在图像生成模型多依赖“大参数堆料”的行业趋势下,阿里通义MAX项目组推出的Z-Image,以60亿参数的轻量化体量实现了颠覆性突破。这款通过系统性优化打造的图像生成基础模型,不仅在照片级真实感生成、中英双语文本渲染等核心场景中比肩顶级商业模型,更通过架构创新与蒸馏技术,将部署门槛压低至16G显存的消费级设备。
- 项目主页:https://tongyi-mai.github.io/Z-Image-blog
- GitHub:https://github.com/Tongyi-MAI/Z-Image
- 模型:Hugging Face | 魔塔
- Demo:Hugging Face | 魔塔
目前,其衍生的Z-Image-Turbo(图像生成)模型已开放代码、权重及在线Demo,为社区提供了兼具普惠性、低成本与高性能的生成式AI解决方案。
三大模型变体:覆盖从基础研发到场景落地的全需求
Z-Image构建了完整的模型矩阵,不同变体精准匹配开发者、研究者与创作者的差异化需求:
| 模型变体 | 核心定位 | 核心优势 |
|---|---|---|
| Z-Image-Turbo | 高效图像生成旗舰 | 蒸馏版本,8次NFEs(函数评估次数)即可达行业领先水平;H800 GPU亚秒级推理,16G显存消费级设备适配;擅长逼真生成、中英双语文本渲染与精准指令遵循 |
| Z-Image-Base | 基础研发与微调底座 | 非蒸馏原始模型,保留完整能力与调优空间,支持社区二次开发与定制化训练 |
| Z-Image-Edit | 创意图像编辑专项 | 图生图任务微调,双语指令深度理解,支持灵活精准的图像变换与创意修改 |



核心技术:单流架构撑起“轻量化+高性能”平衡
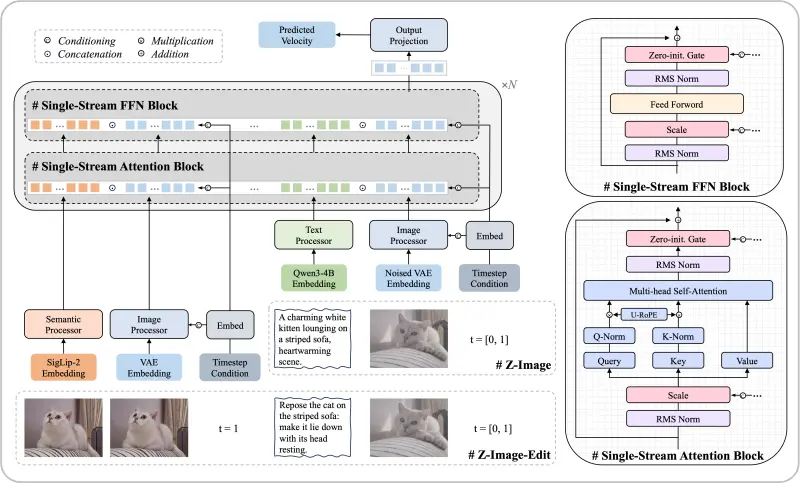
Z-Image的突破核心源于创新的可扩展单流DiT(S3-DiT)架构,从根源上解决了传统模型参数冗余、效率不足的痛点:
- 统一输入流提升参数效率:区别于传统双流方法,该架构将文本信息、视觉语义标记、图像VAE标记在序列级别串联,形成单一输入流送入Transformer主干网络。这种设计实现了多模态信息的深度融合,避免了信息割裂,在60亿参数规模下实现了远超同级别模型的性能,最大化参数利用率;
- 提示增强器强化推理能力:搭载专属提示增强模块,模型不仅能执行表面文本描述,还能挖掘世界知识进行逻辑推理。例如面对“暴雨后清晨的城市街道,积水倒映霓虹灯光,行人撑伞慢行”的指令,可精准还原光影反射、场景氛围与物体交互逻辑;
- 蒸馏技术降低部署门槛:Z-Image-Turbo通过蒸馏优化,在大幅减少推理NFEs(仅8次)的同时,保持生成质量不打折。这一优化让模型既能在企业级GPU上实现极速推理,也能适配普通消费级显卡,打破了高性能生成对高端硬件的依赖。
核心能力:兼顾逼真度与实用性,适配多场景需求
凭借技术优化与专项训练,Z-Image系列在核心场景中展现出顶尖实力,解决了传统模型的诸多痛点:
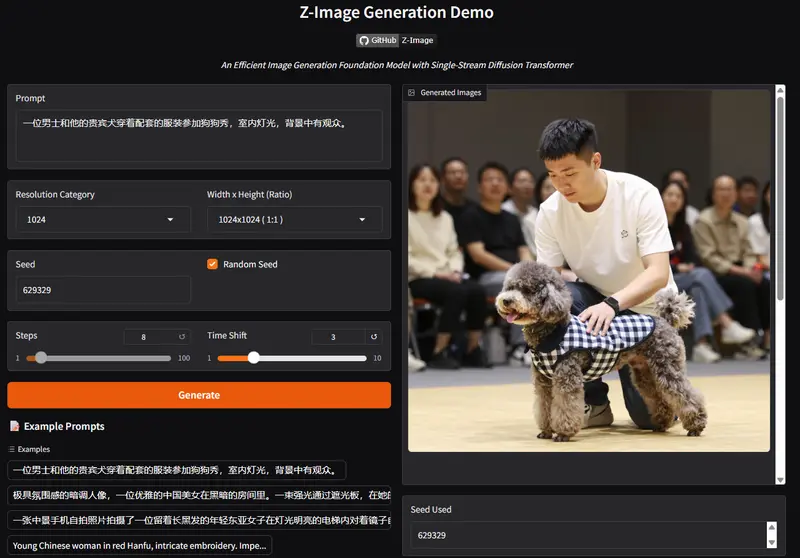
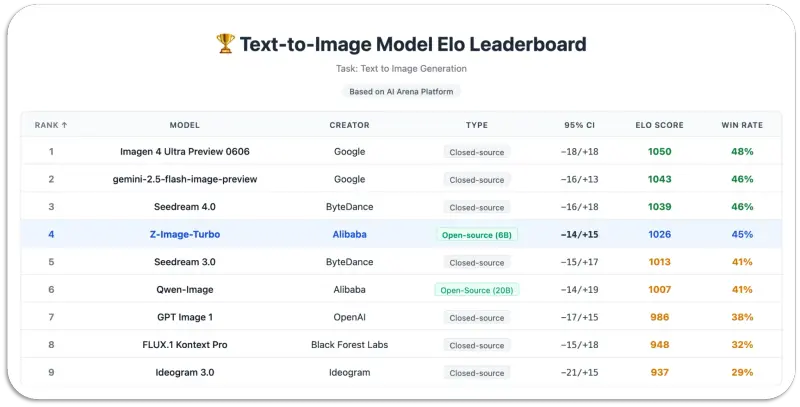
- 照片级真实感生成:在AI Arena的Elo人类偏好评估中,Z-Image-Turbo展现出与行业领先模型比肩的竞争力,开源模型中处于顶尖水平。生成图像的色彩、纹理、空间透视均贴合现实规律,可直接用于产品渲染、场景复原、商业海报等高精度需求;
- 高精度中英双语文本渲染:攻克AI生成文本“失真、难识别”的行业痛点,能精准渲染复杂中英文文本——无论是海报艺术字、场景标识,还是文档规整文字,都能清晰呈现,大幅减少后期手动修正成本;
- 灵活可控的创意编辑:Z-Image-Edit具备强大的双语指令理解能力,支持“局部修改+全局保留”的精准编辑。例如输入“将图中红色跑车改为复古老爷车,保持背景草原与日落场景不变”,可精准定位编辑对象,不破坏画面整体协调性,适配设计迭代、内容二次创作等场景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...