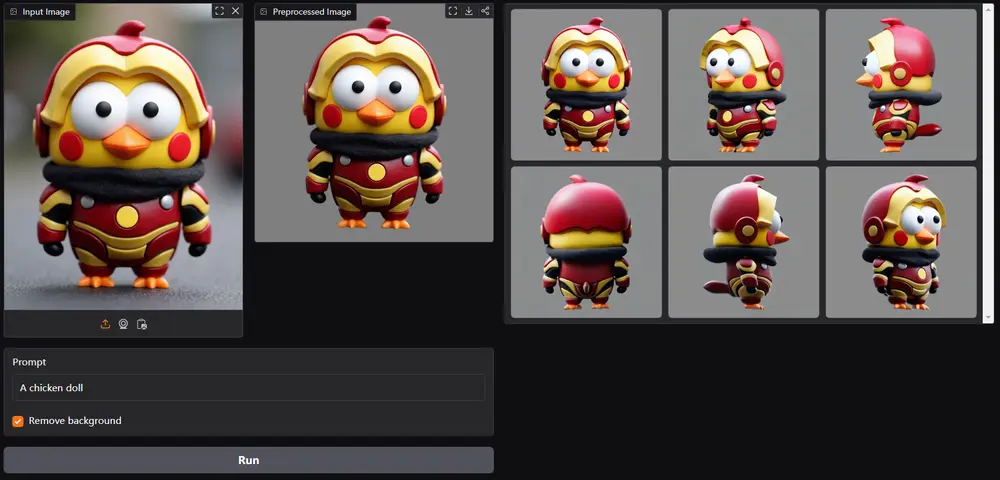
阿里全新推出新一代图像生成基础模型Qwen-Image-2.0,凭借专业文字渲染、细腻真实质感、超强语义遵循、轻量模型架构四大核心特色,实现生图与编辑功能的一体化融合,在文生图和图生图双赛道均展现出优越性能,尤其在专业信息图、PPT、海报等商业实用场景中表现亮眼,还支持2K高分辨率写实场景刻画,兼顾效果与生成效率。
- 官方介绍:https://qwen.ai/blog?id=qwen-image-2.0
- 试用地址:https://chat.qwen.ai/?spm=a2ty_o06.30285417.0.0.68a2c921M9cv0q&inputFeature=t2i

在AI Arena模型盲测中,作为生图编辑二合一的全功能模型,Qwen-Image-2.0在文生图和图生图双基准测试中均取得优异成绩,其核心能力的提升,源于阿里对图像生成两大支线的长期探索与融合——此前阿里分别在生图支线打磨图像准确性与真实性,从2025年8月Qwen-Image的精准文字渲染,到12月Qwen-Image-2512的细节质感强化;在编辑支线深耕功能性与一致性,从单图编辑、多图编辑到图层拆分、一致性提升,而Qwen-Image-2.0则成功将两条支线合二为一,实现1+1>2的效果突破。
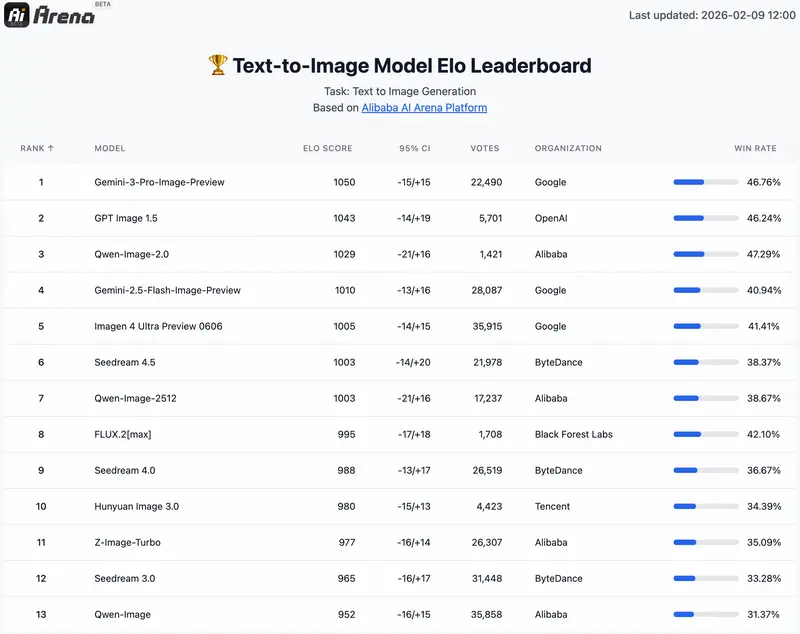
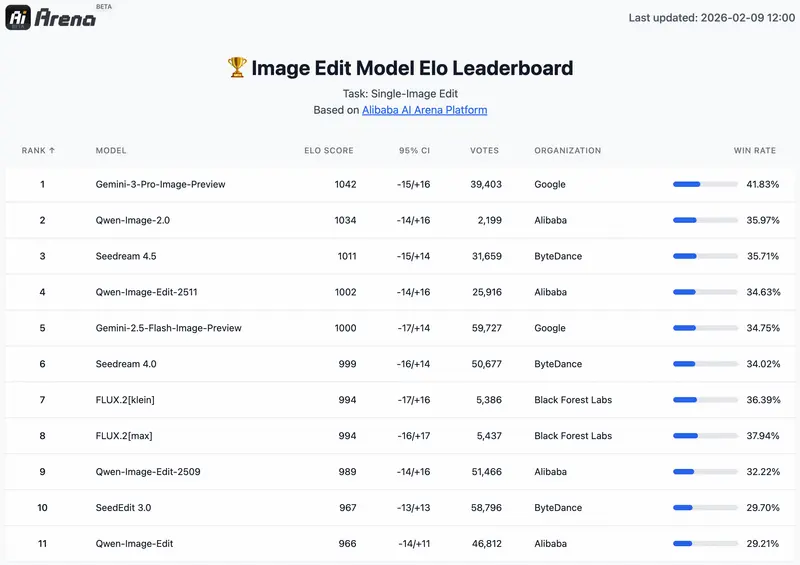
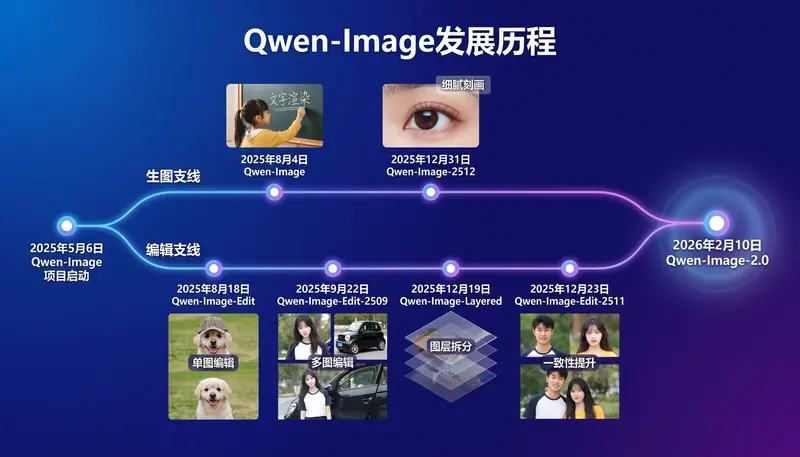
值得一提的是,本次介绍模型发展历程的PPT,正是由Qwen-Image-2.0直接生成,不仅精准还原时间轴、文字信息,还能完成复杂的“画中画”绘制,甚至实现组图内的元素一致性,充分展现了其在专业图文排版场景的硬实力。
文字渲染五大核心特性:准、多、美、真、齐,适配全场景专业需求
Qwen-Image-2.0的核心优势集中体现在文字渲染能力上,突破了传统图像模型“文字绘制不准、排版杂乱、场景适配差”的痛点,形成准、多、美、真、齐五大特色,可轻松应对PPT、信息图、海报、漫画、书法作品等各类专业文字排版需求。
准:精准还原指令,画中画也能高度一致
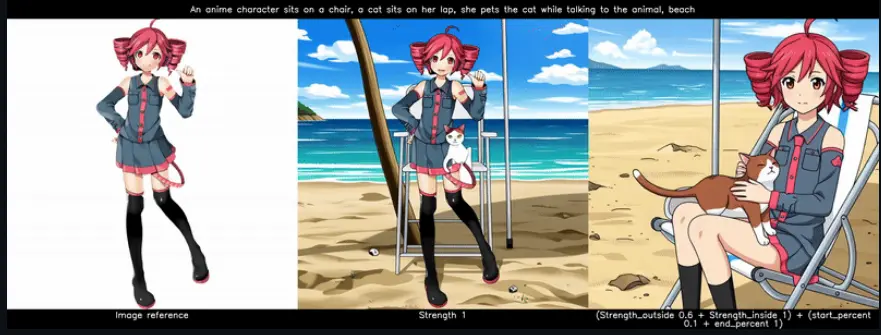
模型能精准理解并渲染复杂文字指令,无论是时间轴、组图说明还是书法全文,都能做到文字无错漏、元素匹配度高。例如生成“戴帽子的小狗”与“去除帽子的同一只小狗”组图时,不仅能完成双图绘制,还能保证小狗的外形、神态完全一致,实现“画中画”的精准还原,为专业PPT制作提供极大便利。

多:支持1K Token超长指令,复杂信息图一键生成
模型最高支持1K Token的超长指令输入,可直接渲染逻辑复杂、信息密集的专业信息图,无需多次调整。从A/B测试结果汇报表、OKR工作法信息图,到双语旅行海报、电影工业级海报,只需输入详细指令,模型就能一键生成包含多模块、多文字、多图表的完整作品,无需人工二次排版。

美:字图融合自然,排版布局贴合场景美学
在文字与图像融合时,模型会根据画面风格自动优化排版,让文字自然融入场景,不遮盖图像主体,同时适配不同风格的美学要求。例如生成中国古典水墨长卷时,会将宋词书法按“自上而下、自右向左”的传统顺序排布,墨色浓淡相宜,与水墨背景的萧瑟意境高度契合;生成电影海报时,会将出品方、主演、制作信息等密集文字按电影工业标准排布,字体、颜色、质感与画面光影自然融合,彰显高级感。
真:适配不同介质质感,文字渲染贴合现实物理属性
模型能精准识别文字所处的介质与场景,根据玻璃、布料、纸张、金属等不同材质的物理特性,以及空间角度、光影效果,调整文字的渲染方式,让文字看起来“真实存在”于画面中。例如生成办公室玻璃白板场景时,白板上的手写文字会带有自然的笔锋、压感变化和轻微晕染,衣服上的logo会有布料的纹理贴合感,杂志上的文字会有印刷的清晰质感,大幅提升画面的真实度。

齐:文字排版规整对齐,适配表格、漫画、日历等规整场景
模型擅长渲染需要严格对齐的文字内容,无论是7列6行的日历表格、4×6格的漫画对话框,还是OKR信息图的多模块文字,都能做到行列对齐、间距均匀、字体统一。漫画对话框中的文字会居中对齐,日历中的日期、农历信息会按格子规整排布,漫画分镜中的文字大小、位置会贴合对话框,让规整类作品的视觉效果更专业。

2K高分辨率写实刻画,自然与人物细节拉满
除了超强的文字渲染能力,Qwen-Image-2.0在写实图像生成上也实现了大幅升级,原生支持2K(2048×2048)高分辨率输出,能细腻刻画人物、自然、建筑等各类写实场景的微观细节,让画面的真实感和层次感达到新高度。

在自然场景刻画中,模型能精准区分23种以上不同明度、饱和度、冷暖倾向的绿色,还原橡树、枫树、苔藓等不同植被的蜡质、绒面、革质等材质差异,甚至能刻画叶片的叶脉、露珠的反光、空气中的悬浮微粒,营造出充满呼吸感的夏日森林秘境;在人物与动态场景刻画中,能还原皮肤的毛孔、胡茬,衣物的磨损纹理、经纬线,以及动态中的肌肉线条、汗水痕迹,例如“马骑人”的力量对抗场景中,马的鬃毛飞扬、男子的青筋凸起、龟裂地面的浮尘颗粒都能被细腻捕捉,画面的张力与真实感拉满。
生图编辑二合一,编辑能力同步升级
Qwen-Image-2.0最核心的突破是实现了生图与编辑的一体化融合,并非简单的功能叠加,而是将文生图的文字渲染、真实质感优势,全面赋能到图像编辑功能中,让编辑操作更精准、更自然、更贴合需求,无需切换模型,一站式完成“生成-编辑-优化”全流程。

模型的编辑能力覆盖多场景需求,既可以在现有图片上精准题词,例如在水墨图中添加赵孟頫楷书宋词,字体、布局与画面风格高度融合;也可以完成组图生成、人物合成,例如将不同场景、不同着装的同一位东亚男性合成一张自然合照,实现背景统一、光影匹配、站姿协调,无任何拼接痕迹;还能完成跨次元编辑,例如在真实的城市照片底图中,添加扁平化卡通形象,保持实景的真实性,同时让卡通形象与建筑的位置、比例自然契合,实现真实与虚拟的完美融合。
轻量架构兼顾效率,小模型也有大能力
Qwen-Image-2.0采用更轻量的模型架构,在保证2K高分辨率、超强渲染能力的前提下,大幅提升生成速度,实现“更小模型、更快速度”的优化,2K图像可在数秒内生成,兼顾视觉效果与实际使用效率,让用户在专业场景中无需长时间等待,提升创作效率。
从专业的商业信息图、PPT制作,到日常的海报、漫画创作,再到写实场景生成、图像精细化编辑,Qwen-Image-2.0凭借“文字渲染强、写实质感优、生图编辑一体、轻量高效”的核心能力,成为一款适配全场景的图像生成基础模型,为创作者提供了更高效、更专业的AI创作工具,也让AI图像生成在商业实用场景中实现了新的突破。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...