在当前多模态生成模型的发展中,研究者始终在探索一个统一的建模范式:能否用类似语言模型“预测下一个词”的方式,来生成图像?这种被称为“下一令牌预测(next-token prediction)”的自回归方法,在文本生成领域已极为成熟,但将其扩展至图像内容时,长期面临三大难题:
- 生成图像视觉保真度低
- 细节渲染易出现伪影或失真
- 难以准确遵循复杂或多步指令
这些问题的根源,部分来自图像离散化过程中的信息损失,以及自回归生成中误差的逐步累积。正因如此,近年来主流多模态模型(如 DALL·E 3、Stable Diffusion 等)普遍采用混合架构:用扩散模型生成图像,用自回归模型处理语言,二者联合训练,却牺牲了“统一建模”的简洁性与潜力。
- 项目主页:https://x-omni-team.github.io
- GitHub:https://github.com/X-Omni-Team/X-Omni
- 模型:https://huggingface.co/collections/X-Omni/x-omni-models-6888aadcc54baad7997d7982
- Demo:https://huggingface.co/collections/X-Omni/x-omni-spaces-6888c64f38446f1efc402de7
现在,腾讯混元项目组提出 X-Omni —— 一个试图重新回归统一自回归框架的多模态生成模型。它通过引入强化学习(Reinforcement Learning, RL),显著提升了离散自回归方法在图像生成上的质量,实现了图像与语言生成的无缝整合。
X-Omni 是什么?
X-Omni 是一种新型的统一多模态生成模型,其核心目标是:
用同一个自回归模型,同时生成高质量图像和连贯文本。
它不依赖扩散模型进行端到端生成,而是构建了一个包含三个核心组件的协同框架:
- 语义图像分词器(SigLIP-VQ)
将图像编码为离散的语义标记(tokens),保留高层语义信息。 - 统一自回归模型(7B 参数语言模型)
同时处理图像标记和文本标记,以“预测下一个 token”的方式生成完整序列。 - 离线扩散解码器
将生成的离散标记序列还原为高保真图像,解码过程无需参与训练。
这一设计在保持自回归统一性的同时,借助预训练扩散模型弥补像素级细节的生成能力。
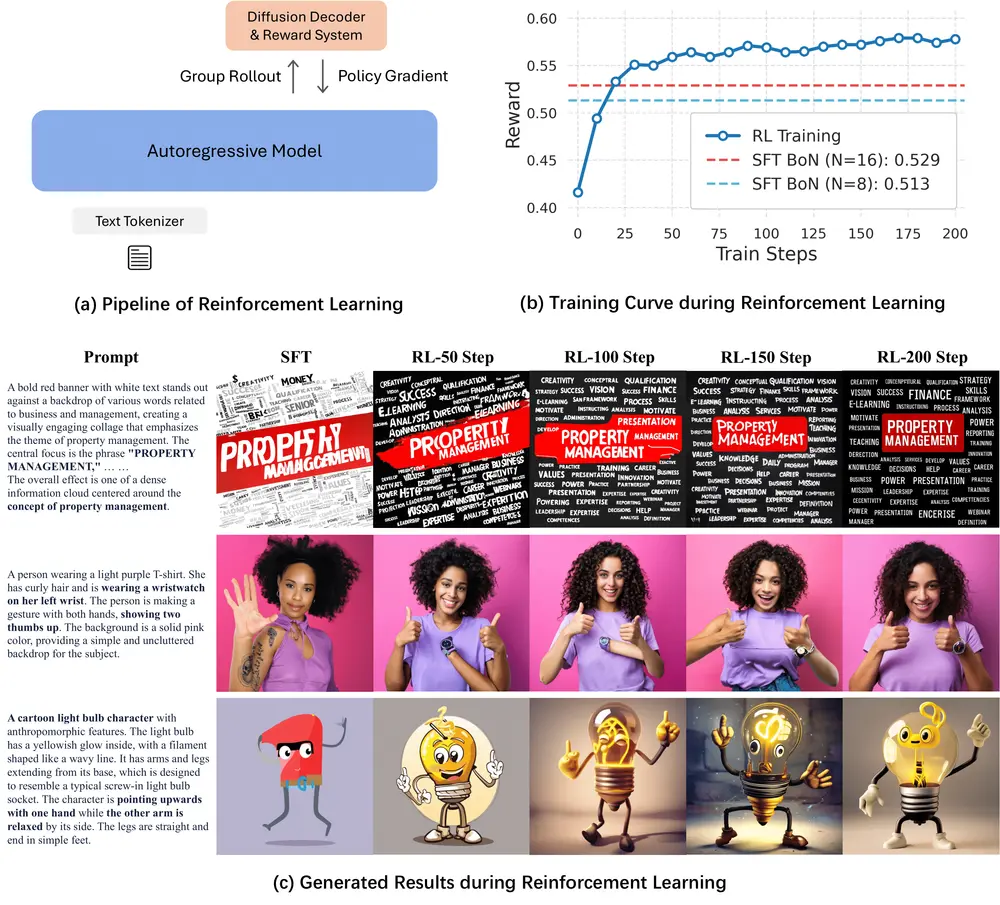
关键突破:用强化学习优化生成过程
X-Omni 最具创新性的部分,在于引入了基于强化学习的优化机制,使用 GRPO(Group Relative Policy Optimization)算法 对生成过程进行后训练(post-training)。
传统自回归图像生成模型一旦出错,后续生成会持续偏离目标。X-Omni 则通过一个多维度奖励系统,在生成完成后评估整体质量,并反向指导模型改进:
- 美学质量奖励:判断图像是否自然、美观
- 文本对齐奖励:评估图像内容与输入指令的一致性
- OCR 准确性奖励:专门衡量图像中渲染文本的可读性与正确率
通过 RL 的全局优化能力,X-Omni 显著减少了累积误差,提升了复杂场景下的指令遵循能力。
核心能力:不止于“画图”
X-Omni 的能力远超传统文生图模型,尤其在以下三个维度表现突出:
1. 高质量图像生成
在 DPG-Bench 和 GenEval 等权威基准测试中,X-Omni 达到当前最先进的性能水平。即使是复杂指令,如:
“一只小鸟栖息在长满苔藓的树枝上,背景是黄昏森林,风格为超现实主义,羽毛细节清晰”
X-Omni 也能准确理解并生成细节丰富的图像。
2. 长文本精确渲染
这是 X-Omni 的一大亮点。它能在图像中准确渲染中英文长文本,包括段落、标题、多行文字排版等。
在 OneIG-Bench 和 LongText-Bench 测试中,其表现优于 GPT-4o,尤其在中文文本渲染任务中,字符清晰、布局合理,几乎没有错字或扭曲。
3. 图像理解与多轮交互
得益于统一的 token 空间,X-Omni 不仅能生成图像,还能反过来理解图像内容,支持:
- 图像描述生成
- 视觉问答(VQA)
- 多轮对话中的图像上下文推理
在 OCRBench 等图像理解基准上,其表现优于 Emu3 和 Janus-Pro 等同类模型。

技术特点一览
| 特性 | 说明 |
|---|---|
| 统一自回归框架 | 图像与语言共享同一模型架构,实现知识迁移 |
| 强化学习优化(GRPO) | 减少误差累积,提升整体生成一致性 |
| 不依赖 CFG | 无需分类器自由引导(Classifier-Free Guidance),降低推理开销 |
| 语义编码器(SigLIP-VQ) | 生成更具语义意义的离散标记,支持双向理解 |
| 任意分辨率生成 | 支持生成高分辨率图像,适应多样化应用场景 |
为何重要?回归统一建模的尝试
X-Omni 的意义不仅在于性能提升,更在于它重新验证了统一自回归建模的潜力。
当前主流方案依赖“扩散生成 + 自回归语言”双系统,虽然效果好,但结构复杂、推理不一致。X-Omni 证明:
通过强化学习优化,离散自回归方法仍可在图像生成中达到高质量水平。
这为未来构建真正统一的多模态智能体提供了新路径——一个模型,既能写、又能画、还能看和对话。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











