扩散模型凭借卓越的生成质量成为图像生成领域的核心技术,但40-100步的迭代去噪过程导致推理速度极慢,难以落地到实时应用场景。复旦大学与微软亚洲研究院联合提出的ArcFlow框架,通过非线性轨迹蒸馏的创新思路,仅用2步神经函数评估(NFE=2)就能实现40倍推理加速,同时几乎无损保留原始大模型的生成质量与多样性,为扩散模型的高效落地提供了全新解决方案。
核心痛点:扩散模型“慢”的根源与传统解法的缺陷
1. 扩散模型的推理瓶颈
扩散模型(如Stable Diffusion、FLUX.1-dev、Qwen-Image-20B)生成高质量图像的核心是多步顺序去噪:从随机噪声出发,通过40-100步逐步去除噪声、逼近目标图像。这种“慢工出细活”的方式虽然保证了质量,但每一步都需要神经网络前向计算,推理耗时极长,无法满足实时生成(如移动端、直播特效)的需求。
2. 传统蒸馏方法的致命问题
现有加速方案(如Lightning、pi-Flow、TwinFlow)均采用线性捷径蒸馏:试图用“直线”近似教师模型(原始多步扩散模型)的复杂去噪轨迹。但教师模型的去噪速度场(轨迹切线方向)会随时间步动态变化,线性近似必然导致“几何失配”——就像用折线拟合曲线,步数越少,偏差越大,最终表现为生成图像模糊、细节丢失、模式坍塌(多样性下降)。
ArcFlow核心创新:用“动量驱动的非线性轨迹”精准复刻教师行为
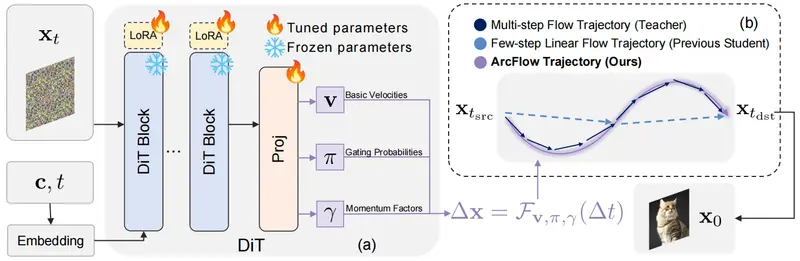
ArcFlow的核心思路是放弃线性近似,显式建模速度场的连续演化,通过物理“动量(momentum)”概念构建非线性轨迹,精准匹配教师模型的去噪路径,同时解决数值离散化误差问题。
1. 核心设计:连续动量过程的混合速度场
ArcFlow将扩散模型的去噪速度场参数化为多个连续动量过程的加权混合,而非单一的线性向量。具体来说:
- 不再直接预测“一步到位”的速度,而是预测K个基础速度向量(v)、对应的动量因子(γ)和门控概率(π);
- 组合速度场公式:$v_θ = Σ π_k · v_k · γ_k^{(1-t)}$,其中t为时间步,γ_k^(1-t)让速度随时间自然演化,形成非线性轨迹;
- 关键优势:这种参数化支持解析积分(而非数值离散计算),能精准计算每一步的位移Δx,完全避免离散化误差,实现对教师轨迹的高精度逼近。
2. 高效训练策略:轻量级适配器蒸馏
为了快速将上述参数化落地为“少步生成器”,ArcFlow采用预训练模型冻结+LoRA适配器微调的策略:
- 冻结教师模型(如Qwen-Image-20B、FLUX.1-dev)的主干网络(DiT),仅在关键位置插入轻量级LoRA适配器;
- 训练时仅优化适配器参数(占原始模型的<5%),既保证了训练效率,又避免破坏教师模型的原有能力;
- 收敛速度极快:训练至最优FID仅需1000步,远低于TwinFlow的3000+步,且训练过程稳定,无模式坍塌风险。
ArcFlow工作流程(2步生成完整链路)
ArcFlow的2步生成过程清晰且高效,核心是通过动量驱动的速度场计算精准位移,具体步骤如下:
输入: 随机噪声 x_t, 文本条件 c, 时间步 t
↓
DiT主干网络 (冻结) + LoRA适配器 (可训练) 前向计算
↓
三个投影头并行输出核心参数:
├─ v: K个基础速度向量(描述轨迹基础方向)
├─ γ: K个动量因子(控制速度随时间的演化趋势)
└─ π: K个门控概率(softmax归一化,加权混合不同动量过程)
↓
计算组合速度场: v_θ = Σ π_k · v_k · γ_k^(1-t)
↓
解析积分计算位移: Δx = Φ(v, π, γ, Δt)(无离散化误差)
↓
单步更新图像: x_{t-Δt} = x_t - Δx
↓
重复1次上述流程(共2步),输出最终高质量图像
关键洞察:教师模型的去噪轨迹是“曲线”,线性方法用“直线”拟合必然偏差,而ArcFlow通过动量参数化让轨迹自然弯曲,完美贴合教师的真实去噪路径。
核心功能与优势
| 功能/优势 | 具体说明 |
|---|---|
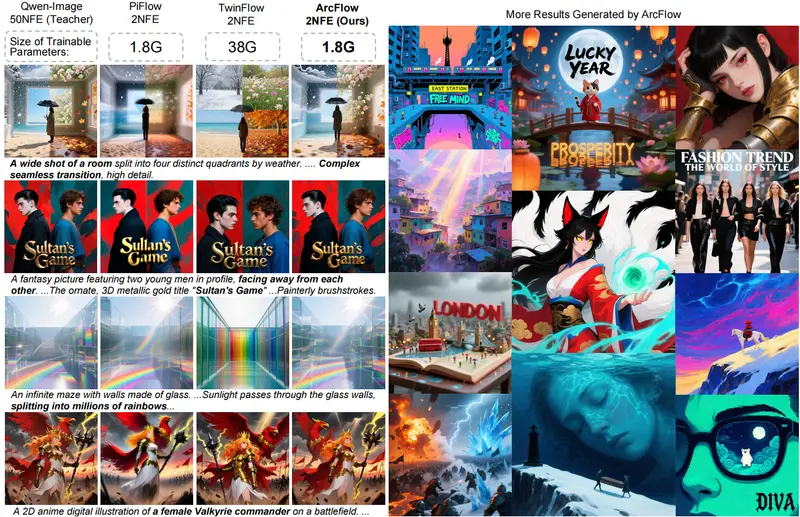
| 极速推理 | 仅需2步神经函数评估(NFE=2)生成1024×1024图像,相比原始50×2步教师模型实现40倍加速 |
| 高质量保留 | FID/pFID显著优于同类方法,细节清晰、结构正确,无模糊/伪影问题 |
| 多样性保障 | OneIG-Bench多样性指标比Qwen-Image-Lightning高85.7%,避免模式坍塌 |
| 参数高效 | 仅训练<5%的参数(1.8G),是TwinFlow(38G)的5%,训练/部署成本极低 |
| 稳定收敛 | 1000步训练至最优FID,远快于传统方法,工程落地效率高 |
实测验证:ArcFlow全面碾压同类加速方案
基于Qwen-Image-20B的蒸馏测试,ArcFlow在定量、定性维度均展现出绝对优势:
1. 定量指标对比(NFE=2时)
| 方法 | Geneval↑(生成质量) | DPG-Bench↑(对齐度) | FID↓(分布相似度) | pFID↓(感知相似度) | 可训练参数 |
|---|---|---|---|---|---|
| 教师模型(50×2步) | 0.87 | 88.32 | - | - | 20B |
| Qwen-Image-Lightning | 0.85 | 88.42 | 16.86 | 11.32 | - |
| pi-Flow | 0.83 | 86.45 | 20.07 | 12.42 | - |
| TwinFlow | 0.82 | 87.01 | 16.77 | 4.34 | 38G |
| ArcFlow (Ours) | 0.85 | 88.46 | 12.40 | 3.78 | 1.8G |
- FID/pFID越低,说明生成图像与真实分布/感知效果越接近:ArcFlow的FID比第二名TwinFlow低26%,pFID低13%;
- Geneval/DPG-Bench与教师模型持平,证明质量、文本对齐度无损失;
- 参数效率:仅用1.8G可训练参数实现最优效果,是TwinFlow的1/21。
2. 定性效果对比
| 方法 | 生成效果问题 | ArcFlow对比优势 |
|---|---|---|
| TwinFlow | 模式坍塌(相同噪声生成相似图像)、美学质量下降 | 图像风格多样,细节/美学与教师模型一致 |
| Qwen-Image-Lightning | 纹理模糊、结构伪影(如弯曲的剑、重复的纹理) | 结构精准,纹理清晰无伪影 |
| pi-Flow | 残留噪声、细节丢失(如人脸五官模糊) | 无噪声残留,细节完整还原 |
局限与未来方向
ArcFlow虽实现了2步生成的突破,但仍有优化空间,未来研究方向包括:
- 1步生成能力提升:当前强制1步生成时质量严重下降,需优化γ动量因子的建模网络,让单步轨迹更精准;
- 模型规模适配:验证ArcFlow在更小(如1B级)、更大(如100B级)扩散模型上的通用性;
- 多模态扩展:将非线性轨迹蒸馏思路应用到视频生成、3D内容生成等领域,解决多模态扩散模型的推理速度问题;
- 硬件适配优化:针对移动端/边缘设备,进一步量化ArcFlow的适配器参数,降低部署成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...