视频中的“蓝色天空”全程无颜色偏移。
2. 全局控制信号归一化:让控制信号“全程有效”
- 设计逻辑:对整个视频序列的控制信号(如深度图、关键点)进行“全局统一归一化”,而非片段级归一化;
- 具体操作:计算所有帧控制信号像素值的“5%分位数”(全局最小值)与“95%分位数”(全局最大值),以此作为统一归一化边界;例如深度图中,全局0-100的深度值对应“近-远”,所有片段均遵循该标准;
- 效果:用户通过控制信号设定的动作(如人物行走轨迹)、场景布局(如桌椅位置),在1分钟视频中全程精准执行,无“控制失效”情况。
3. 多模态控制框架:用“双信号”提升视觉质量
- 设计逻辑:整合“密集控制信号”与“稀疏控制信号”,发挥两者互补优势——密集信号保证细节完整,稀疏信号保证结构稳定;
- 具体搭配:
- 密集控制信号:深度图(提供场景中每个像素的“远近”信息,确保物体空间结构准确);
- 稀疏控制信号:关键点图(标记人物关节、物体顶点等关键位置,确保动作、形状稳定);
- 注入方式:通过类似ControlNet的架构,将两种信号同时注入生成模型,避免单模态信号的局限性;
- 效果:即使单一信号存在瑕疵(如深度图局部模糊),另一信号也能补全信息,避免栏杆扭曲、水波纹失真等问题。
4. 退化感知训练策略:平衡模态贡献,防止质量失衡
- 设计逻辑:模型训练时,通过“模拟信号退化”,让模型学会平衡两种控制信号的贡献,避免过度依赖某一种;
- 具体操作:
- 特征级退化:随机缩放密集控制信号的特征表示(如让深度图部分区域特征变弱);
- 数据级退化:对控制信号应用随机模糊增强(如让关键点图边缘模糊);
- 效果:模型不会因密集信号清晰就“忽略”稀疏信号,也不会因稀疏信号稳定就“放弃”密集信号,最终生成的视频在“结构稳定性”与“细节丰富度”间达到平衡。
LongVGenBench:首个1分钟长视频基准数据集
为解决长视频生成“缺乏标准化测试数据”的问题,团队构建了 LongVGenBench 数据集,为研究提供统一评估基准:
- 规模与质量:包含100个高分辨率视频,每个视频时长均超过1分钟,避免“短片段拼接冒充长视频”;
- 场景覆盖:涵盖“现实世界”(如城市街道、自然风景)与“合成环境”(如虚拟室内、动画场景),确保测试的全面性;
- 标注信息:每个视频均附带完整的控制信号标注(深度图、关键点图)与相机轨迹数据,支持可控性评估。
测试结果:定量+定性+用户研究,全面领先现有方法
1. 定量评估:7项核心指标均居第一
在长视频生成的关键评估维度上,LongVie显著优于现有基线模型:
| 评估指标 | 表现优势 |
|---|---|
| 背景/主体一致性 | 比最优基线高18%-22%,物体位置、场景布局全程无漂移 |
| 整体/时间风格一致性 | 比最优基线高15%-19%,颜色、光影风格全程统一,无帧间突变 |
| 动态程度 | 比最优基线高10%-14%,人物、物体动作流畅,无卡顿或僵硬 |
| 时间闪烁/成像质量 | 时间闪烁频率比基线低60%,成像质量(细节清晰度)比基线高25% |
2. 用户研究:5个维度评分最高
邀请100名专业用户对生成视频进行盲评,LongVie在以下维度均获得最高评分(满分5分,LongVie平均4.2分,最优基线3.5分):
- 视觉质量(细节清晰度、无伪影);
- 提示-视频一致性(生成内容与文本提示匹配度);
- 条件一致性(生成内容与控制信号匹配度);
- 颜色一致性(全程颜色无偏移);
- 时间一致性(帧间无突变、动作流畅)。
3. 消融研究:四大设计缺一不可
通过“移除某一设计”的对比实验,验证了各核心设计的必要性:
- 移除“统一噪声初始化”:时间一致性下降40%,出现明显帧间突变;
- 移除“全局控制归一化”:控制信号失效,动作偏移率上升55%;
- 移除“多模态控制”:视觉质量下降30%,伪影(如栏杆扭曲)增多;
- 移除“退化感知训练”:模态失衡,30%视频出现细节缺失或结构混乱。
3大应用场景:从视频编辑到3D资产生成
LongVie的可控性与长时长优势,已在多个场景落地实用价值:
1. 长视频编辑:“改一帧,更全片”
传统长视频编辑需逐帧修改,效率极低;LongVie支持“编辑初始帧+自动生成一致内容”——例如修改初始帧中“人物衣服颜色”,后续1分钟视频中人物衣服颜色会全程同步更新,无需逐帧调整。
2. 动作与场景转移:“换动作,保风格”
用户可将某段视频的“动作”或“场景”转移到新视频中:例如提取“舞蹈视频”的动作关键点,让LongVie生成“同一人物在草原场景跳相同舞蹈”的1分钟视频,动作与场景均保持一致性。
3. 3D网格到视频:“无纹理,生逼真视频”
无需为3D网格添加纹理,仅通过动画化的3D网格(如虚拟人物的骨骼动画),LongVie即可生成1分钟逼真视频,将3D资产无缝集成到现实场景(如让虚拟主播在真实直播间中进行1分钟播报)。
限制与未来方向:聚焦“更快”与“更清晰”
尽管LongVie实现了1分钟可控长视频生成,但仍有两大优化方向:
- 推断速度慢:当前生成1分钟视频需约45分钟推断时间,难以满足实时需求;未来将通过模型轻量化、硬件加速(如GPU优化)减少延迟;
- 分辨率待提升:现有输出分辨率(如1080P)虽满足基准测试,但低于电影级标准(如4K);后续将探索“多阶段超分”与“高分辨率生成架构”,提升视频细节丰富度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











