你有没有想过,如果AI能根据一张照片和一段声音,就能生成一个“数字分身”,让这个分身在任何场景中说话、表演,而且声音和口型都能完美匹配,这会带来什么可能?
这正是特拉维夫大学等研究机构最新发布的 ID-LoRA 想要实现的目标。这是一个创新的音视频生成技术,它能同时保留一个人的视觉形象(长相)和声音特征(音色、语调),并让这个“数字分身”在全新的场景中自然地说话、表演。
- 项目主页:https://id-lora.github.io
- GitHub:https://github.com/ID-LoRA/ID-LoRA
- 模型:https://huggingface.co/AviadDahan
为什么要做这件事?
现有的AI技术其实已经能分别做到:用一张照片生成视频里的人物形象,或者用一段声音克隆出相似的语音。但问题是,这些方法都是“各干各的”——视频生成不管声音,声音克隆不管画面,最后把两者硬凑在一起,效果往往很生硬。
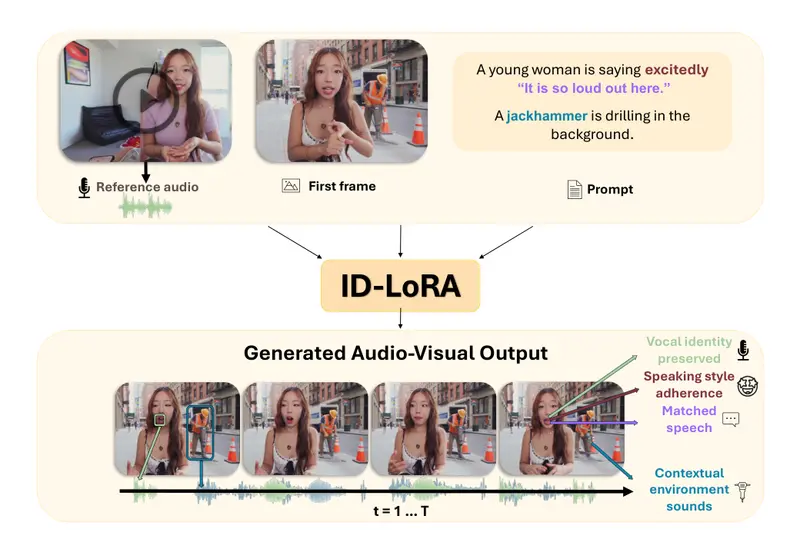
更麻烦的是,如果你想让这个数字分身在一个“嘈杂的街道上愤怒地大喊”,传统的做法会遇到大麻烦:声音克隆模型只会照搬参考音频的语气和环境(比如安静的室内、平静的语调),完全听不进你的新指令。结果就是,画面显示在街头怒吼,声音却像是在安静的房间里轻声细语,非常违和。
ID-LoRA的研究团队发现,问题的根源在于音视频分离处理。人类身份本来就是多模态的——我们认识一个人,既靠长相,也靠声音。AI生成也应该如此:画面和声音应该一起生成、相互配合,而不是先做一个再套另一个。
主要功能:ID-LoRA 能做什么?
ID-LoRA 拥有四大核心能力,重新定义了数字人的生成方式:
1. 零样本身份克隆
你只需要提供一张人物照片(作为第一帧)和一段短短的声音样本(几秒钟),ID-LoRA 就能“记住”这个人的长相和声音特征,然后在全新的场景中生成这个人的音视频。不需要针对每个人专门训练,拿来就能用(Zero-shot)。
2. 文本驱动的场景控制
你可以用文字描述想要的场景,比如:“一个年轻女性在嘈杂的街道上兴奋地说‘外面太吵了’,背景有钻机在施工”。
ID-LoRA 会同时生成匹配的画面和声音:
- 画面:人物表情兴奋、嘴型同步、背景是街道。
- 声音:带有街道的回响、背景真的有钻机声、语气兴奋。
- 关键点:文本提示同时控制了视觉内容、环境声学效果和说话风格。
3. 音视频同步生成
不同于传统的“先配音再对口型”或“先拍视频再配音”,ID-LoRA 是同时生成画面和声音的。
- 这意味着声音和口型天然对齐。
- 环境音效(如街道噪音、风声)会和画面内容协调一致,不会出现“画面在下雨,声音却很干燥”的割裂感。
4. 身份一致性与环境适应
无论你把这个人放到什么新场景——安静的图书馆、嘈杂的工地、风声呼啸的山顶——ID-LoRA 都能保持 TA 的样貌和声音特征不变,同时让声音自动适应新环境的声学特性(混响、背景音等)。
核心优势:为什么它比现有方案更强?
| 特性 | 传统级联方案 (Cascade) | ID-LoRA (统一生成) |
|---|---|---|
| 生成逻辑 | 先克隆声音 -> 再用声音驱动视频 | 音视频在统一潜在空间中联合生成 |
| 提示词控制 | 只能控制画面,声音克隆不听指令 | 提示词同时控制画面、声音风格和环境音 |
| 同步性 | 容易出现口型对不上、环境音不匹配 | 天然音画同步,物理一致性极高 |
| 训练成本 | 通常需要海量数据 | 轻量级:仅需约 3K 数据对,单卡可训 |
| 泛化能力 | 难以处理跨视频、跨场景任务 | 强泛化:可将人物移植到完全未见过的场景 |
独特亮点解析:
- 统一生成,而非拼接:传统方法像让两个人分别画左脸和右脸再拼起来,难免对不齐。ID-LoRA 是“并联”的,画面和声音在一个模型里同时诞生,天然协调。
- 提示词全能控制:在级联方案中,你说“愤怒地大喊”,视频里人物表情愤怒,声音却依然平静。ID-LoRA 让提示词同时影响两者,真正实现“说什么就有什么”。
- 物理一致性:由于是联合生成,环境音效能和画面动作对应上。比如画面中有人拍手,声音里就有清脆的拍手声;画面中有鸟儿飞过,声音里就有鸟鸣和振翅声。
工作原理:它是如何做到的?
ID-LoRA 基于强大的 LTX-2 联合音视频扩散模型构建,并引入了三项核心技术:
1. 上下文 LoRA (In-Context LoRA)
这是核心创新。LoRA 是一种“低秩适配”技术,只给模型增加少量参数。而“上下文”意味着模型把参考样本(照片和声音)当作“提示”来处理。
- 模型会将参考音频和目标音频在序列维度上“拼接”起来。
- 通过自注意力机制,模型自动学习“参考声音和目标声音来自同一个人”。
2. 负时间位置编码 (Negative Time Positional Encoding)
这是一个巧妙的设计。如果参考音频和目标音频都用正数位置,模型会混淆,以为它们是时间上的连续关系(比如前一句和后一句)。
- 解决方案:给参考音频分配**“负时间位置”**(如 -10 到 -1),而目标音频用正位置(0 到 100)。
- 效果:这就像把参考样本放在“另一个时间线”上,既保留了参考音频内部的时间结构,又明确区分了参考和目标的界限,防止模型直接复制参考音频。
3. 身份引导 (Identity Guidance)
生成过程中,模型有时会“忘记”参考声音的特征,逐渐滑向普通声音。
- 机制:模型会同时做两次预测——一次考虑参考声音,一次不考虑——然后朝着“更像参考声音”的方向调整。
- 比喻:就像有个导演在旁边时刻提醒:“记住,要模仿这个特定演员的嗓音!”
轻量级训练
令人惊讶的是,ID-LoRA 只需要约 3000 对 训练样本(而同类方法往往需要上百万),在单张显卡上训练就能达到很好的效果。这得益于它采用的参数高效微调技术,只训练少量新增参数,保留了预训练模型的大部分通用能力。
测试结果:碾压商业级产品
研究团队将 ID-LoRA 与目前的顶尖商业模型 Kling 2.6 Pro(快手可灵)以及传统的级联方案(如 CosyVoice+WAN2.2)进行了对比。
🥊 vs 商业模型 (Kling 2.6 Pro)
- 声音相似度:73% 的评估者认为 ID-LoRA 生成的声音更像参考声音。
- 风格匹配度:65% 的评估者认为 ID-LoRA 更好地遵循了提示词描述的风格(如愤怒、兴奋)。
- 跨环境能力:在参考音频和目标场景差异巨大时,ID-LoRA 的说话人相似度比 Kling 高出 24%。
🥊 vs 级联方案 (CosyVoice/WAN2.2 等)
- 唇形同步:同步误差更低,置信度更高。
- 环境音生成:能更好地按照文本描述生成环境音效(级联方案通常只能生成干净语音,无法生成背景音)。
- 物理交互:在生成“拍手”、“敲鼓”、“玻璃破碎”等需要音画精确对应的任务中,ID-LoRA 完胜,因为它理解声音和画面的物理联系。
🔍 有趣发现:传统的人脸相似度指标(ArcFace)有时会产生误导。ID-LoRA 虽然在该指标上分数略低,但实际上它的唇部动作更丰富、更自然,语音可懂度也更好。这证明评估数字人不能只看“静态像不像”,更要看“动态自不自然”。
⚠️ 伦理与未来
当然,这项技术也带来了深度伪造 (Deepfake) 的风险。研究团队建议采取水印标记、来源追溯、明确授权等防护措施,强调技术应用于合法、有益的场景(如影视制作、虚拟助手、教育)。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...