小红书智能创作基础技术团队正式推出 FireRed-Image-Edit——一款通用图像编辑模型,凭借原生编辑架构、精准指令遵循能力,在广泛场景下实现高保真、视觉一致的编辑效果,既打破了专业修图的门槛,也弥补了现有开源模型的性能短板,让“用文字描述,就能修图”的愿景落地。
- GitHub:https://github.com/FireRedTeam/FireRed-Image-Edit
- Demo:https://huggingface.co/spaces/FireRedTeam/FireRed-Image-Edit-1.0
- 模型:https://huggingface.co/FireRedTeam/FireRed-Image-Edit-1.0
- CmofyUI:https://huggingface.co/Comfy-Org/Qwen-Image-Edit_ComfyUI
- FP8:https://huggingface.co/cocorang/FireRed-Image-Edit-1.0-FP8_And_BF16
认识 FireRed-Image-Edit:它到底能解决什么问题?
在 AI 图像编辑普及之前,我们修图要么依赖 PS 等专业软件(耗时、难上手),要么使用简易修图工具(功能有限);而当下的 AI 修图工具,又普遍存在三大痛点:闭源商业产品“看不懂、用不了”,开源模型“跑不动、改不准”,普通工具“听不懂复杂指令、改完违和”。

FireRed-Image-Edit 的核心使命,就是解决这些痛点:用更低的部署成本、更高的执行效率,打造一款“听得懂人话、改得准细节、留得住原味”的通用 AI 图片编辑工具——无需专业技能,无需昂贵设备,只需用自然语言描述需求,就能完成从简单调色到复杂创意编辑的所有操作。
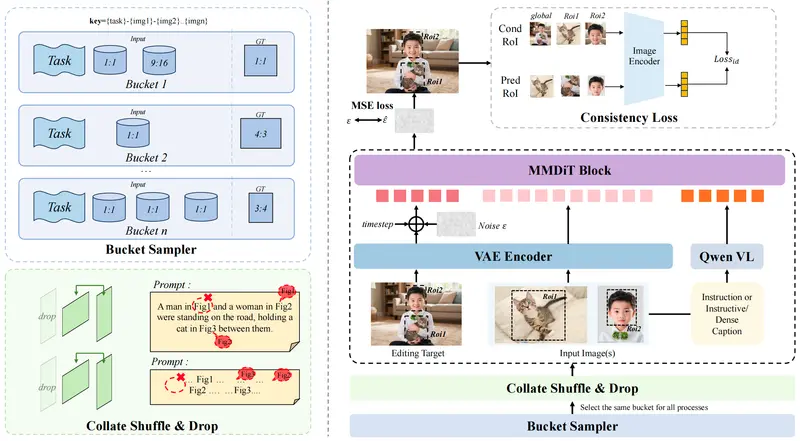
随着自然语言交互技术的成熟,“用描述替代操作”已成为 AI 应用的主流趋势,图片编辑领域也正从“动手”向“动口”升级。而 FireRed-Image-Edit 的突破,就在于它能精准理解复杂多条件指令,同时保证编辑结果的自然度和一致性,破解了“AI 修图易翻车”的行业难题。
核心功能:一张图能改的,它都能“听懂”并完成
FireRed-Image-Edit 就像一位全能修图师,覆盖内容、风格、结构、文字四大维度,无论是日常修图还是创意创作,都能轻松胜任,更有老照片修复、虚拟试穿等特色玩法:
1. 内容级编辑:精准修改画面核心元素
针对画面中的具体物体,实现“加、删、换、调”全操作,不破坏原图场景和光影:
- 添加物体:在风景照里加人物、宠物、道具,与原图融合自然,无违和感;
- 删除物体:一键移除路人、杂物、水印,自动修补背景空缺,不留修改痕迹;
- 替换物体:把苹果换成橙子、把晴天换成雨天、把运动鞋换成高跟鞋,保留物体原有姿态和光影关系;
- 调整属性:改变物体颜色、材质、大小、形状,比如“把黑色背包改成棕色皮质”“把圆形桌子改成方形”。
2. 风格级编辑:一键切换画面氛围
不改变画面内容,只调整视觉风格和色调,满足不同场景的审美需求:
- 艺术风格迁移:把普通照片转换成油画、水彩、动漫、素描、复古胶片等风格;
- 色调调整:一键切换暖调、冷调、清新、复古、暗黑等色调,适配社交媒体发布需求;
- 光影重构:改变光照方向、强度,比如“把侧光改成顶光”“给人物添加柔和逆光”,营造不同氛围感。
3. 结构级编辑:灵活调整画面布局
针对画面构图、物体姿态和视角,进行精细化调整,优化画面呈现效果:
- 视角变换:把正面人物照改成侧面照、把平视风景改成俯视视角,保留物体细节和比例;
- 姿态调整:让人物换姿势、换动作,比如“把站立的人改成坐姿”“让挥手的人改成比心”,姿态自然不僵硬;
- 构图重组:调整画面中元素的位置,比如“把左边的花瓶移到右边”“让人物居中,增加背景留白”。
4. 文字级编辑:高保真保留字体风格
这是 FireRed-Image-Edit 的突出优势,解决了多数 AI 修图“改字必翻车”的问题:
- 添加文字:在海报、图片上添加标题、文案,字体、大小、排版可通过文字指令调整;
- 修改文字:把“促销”改成“售罄”、把“2024”改成“2025”,精准保留原图字体风格、颜色和排版;
- 修复文字:让模糊、褪色、有划痕的文字变得清晰,比如修复老照片上的文字、海报上的模糊文案。
5. 特色高级玩法:解锁更多实用场景
- 虚拟试穿:把任意衣服“穿”到模特身上,精准还原衣物褶皱、垂坠感,保留模特原有姿态和背景,适配电商带货场景;
- 老照片修复:一键修复模糊、褪色、有划痕、破损的老照片,恢复清晰细节和自然色彩,同时保留老照片的时代质感;
- 多图像编辑:灵活处理多张图片,比如“把两张照片的人物合成到同一场景”“让两张照片保持统一色调”;
- 创意合成:打破现实边界,比如“让汽车长出翅膀”“让猫咪穿上西装”,生成超现实创意作品。
四大核心优势:为什么它比其他 AI 修图工具更能打?
相比市面上的 AI 图片编辑工具,FireRed-Image-Edit 凭借四大特色,实现了“好用、精准、高效、轻量”的平衡,既适合普通用户,也能满足专业需求:
优势一:听得懂“复杂人话”,指令遵循零偏差
不同于多数 AI 只能理解简单指令(比如“把狗变成猫”),FireRed-Image-Edit 能精准拆解复杂长指令。比如你说:“把图中穿红色连衣裙的女孩换成穿蓝色牛仔裤和白色T恤,保持女孩的表情和姿势不变,把背景里的咖啡馆换成图书馆,整体色调调整为暖黄色,光线柔和一点”,它能准确捕捉每一个需求点,不遗漏、不做错。
优势二:改得准、留得住,视觉一致性拉满
图片编辑的核心痛点,就是“改了该改的,毁了不该改的”。而 FireRed-Image-Edit 加入了专属的一致性约束机制,编辑时只会修改指令指定的区域,未编辑区域的细节、光影、风格完全保留:换衣服时,人物的长相、表情、姿态不变;改背景时,前景物体的光影关系不变;调色调时,文字的颜色、清晰度不变,整体画面和谐统一。
优势三:文字编辑能力突出,可媲美闭源方案
多数开源 AI 修图工具在处理文字时,要么字体混乱、要么排版怪异、要么和背景脱节,而 FireRed-Image-Edit 专门针对文字编辑做了优化,不仅能精准识别图片中的文字,还能模仿原图的字体、大小、颜色、排版,修改或添加文字后,能完美融入背景,无论是简单的文字修改,还是复杂的海报文案编辑,都能达到专业修图的效果,性能可与谷歌、OpenAI 等大厂的闭源产品媲美。
优势四:高效轻量,部署成本低
研究团队没有盲目追求“参数越大越好”,而是通过优化数据质量和训练方法,在相对轻量的架构上实现了顶级性能。相比动辄几百亿参数、需要专业显卡才能运行的开源模型,FireRed-Image-Edit 更轻量化,未来普通用户有望在电脑、手机等消费级设备上直接运行,无需投入高昂的硬件成本。同时,它基于文本到图像的基座模型原生构建,编辑效率更高,生成速度更快。
工作原理:用大白话看懂 AI 修图的“魔法”
FireRed-Image-Edit 能精准听懂指令、做好修图,背后离不开一套科学的训练体系,就像培养一位顶尖修图师,从基础到进阶,逐步打磨能力:
第一步:海量“看图说话”,打好视觉基础(预训练阶段)
就像人要先认识世界,才能学会改造世界,FireRed-Image-Edit 首先通过“看图说话”积累视觉知识:研究团队给它投喂了超过 10 亿张各类图片(风景、人物、动物、建筑、海报等),以及对应的文字描述,让它记住“什么是猫”“什么是咖啡馆”“什么是暖色调”,建立起扎实的视觉认知,能精准匹配文字描述和画面元素。
第二步:学习“编辑案例”,掌握修图技巧(监督学习阶段)
有了基础认知后,FireRed-Image-Edit 开始系统学习修图技巧:研究团队准备了超过 1 亿组“编辑前后对比”的样本,每组样本都包含“原始图片、编辑指令、目标图片”——比如“原始图片是红色苹果,指令是‘把苹果改成绿色’,目标图片是绿色苹果”。通过反复学习这些样本,它逐渐掌握了“接收指令→理解需求→执行修改”的完整逻辑,知道不同指令对应什么样的修图操作。
第三步:“名师指导”打磨,优化细节效果(强化学习阶段)
为了让修图效果更精准、更自然,研究团队设计了一套自动评分系统,像老师一样给 FireRed-Image-Edit 打分:如果编辑结果符合指令、画面自然、细节到位,就给“奖励”;如果改错区域、画面违和、文字翻车,就给“惩罚”,让它在反复调整中优化细节。
特别针对文字编辑,团队还专门设计了“布局感知”评分标准——不仅看文字内容对不对,还要看文字的位置、大小、风格是否和背景协调,避免出现“字太大、太歪、和背景脱节”的问题。
第四步:加入“约束机制”,守住原图特色(一致性优化)
为了避免“改着改着把原图特色弄丢”(比如修图时把人物长相改歪),研究团队加入了一致性约束机制:在编辑过程中,AI 会实时对比“编辑后的画面”和“原始画面”,重点校验人脸、核心物体等关键区域的相似度,确保只修改指令指定的内容,不破坏原图的核心特色。
第五步:精细化数据处理,筑牢能力根基
FireRed-Image-Edit 的强大,离不开背后精细化的数据工程。研究团队建立了一套完整的“数据生产线”,从 16 亿张原始图片中筛选出高质量样本:先去重(剔除重复、相似图片),再清洗(过滤模糊、曝光过度、有水印的图片),然后分类(按场景、物体、风格精细分类),接着标注(AI 辅助+人工校验,生成精准的文字描述和编辑指令),最后平衡(确保简单任务和复杂任务、常见场景和罕见场景的样本比例合理)。
针对“冷门需求”(比如折纸风格转换、小众方言文字编辑),团队还会专门补充样本,确保 FireRed-Image-Edit 能应对各种复杂场景,不“偏科”。
测试结果:用实力说话,表现远超同类开源模型
研究团队在多个权威测试集上,对 FireRed-Image-Edit 进行了严格评估,同时与当前主流的开源模型、闭源商业产品对比,结果十分亮眼,核心指标均达到领先水平:
1. 通用编辑能力测试(ImgEdit、GEdit 基准)
在这两个国际通用的图片编辑测试集上,FireRed-Image-Edit 在“指令遵循度”“画面高质量”“视觉一致性”三大核心指标上,均达到或超过当前最强开源模型,部分任务甚至超越了谷歌、字节跳动等大厂的闭源产品。尤其是“视觉一致性”,FireRed-Image-Edit 的得分显著领先,能最大程度保留原图特色,避免修图翻车。
2. 文字编辑专项测试
团队专门设计了文字编辑测试集,涵盖简单文字修改、复杂海报文案、模糊文字修复等场景,结果显示:
- 文字识别准确率超过 98%,能精准识别图片中的模糊、褪色文字;
- 字体风格保留、背景融合度等指标,显著优于其他开源模型;
- 即使是长文本、复杂排版的海报,也能精准修改,文字排版合理、与背景融合自然。
3. 人类主观评价测试
研究团队邀请了大量普通用户、专业修图师,进行“盲测”(用户不知道哪个结果是哪个模型生成的),评分结果显示:
- “指令遵循度”:FireRed-Image-Edit 得分最高,用户认为它“最能听懂需求、不做错”;
- “画面自然度”:FireRed-Image-Edit 领先,编辑结果更真实、更像专业修图师的作品;
- “整体满意度”:超过 85% 的用户表示,更愿意使用 FireRed-Image-Edit 进行日常修图和创意创作。
4. 典型案例对比
官方展示的大量对比案例,能直观看到 FireRed-Image-Edit 的优势:
- 添加物体:指令“在床上加一个人使用笔记本电脑”,其他模型生成的人物姿态怪异、与床的互动不自然,而 FireRed-Image-Edit 生成的人物姿态合理、光影与床面贴合,无违和感;
- 属性修改:指令“把巧克力酱换成蛋黄酱”,竞品仅简单改变颜色,而 FireRed-Image-Edit 不仅换对颜色,还保留了酱料的流淌质感、光泽度,还原真实细节;
- 老照片修复:对于模糊、褪色、有划痕的老照片,FireRed-Image-Edit 能恢复清晰的面部细节、自然的色彩,同时保留老照片的复古质感,不会修得过于“现代化”;
- 虚拟试衣:把衣服“穿”到模特身上,FireRed-Image-Edit 能精准还原衣物的褶皱、垂坠感,贴合模特姿态,而竞品常出现衣物变形、光影脱节的问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











