中国电信人工智能研究院(TeleAI)提出TeleStyle——一款轻量级且高效的图像与视频内容保持式风格迁移模型,核心基于Qwen-Image-Edit构建,针对性解决了扩散变换器(DiT)架构中内容与风格特征固有纠缠的行业痛点。
- 项目主页:https://tele-ai.github.io/TeleStyle
- GitHub:https://github.com/Tele-AI/TeleStyle
- 模型:https://huggingface.co/Tele-AI/TeleStyle
该模型通过课程持续学习框架、混合高质量数据集训练,在风格相似度、内容一致性、美学质量三大核心指标上均达到SOTA,同时实现零样本泛化未知风格、视频时序一致性保持,且基于LoRA轻量微调实现,训练与部署成本极低,成为DiT架构下内容保持式风格迁移的全新标杆。

核心研究背景:DiT架构的风格迁移核心难题
风格迁移的核心需求是精准保留内容结构,同时彻底迁移目标风格,传统基于UNet的扩散模型可通过“UNet解耦定律”轻松分离内容与风格特征,但DiT架构因内部特征高度纠缠,难以实现二者的有效解耦,导致现有DiT风格迁移方法常出现两大问题:
- 风格迁移不彻底,仅呈现浅层滤镜效果,无法还原目标风格的核心特征;
- 内容保真度低,迁移风格后丢失原图细节(如面部特征、物体轮廓、场景布局),甚至出现内容泄漏、结构扭曲。
TeleStyle的诞生,正是为了破解DiT架构的这一核心难题,实现“内容丝毫不丢,风格彻底迁移”的双重目标。
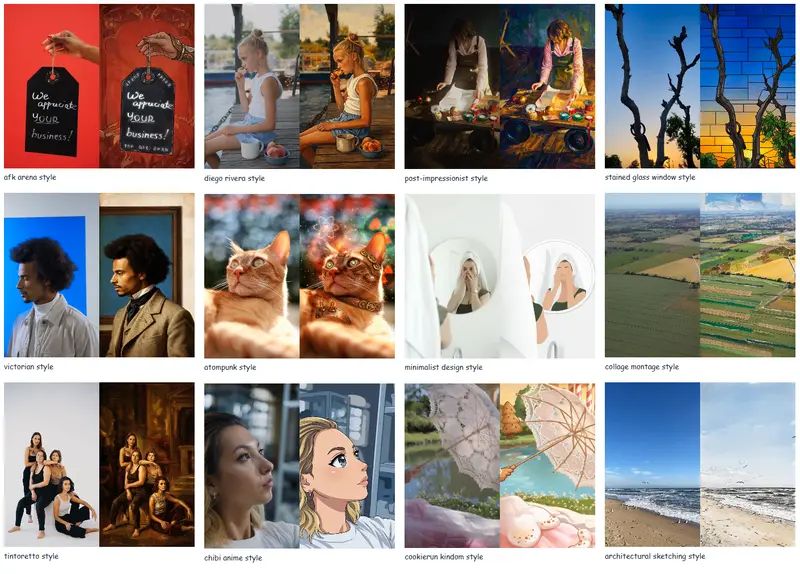
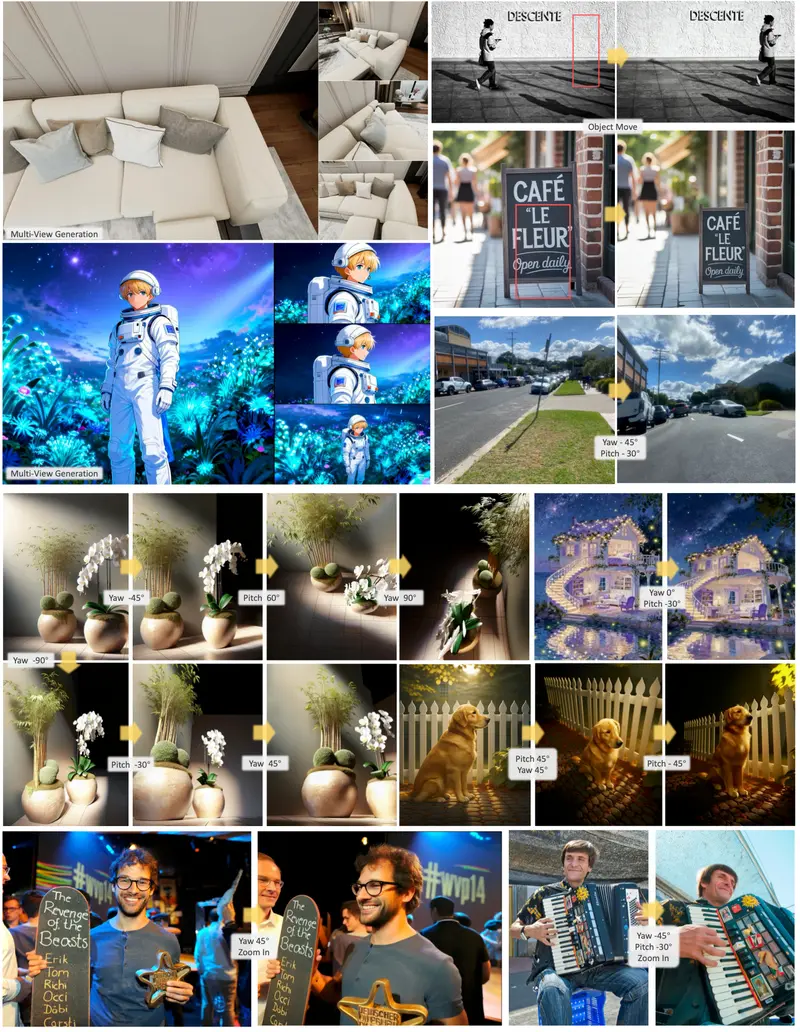
核心功能:覆盖图像/视频,支持零样本泛化
TeleStyle分为图像和视频两大模块,兼顾基础风格迁移与高阶泛化能力,无需针对特定风格训练LoRA,即可适配多种艺术风格,满足不同场景的风格化需求:
| 功能模块 | 核心能力 | 适用场景 |
|---|---|---|
| TeleStyle-Image | 图像到图像双参考风格迁移(内容图+风格图),精准保留内容细节,彻底迁移风格特征 | 照片艺术化、插画风格转换、设计素材风格定制 |
| TeleStyle-Video | 视频到视频风格迁移,基于首帧风格锚点实现全序列传播,无需光流引导即可保持时序一致性 | 短视频风格化、影视片段艺术重绘、动画风格转换 |
| 零样本风格泛化 | 无需微调,直接处理训练集中未见过的风格类别 | 小众风格迁移、个性化风格定制 |
| 多风格原生支持 | 天然适配油画、科幻、水彩、动漫、素描等多种主流艺术风格 | 多元化创意创作、视觉内容制作 |
核心创新特点:四大设计,兼顾性能与轻量
TeleStyle能在DiT架构下实现SOTA性能,且保持轻量级特性,核心源于四大创新设计,从训练框架、数据集、模型实现、视频优化全维度突破:
1. 课程持续学习框架:分阶段训练,平衡保真与泛化
这是TeleStyle的核心创新,针对混合数据集设计三阶段渐进式训练策略,让模型先夯实基础能力,再精炼内容保真度,最后实现鲁棒泛化,避免单一训练阶段的能力失衡:
- 阶段1:能力激活 - 在人工精选的高质量干净数据集上训练,建立模型的基础风格迁移与内容保持能力;
- 阶段2:内容保真度精炼 - 筛选高内容一致性的样本进行训练,针对性解决多人场景面部身份丢失、物体细节模糊等问题,强化内容保真的精准度;
- 阶段3:鲁棒泛化 - 混合少量合成的嘈杂数据集训练,在不损害内容保真度的前提下,提升模型对未见过的未知风格的零样本泛化能力。
2. 混合双数据集策略:高质量打底,大数量拓界
精心策划“精选+合成”混合三元组数据集(风格参考+内容参考+目标图),既保证训练质量,又扩展风格多样性,为模型性能奠定数据基础:
- D_collected(30万组) - 人工精选的高质量三元组,涵盖30种主流风格类别,标注精准、内容与风格匹配度高,作为模型训练的核心基础;
- D_synthetic(100万组) - 通过“反向三元组合成”技术从野外风格图像自动生成,大幅扩展风格覆盖范围,提升模型的风格适应性与泛化能力。
3. 轻量级实现:LoRA微调查,低成本高收益
基于阿里通义千问的Qwen-Image-Edit(MMDiT架构) 进行二次开发,全程采用LoRA轻量微调,无需训练全部模型参数,兼顾训练效率与部署便捷性:
- 微调秩(rank)仅设为32,训练成本极低,普通算力即可完成;
- 基于成熟基础模型构建,无需从零开发,大幅缩短研发周期;
- 模型体积小,部署门槛低,可快速落地实际应用场景。
4. 视频时序一致性优化:锚点引导,无需额外优化
针对视频风格迁移的时序抖动、帧间不一致问题,设计轻量级时序优化方案,无需光流引导、无需测试时优化,即可实现全视频序列的风格统一与时序连贯:
- 将风格参考图像处理后的首帧作为时序锚点(时序索引0),指导后续所有视频帧的风格迁移;
- 采用Wan2.1-1.3B作为视频骨干网络,强化帧间特征关联;
- 通过通道级联技术融合风格锚点与视频帧特征,保证风格在全序列中的稳定传播。
工作原理:图像/视频架构解耦,针对性设计核心流程
TeleStyle针对图像和视频的不同特性,设计了两套专属的风格迁移架构,均基于DiT构建,且无需复杂的外部模块,实现“简洁高效、精准可控”的风格迁移。
1. 图像风格迁移:双参考+标准化提示,DiT直接解耦
以Qwen-Image-Edit为核心,通过双参考输入、标准化提示模板和专用编码技术,让DiT实现内容与风格的有效解耦,核心流程极简:
输入:风格参考图 I_style + 内容参考图 I_content + 标准化文本提示
↓
核心骨干:Qwen-Image-Edit(MMDiT架构)
↓
输出:保持内容结构与细节、迁移目标风格的生成图像
关键技术细节
- MS-RoPE多尺度旋转位置编码:为风格参考和内容参考分配不同的编码标识,让模型精准区分双参考输入,避免特征混淆;
- 标准化提示模板:固定使用“将图2的风格迁移到图1,保持图1的内容和特征”,减少文本提示的不确定性,提升模型执行精度;
- 专属推理配置:强制保持内容参考图与输出图的宽高比一致,避免内容拉伸变形;风格参考图缩放到最小边长的正方形,最大化保留风格特征。
2. 视频风格迁移:首帧锚点+通道级联,无文本条件时序传播
基于图像风格迁移能力拓展,以首帧风格化结果为锚点,融合视频帧特征实现全序列风格迁移,无需文本条件,核心流程:
风格参考图像(首帧风格化结果)→ Patch Embedder 1(风格特征提取)
源视频帧 + 随机噪声 → Patch Embedder 2(视频帧特征提取)
↓
通道级联(Channel-Wise Concatenation):风格+视频帧特征融合
↓
核心处理:DiT Blocks + 空文本嵌入(无文本条件干扰)
↓
输出:风格统一、时序连贯的风格化视频序列
关键设计亮点
- 无文本条件依赖:避免文本提示对视频风格一致性的干扰,仅通过特征融合实现风格传播;
- 噪声融入源视频帧:遵循扩散模型生成逻辑,提升视频生成的视觉质量;
- 轻量级特征融合:采用通道级联而非复杂的特征融合网络,在保证效果的同时降低计算量。
性能表现:三大核心指标全面SOTA,定量+定性双优
TeleStyle在内容保持式风格迁移的核心评估指标上实现全面超越,对比StyleID、InstantStyle、OmniGen-v2、DreamO等主流方法,在风格相似度、内容一致性、美学质量上均达到SOTA,定量数据与定性效果双重验证模型性能。
定量对比:核心指标大幅领先,优势显著
在通用评估基准上的定量结果(数值越高性能越好):
| 方法 | 风格相似度 CSD↑ | 内容保持 CPC@0.5↑ | 内容保持 CPC@0.3:0.9↑ | 美学评分↑ |
|---|---|---|---|---|
| StyleID | 0.453 | 0.190 | 0.180 | 5.749 |
| InstantStyle | 0.397 | 0.189 | 0.134 | 5.464 |
| CSGO(次优) | 0.535 | 0.379 | 0.224 | 5.969 |
| OmniGen-v2 | 0.462 | 0.243 | 0.166 | 5.843 |
| DreamO | 0.402 | 0.193 | 0.102 | 6.149 |
| TeleStyle (ours) | 0.577 | 0.441 | 0.304 | 6.317 |
核心结论
- 风格相似度(CSD)较次优方法CSGO提升7.8%,实现更彻底的风格迁移;
- 内容保持能力(CPC@0.5)提升16.4%,精准保留原图的细节与结构;
- 美学评分达到6.317,为所有对比方法中最高,生成结果的视觉美感与艺术表现力更优。
定性对比:内容保真更精准,风格迁移更彻底
与OmniGen V2、OmniStyle、DreamO等竞品相比,TeleStyle的定性生成效果展现出三大核心优势:
- 内容保真度极高 - 能精准保留人物面部特征、服装细节、物体轮廓、场景布局,即使是多人复杂场景,也不会出现身份丢失、细节模糊;
- 风格迁移更彻底 - 并非浅层滤镜效果,而是深度还原目标风格的核心特征,如动漫风格的眼部细节、油画的笔触纹理、水彩的晕染效果;
- 无内容泄漏与特征混淆 - 不会将风格参考图中的无关元素(如人物、物体)错误混入生成结果,内容与风格的边界清晰,执行指令的精准度更高。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...