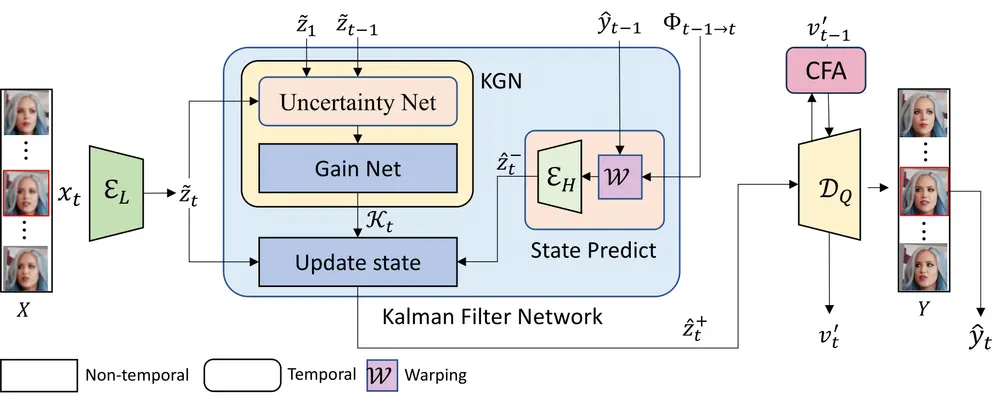
Stability AI于北京时间2023年11月22日推出AI视频生成模型 Stable Video Diffusion,Stable Video Diffusion 由两个模型组成的 ——SVD 和 SVD-XT。SVD 可以将静态图片转化为 14 帧的 576×1024 的视频。SVD-XT 使用相同的架构,但将帧数提高到 24。两者都能以每秒 3 到 30 帧的速度生成视频。

在官方的论文中,表示Stable Video Diffusion(SVD)是一种潜在的视频扩散模型,用于高分辨率、最先进的文本到视频和图像到视频生成。SVD通过在大规模视频数据集上进行系统的数据选择和缩放研究,构建了其预训练数据集,并提出了一种方法将大量且嘈杂的视频数据转化为适合生成视频模型的数据集。此外,论文还介绍了三个不同的视频模型训练阶段,分别分析了它们对最终模型性能的影响。
视频模型训练的三个阶段:
- 第一阶段:图像预训练:基于预训练的图像扩散模型,为视频模型提供强大的视觉表示。
- 第二阶段:视频预训练:在大规模视频数据集上进行预训练,以提高视频质量。
- 第三阶段:高质量微调:在高分辨率视频数据集上进行微调,以进一步提高视频质量。
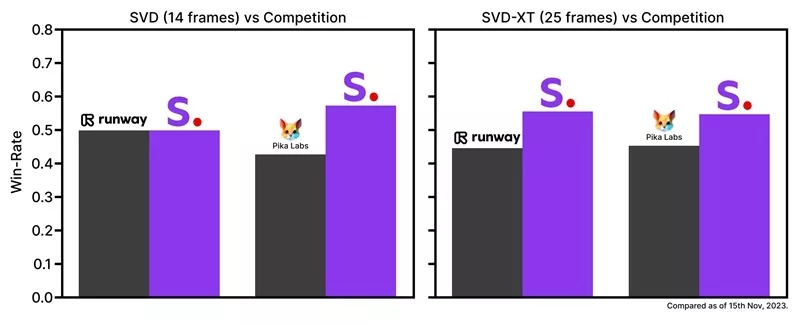
Stable Video Diffusion 源代码采用 MIT License 发布在 GitHub 上,模型发布在 Hugging Face 上。Stable Video Diffusion 基于 Stable Diffusion,有两种输出形式,能以每秒 3-30 帧的定制帧速生成 14 和 25 帧。Stability AI 称其模型的表现好于私有模型。
开源地址:https://github.com/Stability-AI/generative-models
模型地址:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt
Stable Video Diffusion (SVD) 模型在2月3日晚间发布1.1版,与前一代相比,主要变化包括:
- 微调优化:通过特定条件下的微调,提高了视频输出的一致性和质量。
- 改进的生成性能:在生成视频的清晰度、分辨率以及帧数上可能有所改进,提供更加流畅和高质量的视觉体验。
- 固定条件下的性能提升:通过在固定条件下进行微调,SVD 1.1在特定设置下展现出比先前版本更优的性能,这包括更好的运动一致性和视觉效果,同时保持了条件的可调整性,以适应不同的应用需求。
- 适应性和局限性:SVD 1.1继续探索模型的适应性和局限性,鼓励负责任使用。
下载地址:https://huggingface.co/stabilityai/stable-video-diffusion-img2vid-xt-1-1
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











