
OmniWeaving 是由 腾讯混元、浙江大学 和 南洋理工大学的研究人员推出的基于HunyuanVideo-1.5的视频生成模型。它填补了开源社区与闭源顶尖系统(如 Seedance-2.0)之间的巨大鸿沟,成为首个真正意义上全能级(All-in-One)的开源视频生成框架。
- 项目主页:https://omniweaving.github.io
- GitHub:https://github.com/Tencent-Hunyuan/OmniWeaving
- 模型:https://huggingface.co/tencent/HY-OmniWeaving
OmniWeaving 不仅支持文字、图片、视频的自由混合输入,更引入了独特的“思考模式”,使其能够理解模糊指令、推理复杂意图,并生成逻辑连贯、画面精美的视频。与此同时,研究团队发布了 IntelligentVBench,这是业界首个专门用于评估下一代智能统一视频生成的综合基准。
核心突破:从“被动执行”到“主动推理”
传统的视频生成模型通常是“单任务专家”(要么文生视频,要么图生视频),且只能机械地执行指令。OmniWeaving 通过两大创新架构改进,实现了质的飞跃:
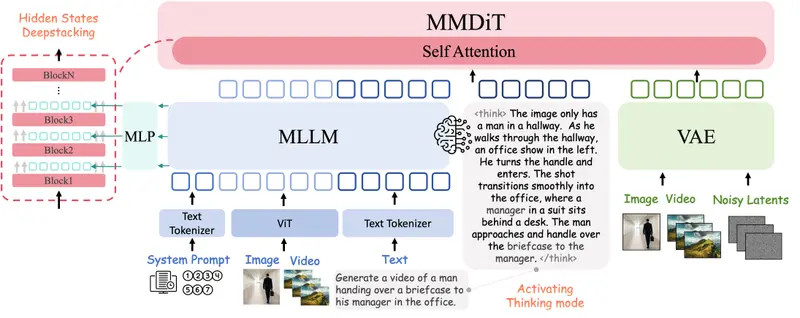
1. 激活 MLLM 的“思考模式” (Thinking Mode)
- 痛点:直接使用多模态大语言模型(MLLM)编码输入,往往因意图不明确导致生成结果语义模糊。
- 解决方案:将 MLLM 从被动的特征提取器升级为主动推理器。
- 在生成视频前,模型会先进行中间推理步骤,自主推导出语义精确的增强提示(Enhanced Prompt)。
- 这些推理后的隐藏状态与原始特征一起,作为条件注入到生成模型中。
- 效果:有效弥合了抽象用户意图(如“做一个悲伤的结局”)与像素级生成之间的认知鸿沟。
2. 隐藏状态深度堆叠 (Deep Stacking of Hidden States)
- 痛点:复杂的组合视频生成(涉及多主体、多场景)需要同时兼顾细粒度细节和高级抽象语义。
- 解决方案:受 Qwen3-VL 启发,从 MLLM 的多个中间层提取隐藏状态。
- 利用 MLP 连接器将这些多粒度特征投影到生成模型(MMDiT)的嵌入空间。
- 直接注入到 MMDiT 条件分支的前三个层中。
- 效果:让生成过程同时受到“微观细节”和“宏观逻辑”的双重指导,确保拼接自然、逻辑自洽。

全能功能全景
OmniWeaving 基于 MLLM + MMDiT + VAE 的统一架构,实现了真正的自由形式组合:
| 功能类别 | 具体能力 | 示例场景 |
|---|---|---|
| 基础生成 | 文生视频 (T2V)、图生视频 (I2V) | 输入一段描述或一张图,生成动态视频。 |
| 多模态拼接 | 自由混合输入 | 输入“文字 + 多张关键帧 + 参考视频片段”,合成全新故事。 |
| 视频编辑 | 精细修改 | 替换背景、改变风格、增删物体、添加字幕。 |
| 推理式创作 | 模糊指令理解 | 输入“让这个角色看起来更孤独”,模型自动推理光影、动作和氛围并生成。 |
| 长程连贯 | 多镜头叙事 | 基于多张图片生成连贯的多镜头视频序列。 |
一句话总结:无论是给一句话、几张图、一段视频,还是混合起来的模糊要求,OmniWeaving 都能像人类导演一样“脑补”出完整剧本,并拍摄成流畅的视频。
性能表现:开源界的 SOTA
研究团队构建了 IntelligentVBench 基准,对模型进行了严格测试。结果显示:
- 开源第一:在所有开源统一视频生成模型中,OmniWeaving 取得了最先进性能 (SOTA)。
- 均衡全面:在基础生成、多图拼接、视频编辑、推理创作等所有子任务上表现稳定,无明显的短板。
- 推理增益显著:开启“思考模式”后,在模糊指令和复杂逻辑任务上的生成质量大幅提升。
- 媲美专用模型:即使在单一任务(如纯文生视频)上,其表现也接近甚至超过那些只专注于该任务的专用模型。
技术架构详解
OmniWeaving 的工作流可以概括为 “先理解思考,再分层生成”:
- 语义解析 (MLLM):
- 接收交错的文本、图像、视频输入。
- 思考阶段:生成中间推理步骤,输出增强提示。
- 特征提取:从多层提取隐藏状态,覆盖从细节到抽象的全谱系语义。
- 视觉分词 (VAE):
- 将视觉输入压缩为低级潜变量 (Latent Variables)。
- 视频生成 (MMDiT):
- 接收来自 MLLM 的多粒度语义条件。
- 结合潜噪声,逐步去噪生成高保真、语义对齐的视频帧。
为什么 OmniWeaving 至关重要?
- 打破闭源垄断:此前,具备强大组合与推理能力的视频生成技术仅掌握在少数闭源巨头手中。OmniWeaving 的开源让全球开发者都能接触到这一前沿能力。
- 统一工作流:不再需要在多个工具间切换(一个做 T2V,一个做 I2V,一个做编辑)。一个模型搞定所有视频创作需求。
- 智能创作新范式:引入了“推理”概念,让 AI 从简单的“执行者”变成了具备一定“导演思维”的创作者,能够处理更具创意和模糊性的需求。
- 评测标准建立:IntelligentVBench 的发布为未来视频生成模型的发展提供了明确的衡量标尺。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...





