
在文本到图像生成领域,如何实现对多个主体身份和语义属性(如姿势、风格、照明)的细粒度控制,同时保持高质量和一致性,一直是一个极具挑战性的问题。
传统方法往往存在以下问题:
- 在多主体场景中容易引入视觉伪影
- 属性之间出现纠缠,难以独立调节
- 生成质量下降,尤其是在复杂组合场景下
为了解决这些问题,字节跳动研究团队提出了 XVerse ——一种全新的多主体可控图像生成模型。它通过创新的文本流调制机制,实现了对多个主体身份和语义特征的精确且独立控制,而无需修改图像潜在变量或特征空间。
- 项目主页:https://bytedance.github.io/XVerse
- GitHub:https://github.com/bytedance/XVerse
- 模型:https://huggingface.co/ByteDance/XVerse

✅ XVerse 的核心优势
| 特性 | 描述 |
|---|---|
| 多主体控制 | 可同时编辑多个主体的身份与属性 |
| 高保真图像合成 | 保持与原始扩散模型相当的画质与编辑能力 |
| 语义属性控制 | 精确调整姿势、风格、光照等细节 |
例如,在生成“一个穿着蓝色衬衫的男人和一只金毛犬在公园里散步”的场景时,XVerse 能够分别控制男人的服装、姿态,以及狗的品种和动作,确保整体画面自然连贯。
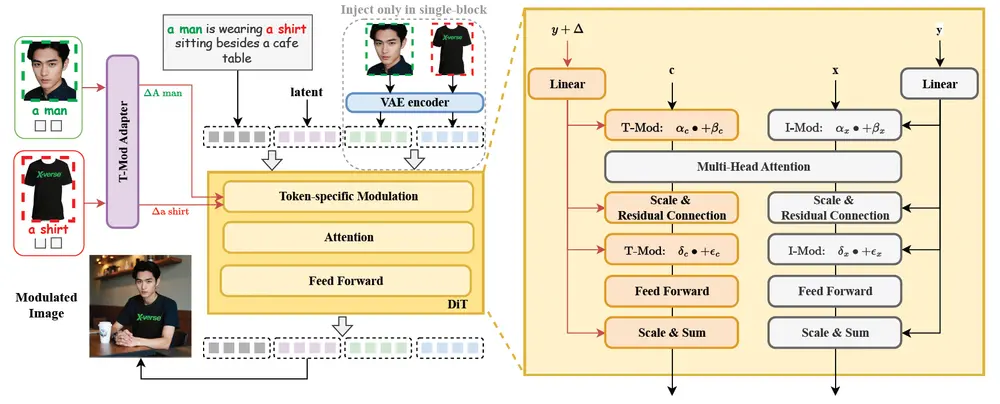
🔍 技术原理:基于 DiT 的文本流调制机制
XVerse 的核心技术基础是**扩散变换器(DiT)**中的文本流调制机制。其核心思想是将参考图像转换为特定于令牌的偏移量,并将其注入到扩散模型的文本嵌入空间中,从而实现对目标属性的精准控制。
核心组件解析
1. T-Mod 适配器(Text Modulation Adapter)
🔹 使用感知重采样器作为文本流调制适配器
🔹 结合 CLIP 编码的图像特征和文本提示特征,生成交叉偏移量
🔹 实现特定于令牌的文本流调制,使模型能够区分并独立控制不同主体
数学表达如下:
T-Mod(I_ref, T) → Δ_shared, {Δ_block_i}其中:
I_ref是参考图像T是文本提示Δ_shared是共享偏移量{Δ_block_i}是每个 DiT 块的特定偏移量
2. 文本流调制机制
🔹 将参考图像编码为文本流偏移量
🔹 将这些偏移量添加到对应的文本嵌入中
🔹 动态调整原始调制参数(缩放和位移),实现对特定主体的精细操作
这一机制使得 XVerse 能够在不破坏图像结构的前提下,对多个主体进行独立编辑。
3. VAE 编码图像特征模块
🔹 引入 VAE 编码的图像特征作为辅助输入
🔹 增强图像细节表现力,提升真实感
🔹 减少直接注入图像特征可能带来的失真或伪影
该模块有效提升了生成图像的质量,特别是在处理复杂纹理和背景时表现出色。
4. 正则化技术优化解耦性能
为进一步提升模型的稳定性和控制精度,XVerse 引入了两种关键正则化策略:
- 区域保留损失(Region Preservation Loss)
通过单侧随机保留调制注入,强制非调制区域保持一致,避免全局扰动影响未指定部分。 - 文本-图像注意力损失(Text-Image Attention Loss)
对齐调制模型与原始文本到图像分支之间的交叉注意力动态,确保语义一致性。
📊 训练数据构建与评估基准
数据构建流程
XVerse 的训练数据集采用自动化流程构建,结合多个先进视觉模型:
- Florence2:用于图像描述和短语定位
- SAM2:用于精确提取面部和物体区域
- 构建包含多人、多物、多动物的高质量多主体控制数据集
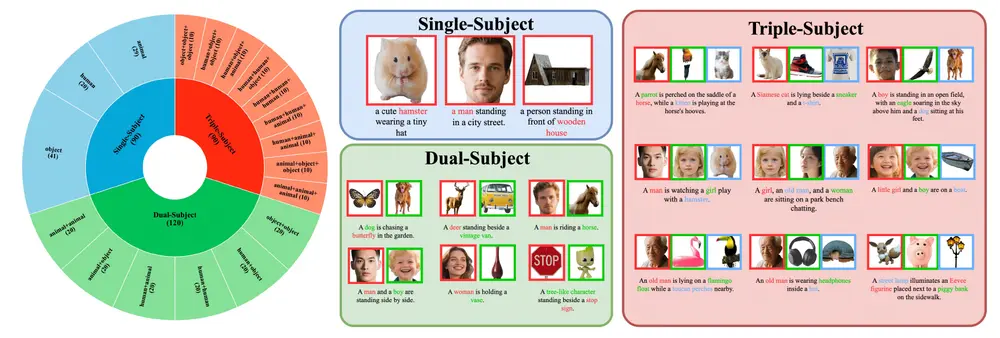
XVerseBench:多主体控制图像生成评估基准
为了系统评估 XVerse 的多主体控制能力,研究团队构建了专门的测试集——XVerseBench,其特点包括:
| 类别 | 数量 |
|---|---|
| 人类身份 | 20 个 |
| 物体种类 | 74 个 |
| 动物个体 | 45 个 |
| 总测试提示 | 300 条 |
支持多种控制场景:
- 单主体控制
- 双主体控制
- 三主体控制
评估指标
| 指标 | 含义 |
|---|---|
| DPG 分数 | 衡量编辑能力和控制精度 |
| 面部身份相似性 | 衡量人物身份保留程度 |
| DINOv2 相似性 | 衡量物体特征匹配度 |
| 美学分数 | 衡量图像美学质量 |
实验结果表明,XVerse 在各项指标上均显著优于现有方法,尤其在多主体控制场景下展现出更强的稳定性与可控性。

🧪 应用演示与效果展示
单主体控制
XVerse 可以仅对一个主体进行高保真编辑,例如:
- 改变服装款式与颜色
- 调整面部表情或发型
- 控制光照方向与强度
所有更改均不影响图像中其他元素,保证了编辑的局部性与一致性。
多主体控制
这是 XVerse 的最大亮点之一。它可以同时控制多个主体的身份和属性,例如:
- 在一张图片中分别控制两个角色的服饰和姿态
- 同时指定猫和狗的动作与品种特征
- 在复杂场景中独立控制人、车、建筑等多个对象的风格与位置
这种能力极大拓展了个性化图像生成的应用边界。
语义属性控制
除了主体身份,XVerse 还能对以下语义属性进行细粒度控制:
- 光照角度与亮度
- 主体姿态变化
- 整体艺术风格(如写实、卡通、油画风)
- 场景氛围(如白天/夜晚、雨天/晴天)
这种控制方式无需额外训练特定属性的数据集,只需提供参考图像即可完成编辑。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











