麻省理工学院、英伟达和浙江大学的研究人员联合推出了一项突破性技术——TriAttention。这是一种基于三角级数(Triangular Series)的 KV 缓存压缩方法,解决大型语言模型(LLM)在长上下文推理中的内存瓶颈问题。
- 项目主页:https://weianmao.github.io/tri-attention-project-page
- GitHub:https://github.com/WeianMao/triattention
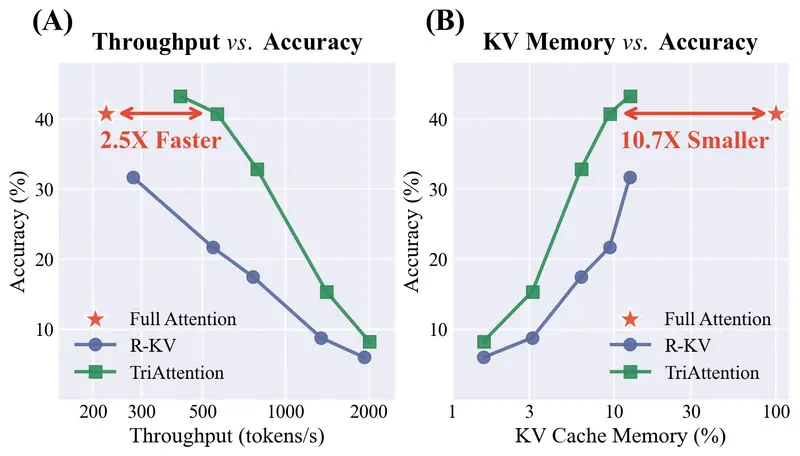
通过利用 RoPE(旋转位置编码)前空间中 Q/K 向量的集中性(Concentration)特性,TriAttention 能够以极低的计算成本精准预测键(Key)的重要性,从而实现10.7 倍的内存节省和2.5 倍的吞吐量提升,且几乎不损失推理准确率。
核心突破:从“内存溢出”到“流畅推理”
在消费级硬件上运行大参数模型一直是个难题。TriAttention 展示了惊人的优化效果:
- 10.7 倍内存减少:在 AIME25 基准测试中,KV 缓存占用大幅降低,使得原本因内存不足(OOM)而崩溃的任务得以顺利完成。
- 2.5 倍吞吐量提升:在保持相同准确率(40.8%)的前提下,推理速度显著加快。
- 6.3 倍峰值加速:在 MATH 500 基准上,TriAttention 达到 1,405 tokens/秒,而全注意力机制仅为 223 tokens/秒。
- 实战案例:在 24GB GPU 上运行 OpenClaw + 32B 模型。由于 OpenClaw 默认指令冗长,传统全注意力机制会导致启动即 OOM;引入 TriAttention 后,智能体能够顺利加载并完成任务。
技术原理:为什么 TriAttention 更有效?
传统的 KV 缓存压缩方法通常依赖 RoPE 后 的近期查询(Query)来估计 Key 的重要性。然而,RoPE 会导致查询向量随位置旋转,使得只有极小窗口的查询具有代表性,容易导致关键信息被错误驱逐。
TriAttention 另辟蹊径,转向 RoPE 前空间,发现了两个关键现象:
1. Q/K 集中性 (Q/K Concentration)
在 RoPE 之前,大多数注意力头的 Q 和 K 向量高度集中在固定的非零中心附近。这种集中性在不同位置和输入上下文中非常稳定,是模型的内在属性,不受位置旋转干扰。
2. 距离偏好可预测 (Predictable Distance Preference)
当 Q/K 集中时,注意力分数可以简化为关于 Q-K 距离 的三角级数。这意味着,通过学习到的中心,模型可以预先知道每个头偏好关注哪些距离的 Key。
TriAttention 的工作流程
TriAttention 结合两种信号对 Key 进行评分,决定保留或丢弃:
- 三角级数分数 (Triangular Series Score):
- 利用离线校准得到的 Q 中心和三角级数,预测每个 Key 在其当前距离上应获得的注意力。
- 捕获了由 Q/K 集中性编码的距离偏好。
- 基于范数的分数 (Norm-based Score):
- 针对少数 Q/K 集中性较低的头,作为补充信号。
- 通过期望查询贡献对频带加权,处理中心周围的偏差。
- 自适应权重 (Adaptive Weighting):
- 使用平均合成长度 $R$ 自动平衡上述两部分。
- 集中性高时,三角级数主导;集中性低时,范数分数补充。
性能对比:碾压主流基线
| 指标 | TriAttention | 全注意力 (Full Attention) | 主流基线 (如 StreamingLLM 等) |
|---|---|---|---|
| KV 内存占用 | ↓ 10.7 倍 | 1x (基准) | ~5-6 倍减少 |
| 推理吞吐量 | ↑ 2.5 倍 | 1x (基准) | ~1.2-1.5 倍 |
| AIME25 准确率 | 40.8% | 40.8% | ~20-25% (效率相当时) |
| MATH 500 速度 | 1,405 tok/s | 223 tok/s | - |
| MATH 500 准确率 | 68.4% | 69.6% | - |
关键结论:在相同的压缩效率下,主流基线方法的准确率往往只有 TriAttention 的一半左右。TriAttention 实现了**“鱼与熊掌兼得”**——既快又省,还准。
适用场景与价值
- 边缘设备部署:让 32B 甚至更大参数的模型能在消费级显卡(如 RTX 3090/4090, 24GB VRAM)上运行长上下文任务。
- 长文档/代码分析:在处理数万 token 的代码库或法律文档时,显著降低显存峰值,避免 OOM。
- 高并发服务:在服务端,更高的吞吐量意味着单卡能支持更多并发用户,大幅降低推理成本。
- 智能体工作流:如 OpenClaw 等带有复杂系统提示的智能体框架,能从 TriAttention 的内存优化中直接受益,实现更稳定的长期记忆管理。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











