在图像检测与分割领域,高质量的专用模型往往能显著提升下游任务的表现。开发者 Anzhc 基于自建标注数据集,训练并开源了一系列面向特定视觉任务的 YOLO 模型,涵盖面部、眼部、头部、胸部等细粒度目标的检测与分割,以及动漫艺术评分、无人机识别等特殊场景应用。
这些模型多数基于 YOLOv8 和 YOLOv11 架构,在精度与效率之间取得良好平衡,并已在实际项目中验证可用性(如用于 Adetailer 扩展)。所有模型均已公开下载链接,适合图像修复、内容生成、自动标注等场景使用。
模型概览
| 类别 | 主要功能 | 典型应用场景 |
|---|---|---|
| 面部分割 | 精确识别人脸区域(含插画与真实) | 图像修复、虚拟人像处理 |
| 眼部分割 | 定位动漫眼睛(眼白区域) | Adetailer 眼部增强 |
| 头部+头发分割 | 检测完整头部及发部轮廓 | 肖像自动化处理 |
| 胸部分割 | 动漫角色胸部区域分割 | 内容生成辅助 |
| 胸部大小分类 | 检测并分级胸部尺寸 | 内容标签、审核系统 |
| 无人机检测 | 识别空中飞行器 | 特殊场景监控(实验性) |
| 动漫艺术评分 | 根据人类偏好预测作品受欢迎程度 | 数据筛选、推荐系统 |
所有模型均基于开发者亲自标注或协作完成的数据集训练,非公开数据集。基于公开数据集的模型将单独说明。
👁️ 面部与眼部专用模型
面部分割(通用)
适用于插画与真实人脸的高精度分割任务,支持多种分辨率输入。
| 模型名称 | mAP50(框/掩码) | mAP50-95(框/掩码) | 数据量 | 分辨率 |
|---|---|---|---|---|
| Anzhc Face seg 640 v2 y8n.pt | 0.791 / 0.765 | 0.608 / 0.445 | ~500 | 640 |
| Anzhc Face seg 768MS v2 y8n.pt | 0.807 / 0.770 | 0.601 / 0.432 | ~500 | 768 |
| Anzhc Face seg 1024 v2 y8n.pt | 0.768 / 0.740 | 0.557 / 0.394 | ~500 | 1024 |
| Anzhc Face seg 640 v3 y11n.pt | 0.882 / 0.871 | 0.689 / 0.570 | ~660 | 640 |
📌 更新说明:
- v3 版本优化了眉毛与完整睫毛的标注目标,更适合 Adetailer 使用;
- 从 v3 起转向 YOLOv11 架构,相比 v8 有明显提升;
- YOLOv12 当前未见显著收益且训练耗时增加 50%,暂不采用。

真实面部(按性别分类)
专为真实人像设计,支持性别区分,可用于构建男女检测堆栈。
| 模型名称 | mAP50(框/掩码) | mAP50-95(框/掩码) | 数据量 | 分辨率 |
|---|---|---|---|---|
| Anzhcs ManFace v02 1024 y8n.pt | 0.883 / 0.883 | 0.778 / 0.704 | ~340 | 1024 |
| Anzhcs WomanFace v05 1024 y8n.pt | 0.820 / 0.820 | 0.713 / 0.659 | ~600 | 1024 |
⚠️ 注意:该系列对插画类图像表现较弱,建议仅用于真实照片场景。

眼部分割
专为动漫图像设计,聚焦于眼白区域检测,不包含睫毛和外部轮廓,适用于精细化眼部修复。
| 模型名称 | mAP50(框/掩码) | mAP50-95(框/掩码) | 数据量 | 分辨率 |
|---|---|---|---|---|
| Anzhc Eyes -seg-hd.pt | 0.925 / 0.868 | 0.721 / 0.511 | ~500 | 1024 |
💡 提示:当前数据集经历多次重构,未来版本将进一步扩展样本多样性。

💇 头部与头发分割
早期开发的实用模型之一,可用于自动化肖像处理流程。
| 模型名称 | mAP50(框/掩码) | mAP50-95(框/掩码) | 数据量 | 分辨率 |
|---|---|---|---|---|
| Anzhc HeadHair seg y8n.pt | 0.775 / 0.777 | 0.576 / 0.552 | ~3180 | 640 |
| Anzhc HeadHair seg y8m.pt | 0.867 / 0.862 | 0.674 / 0.626 | ~3180 | 640 |
✅ 支持插画与真实图像,y8m 表现更优,适合高精度需求场景。

🫀 胸部相关模型
胸部分割(动漫)
仅基于动漫图像训练,专注于胸部区域的精确分割。
| 模型名称 | mAP50(框/掩码) | mAP50-95(框/掩码) | 数据量 | 分辨率 |
|---|---|---|---|---|
| Anzhc Breasts Seg v1 1024n.pt | 0.742 / 0.730 | 0.563 / 0.535 | ~2000 | 1024 |
| Anzhc Breasts Seg v1 1024s.pt | 0.768 / 0.763 | 0.596 / 0.575 | ~2000 | 1024 |
| Anzhc Breasts Seg v1 1024m.pt | 0.782 / 0.775 | 0.644 / 0.614 | ~2000 | 1024 |
📌 m 版本表现最佳,适合高保真生成任务。

胸部大小检测与分类
一个创新性的多分类模型,用于识别动漫角色胸部尺寸,共 15 个等级,基于身体比例而非画面比例进行标注,避免巨型化或缩放带来的误判。
| 模型名称 | 类别数 | 数据量 | 分辨率 |
|---|---|---|---|
| Anzhcs Breast Size det cls v8 y11m.pt | 15(含“不可测量”类) | ~16,100 | 640 |

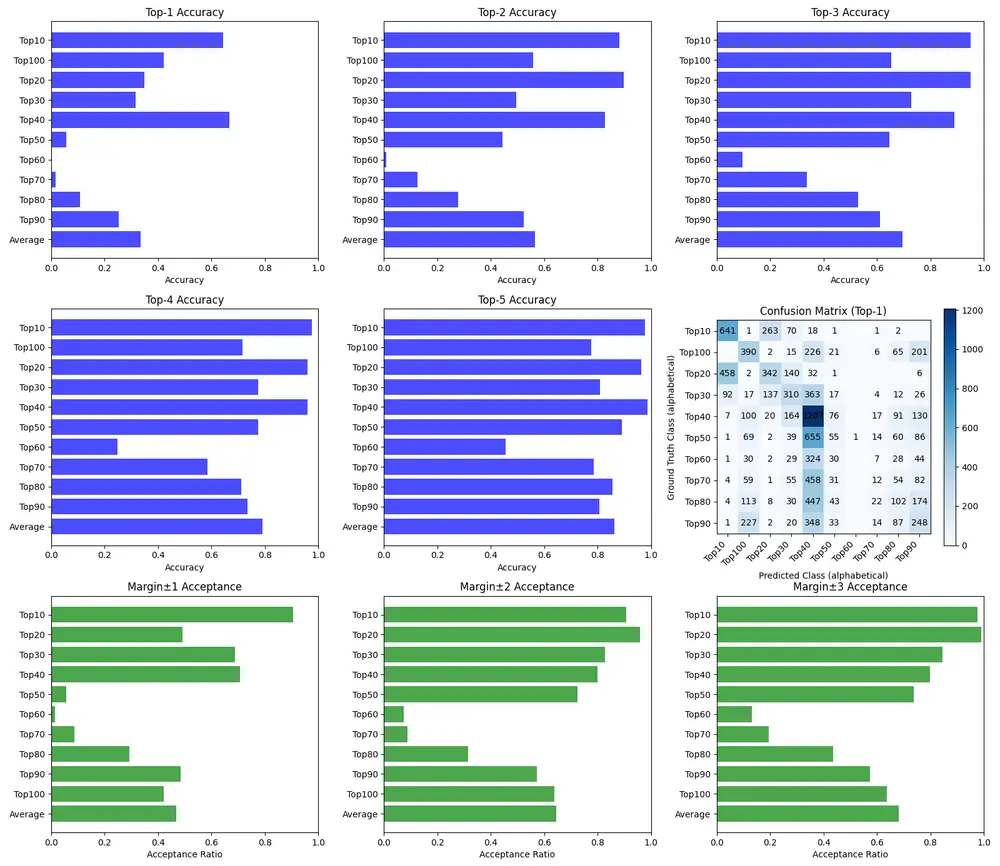
📊 评估指标说明:
由于分类任务复杂,传统 mAP 不足以反映性能,采用以下多维度评估:
- 准确率(Exact Match):预测完全正确的比例
- ±1 / ±2 可接受误差比率:允许小幅偏差,更贴近实际使用
- 漏检率:应检测但未检出
- 假阳性率:错误检测不存在的目标
- 误分类率:检测到目标但类别错误
🔍 关键发现:
- 极端类别(平胸或超大)检测难度较高;
- 中等尺寸(2级)最易混淆,主要与1级混淆;
- 多数常见尺寸分类准确率可达 70%–90%;
- 平均误分类率约 3%,整体可控;
- “不可测量”类用于处理遮挡或部分出框情况。
📌 该模型可用于内容标签系统或审核流程,但需注意其主观性——所有标注均由单一标注者完成。
🛰️ 无人机检测模型
一个实验性项目,用于检测空中无人机,基于约 3,460 张图像训练。
| 模型名称 | mAP50(框/掩码) | mAP50-95(框/掩码) | 数据量 | 分辨率 |
|---|---|---|---|---|
| Anzhcs Drones v03 1024 y11n.pt | 0.927 / 0.888 | 0.753 / 0.508 | ~3460 | 1024 |
⚠️ 重要提示:
- 对无人机型号敏感,某些类型(尤其是近距离)难以稳定检测;
- 在复杂背景中表现下降;
- 不建议用于严肃或安全关键场景。
🎯 该项目为个人兴趣驱动,展示了 YOLO 在非主流目标上的可行性。

🎨 动漫艺术评分模型
一个独特的分类模型,尝试从图像特征中预测人类偏好评分。数据来源于 Danbooru,筛选出 约 9.8 万张 经充分曝光且评分稳定的图像,按评分分为 10 个百分位组(top10 到 top100)。
| 模型名称 | Top-1 准确率 | Top-3 准确率 | 类别数 | 分辨率 |
|---|---|---|---|---|
| Anzhcs Anime Score CLS v1.pt | 0.336 | 0.696 | 10 | 224 |
📊 允许 ±1/±2/±3 类别误差的扩展准确率:
- ±1:46.7%
- ±2:64.5%
- ±3:67.9%
🧠 研究洞察:
- Top10–Top40 区间存在较强相关性,表明高质量作品具有可学习的视觉特征;
- Top60 准确率接近随机(~10%),说明“中庸艺术”缺乏统一特征;
- Top80–Top100(低分)有一定负相关性,可识别出明显缺陷;
- NSFW 内容整体评分偏高,与普遍认知相反,但数据集中 NSFW/SFW 比例约为 50/50,排除偏差干扰;
- 更大模型测试未带来明显提升,推测当前架构已达瓶颈。
📌 结论:可以较好预测“好”与“差”的作品,但难以判断“普通”作品。因此,该模型更适合用于筛选优质内容,而非全面质量评估。
✅ 使用建议与注意事项
- 模型选择建议:
- 追求精度:优先选择 v3 及以上 + YOLOv11 架构;
- 兼容性要求高:可继续使用 v2 系列;
- 实时性要求高:考虑轻量级变体(如 n/s 版本)。
- 部署提示:
- 所有模型均为
.pt格式,兼容 Ultralytics YOLO 推理框架; - 建议在 GPU 环境下运行,尤其是 1024 分辨率模型;
- 可与 Adetailer、ControlNet 等 Stable Diffusion 扩展集成使用。
- 所有模型均为
- 伦理与合规提醒:
- 部分模型涉及敏感人体部位识别,请遵守当地法律法规;
- 不建议用于自动化审核或决策系统,需人工复核;
- 所有模型仅供研究与个人使用,商业用途请谨慎评估风险。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











