Tiamat AI、上海科技大学、新加坡国立大学和Liblib AI的研究人员推出 EasyControl 框架,为基于扩散变换器(DiT架构)的图像生成模型提供高效且灵活的条件控制能力。它通过一系列创新设计,使得 DiT 模型能够实现单条件训练后的零样本多条件泛化,并在多种图像生成任务中表现出色。
- 项目主页:https://easycontrolproj.github.io
- GitHub:https://github.com/Xiaojiu-z/EasyControl
- 模型:https://huggingface.co/Xiaojiu-Z/EasyControl
- Demo:https://huggingface.co/spaces/jamesliu1217/EasyControl
- ComfyUI插件:https://github.com/jax-explorer/ComfyUI-easycontrol(需要40G显存、50G硬盘空间才可以运行)

主要功能
- 单条件训练后的零样本多条件泛化:EasyControl 能够在仅使用单条件数据训练的情况下,实现多条件组合的图像生成,而无需额外的多条件训练。
- 高效灵活的条件注入:通过 Condition Injection LoRA Module,可以将各种条件信号(如空间条件、主体条件等)灵活地注入到预训练的 DiT 模型中,而无需修改模型的原始权重。
- 支持任意分辨率和宽高比的图像生成:通过 Position-Aware Training Paradigm,模型能够生成具有不同分辨率和宽高比的图像,适应多样化的应用场景。
- 显著降低推理延迟:结合 Causal Attention Mechanism 和 KV Cache 技术,大幅减少了图像合成的延迟,提升了整体效率。
主要特点
- 高效性:通过 Position-Aware Training Paradigm 和 KV Cache 技术,显著降低了计算复杂度和推理时间。
- 灵活性:支持多种条件信号的注入,并能够处理不同分辨率和宽高比的图像生成任务。
- 零样本多条件泛化能力:即使在单条件训练下,也能很好地处理多条件组合的生成任务,展现出强大的泛化能力。
- 即插即用:作为一个轻量级模块,EasyControl 可以无缝集成到现有的 DiT 模型中,无需对基础模型进行大量修改。
工作原理
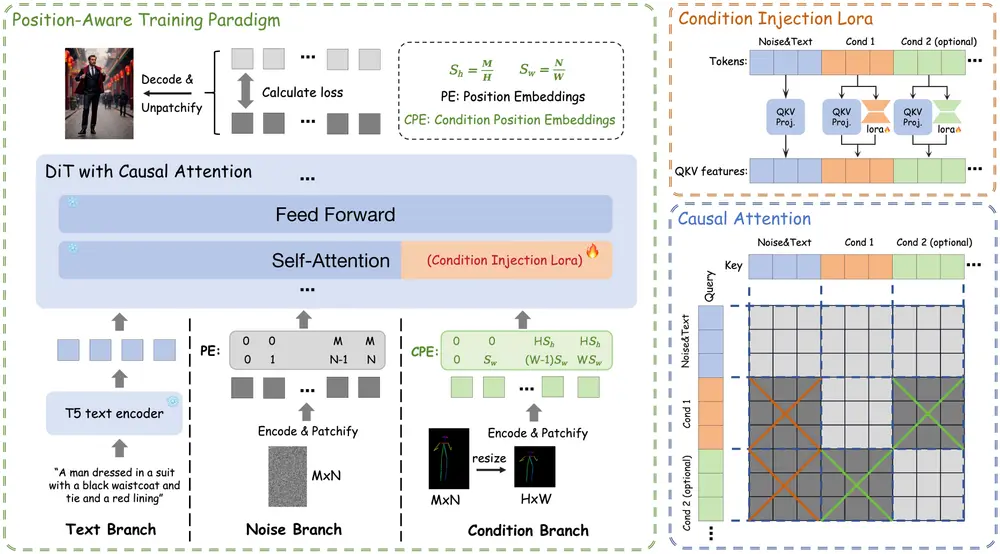
- Condition Injection LoRA Module:通过引入一个轻量级的条件注入模块,将条件信号独立处理并注入到模型中。该模块基于 LoRA(Low-Rank Adaptation)技术,仅对条件分支进行低秩投影,而保持文本和噪声分支的权重不变,从而实现条件信号的高效注入。
- Position-Aware Training Paradigm:通过将输入条件标准化到固定分辨率,并采用位置感知插值(PAI)技术,使得模型能够学习任意宽高比和多分辨率的表示,同时优化了计算效率。
- Causal Attention Mechanism + KV Cache:将传统的全注意力机制替换为因果注意力机制,并结合 KV Cache 技术。在初始扩散时间步预计算并缓存所有条件特征的键值对,后续时间步直接复用这些缓存的键值对,从而大幅减少了计算量。
应用场景
- 虚拟试穿:结合服装图像和人体姿态图,生成虚拟试穿效果。例如,用户上传自己的照片和选择的服装,EasyControl 可以生成用户穿上该服装的逼真图像。
- 图像编辑:根据用户的指令(如“将背景替换为海滩”),结合输入的图像和编辑指令,生成符合要求的编辑后图像。
- 主体驱动的图像生成:根据输入的主体图像(如人物面部)和描述性文本,生成与主体一致的图像。例如,输入一张人脸和描述“在森林中”,生成该人物在森林中的图像。
- 空间控制生成:结合空间条件(如边缘图、深度图等)和文本描述,生成具有特定空间布局的图像。例如,根据边缘图生成具有相应形状和结构的图像。
- 多条件组合生成:同时结合多种条件(如 OpenPose 姿态图、面部图像等),生成满足所有条件的复杂图像。例如,生成一个具有特定姿态和面部特征的人物图像。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











