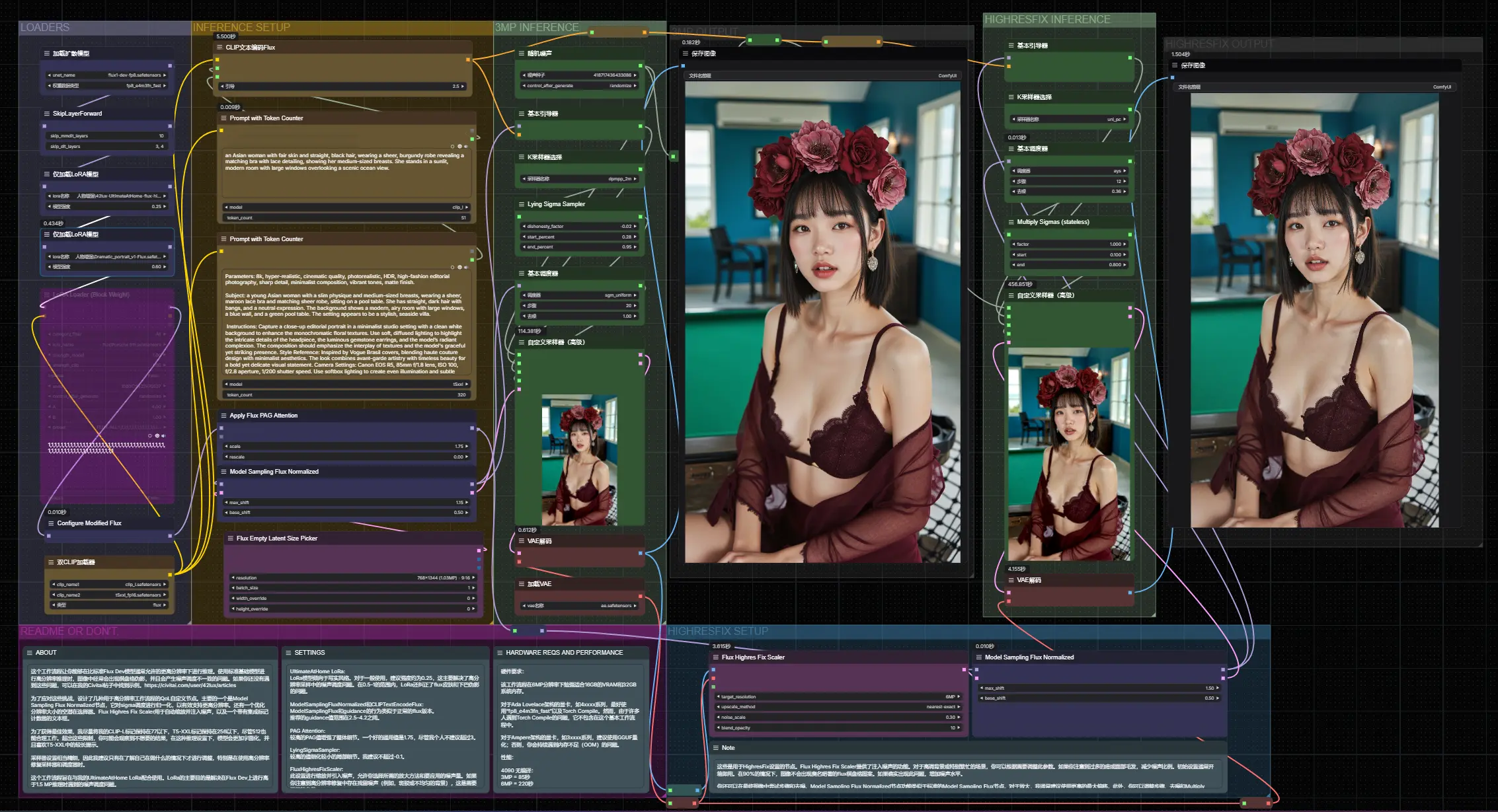
几个月前,我们曾介绍过 SVDQuant 技术 和其在 ComfyUI 中的应用。然而,由于当时写的不够详细,许多用户在尝试安装和运行相关插件时遇到了困难。如今,官方已经将 Nunchaku 的 ComfyUI 节点 独立出来,并提供了详细的安装和使用教程。本文将为大家梳理如何在 ComfyUI 上顺利安装和运行 Nunchaku 插件,并详细介绍关键节点的使用方法。
一、什么是 Nunchaku?
Nunchaku 是一个专为 4 位量化神经网络(SVDQuant) 设计的高效推理引擎,能够显著提升模型推理速度,同时降低显存占用。通过 Nunchaku,用户可以在 ComfyUI 中轻松加载和运行 SVDQuant 模型,也就是量化版的FLUX模型。

PS:本人使用的是B站UP主秋葉的ComfyUI整合包,如果你安装的是其他版本,也可以参考我的方法,差别不大。国内用户推荐使用秋葉ComfyUI整合包,更新及安装插件方便。
以下是详细的安装和配置步骤:
二、Nunchaku 安装方法
1. 安装前提
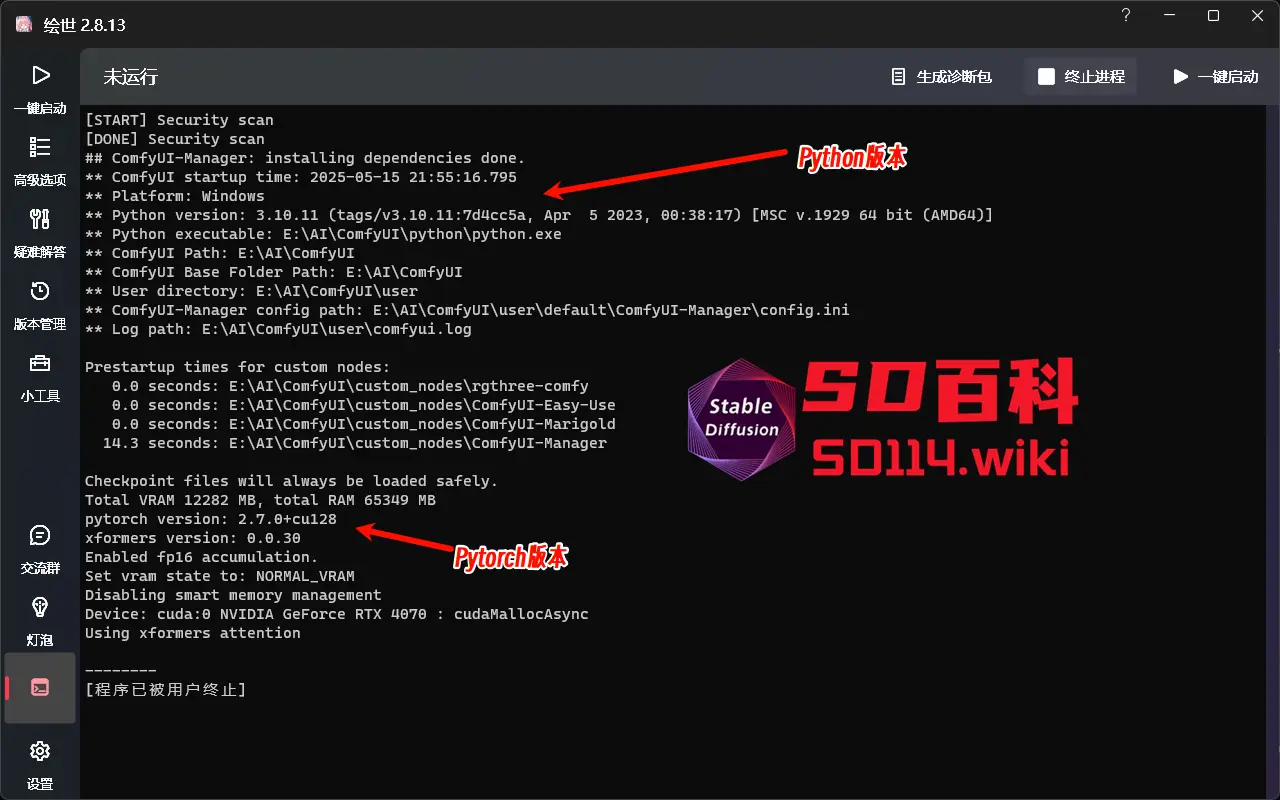
- Python 版本:确保你的 Python 版本与 Nunchaku 的 wheel 包兼容(例如 Python 3.10)。
- PyTorch 版本:
- 最低要求为 PyTorch >= 2.5。
- 如果你使用的是 英伟达50 系列显卡(Blackwell 架构),需要安装 PyTorch 2.7 或更高版本,使用FP4模型,其他显卡用户使用in4模型。
- Visual Studio:确保已安装最新版 Visual Studio,用于支持底层编译需求。
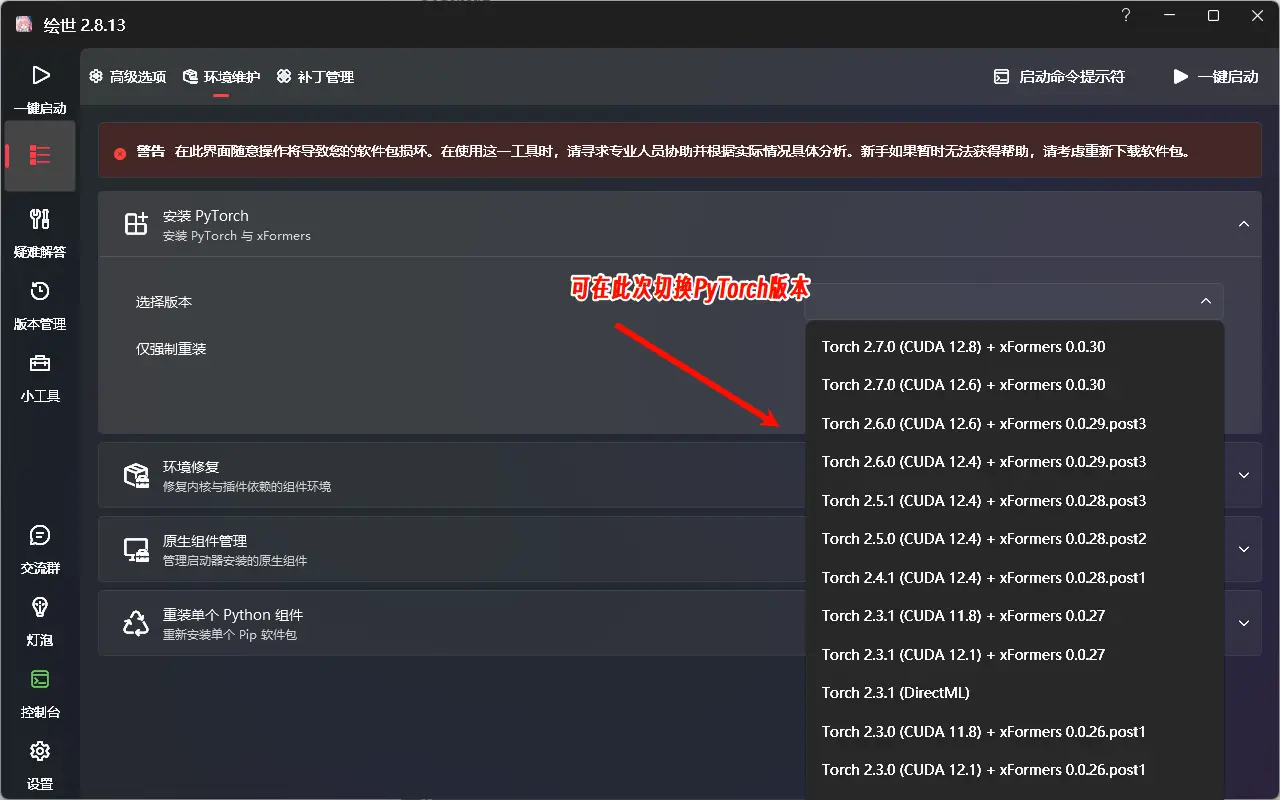
可以通过以下方式检查当前环境:
- 打开 ComfyUI 启动器,点击“一键启动”,查看 Python 和 PyTorch 版本信息。
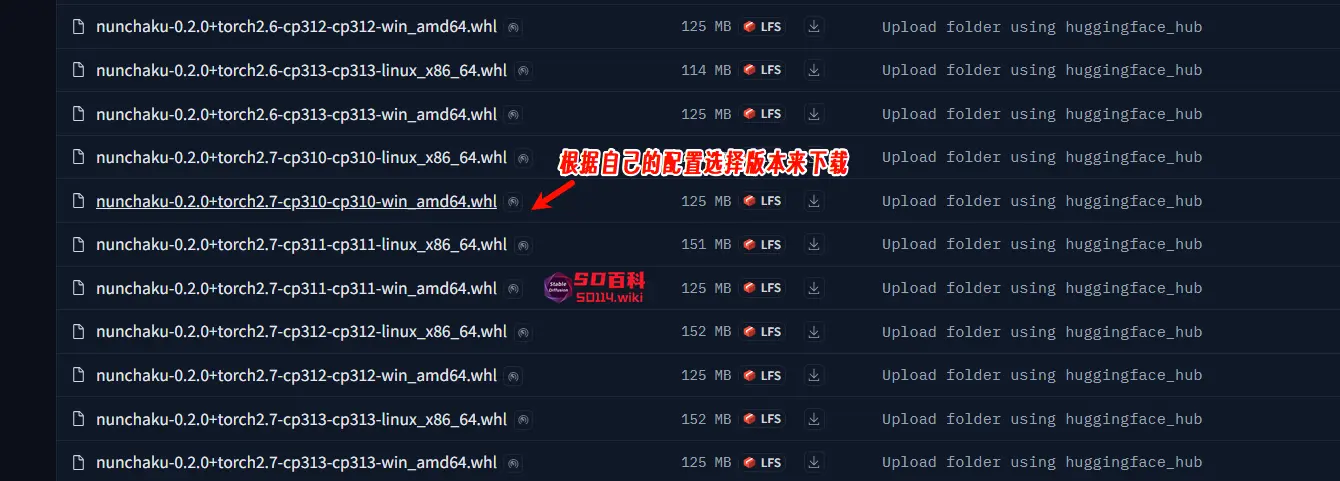
2. 下载对应的 Wheel 文件
- 前往 Hugging Face 或 魔塔,根据你的 Python 和 PyTorch 版本选择合适的 Nunchaku wheel 文件。
- 将下载的 wheel 文件放置在 英文路径目录 下,推荐直接放入 ComfyUI 的
python目录中(如ComfyUI\python)。
PS:国内用户请从魔塔下载
- Hugging Face :https://huggingface.co/mit-han-lab/nunchaku
- 魔塔:https://modelscope.cn/models/Lmxyy1999/nunchaku
v0.3.0 Dev版本
3. 安装 Wheel 文件
在 ComfyUI\python 目录下右键,选择“在终端中打开”
输入以下命令进行安装:
.\python.exe -m pip install 文件地址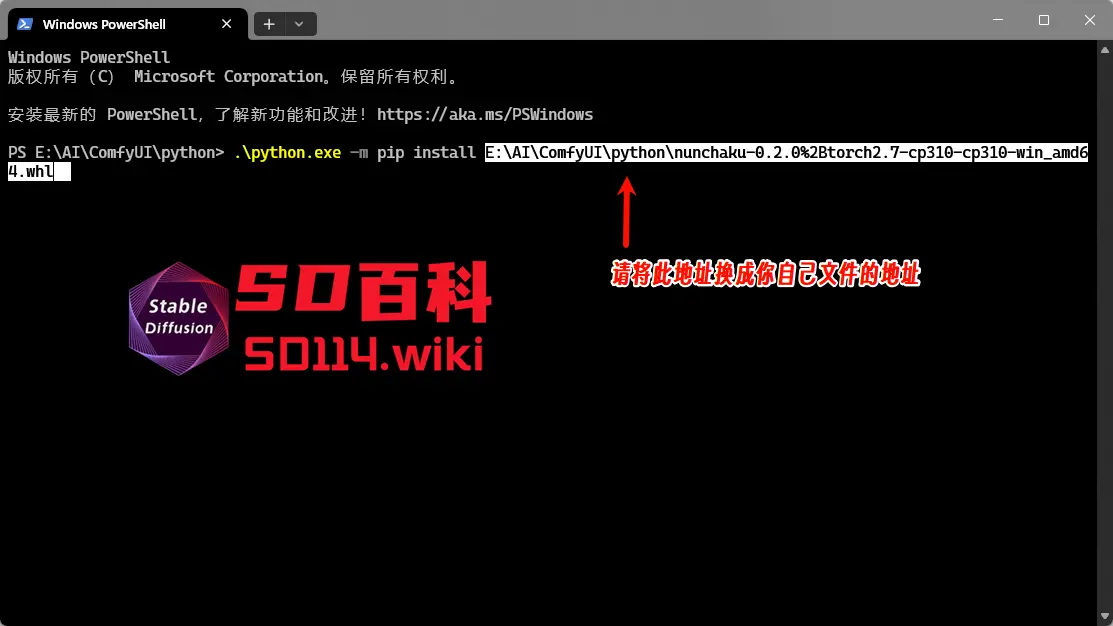
注意:
- 替换
文件地址为你下载的 wheel 文件的实际路径;右键点击 wheel 文件,复制文件地址 - 文件地址不要加双引号
"",否则可能导致安装失败。
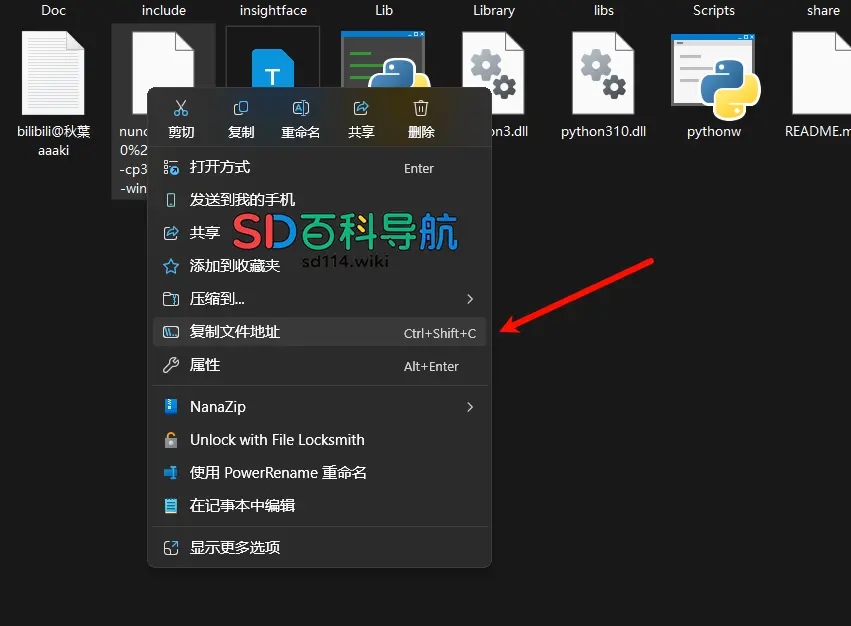
安装成功后,即可进入下一步。
三、安装 ComfyUI-nunchaku 插件
1. 使用 ComfyUI-Manager 安装
- 打开 ComfyUI-Manager,搜索
ComfyUI-nunchaku,点击安装即可。

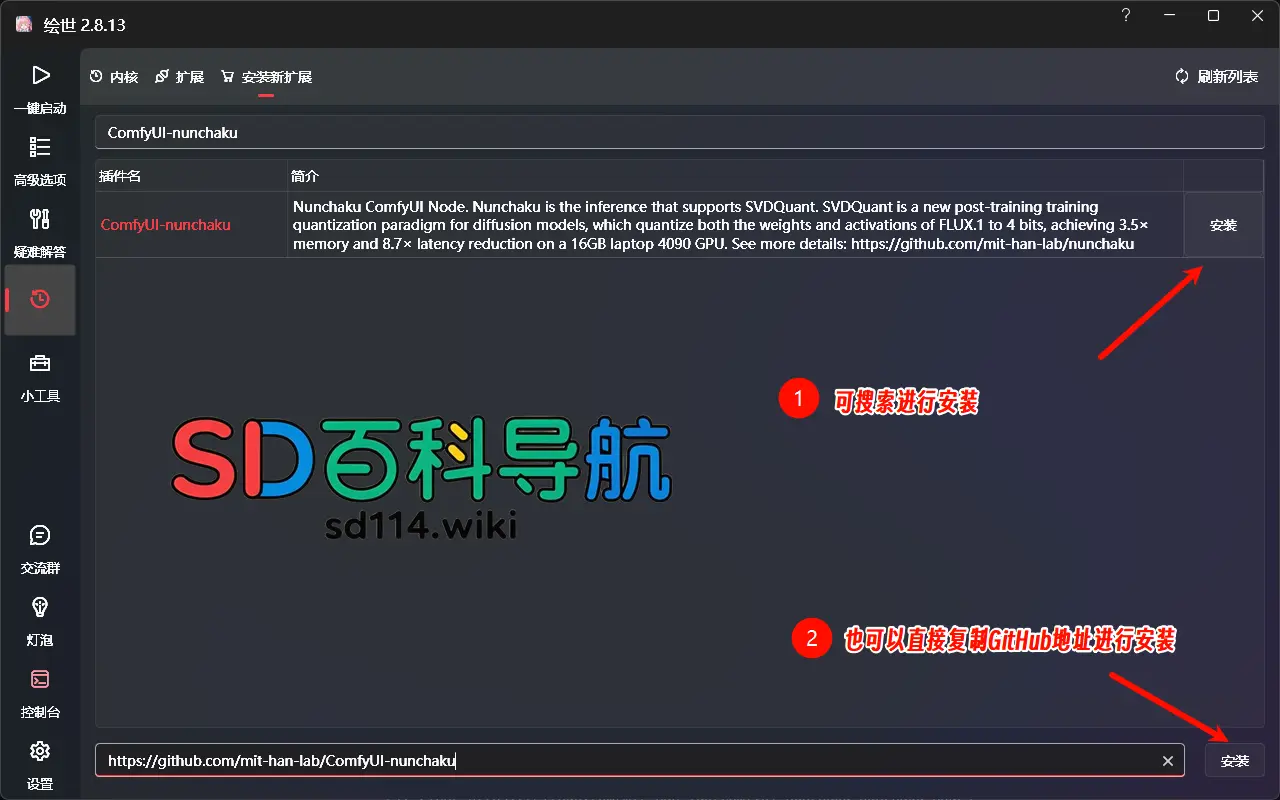
2. 秋葉整合包用户
- 在秋葉整合包中,进入“安装新扩展”页面,搜索
ComfyUI-nunchaku,点击安装。
四、如何使用 Nunchaku 插件
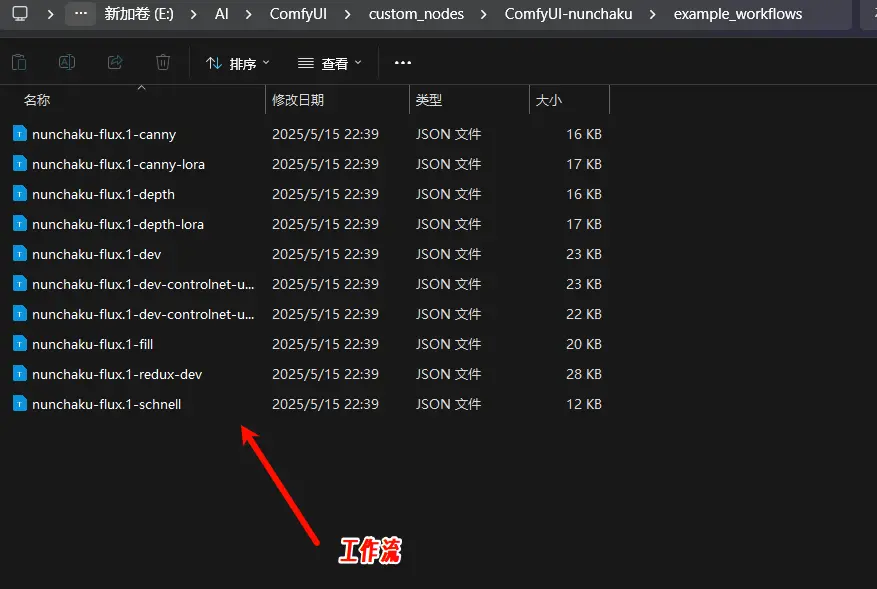
1. 配置工作流
- 官方已在
custom_nodes\ComfyUI-nunchaku\workflows目录下提供了示例工作流。 - 将工作流文件拖入 ComfyUI 即可快速加载。
- 如果缺少某些节点,可通过 ComfyUI-Manager 安装缺失的依赖。
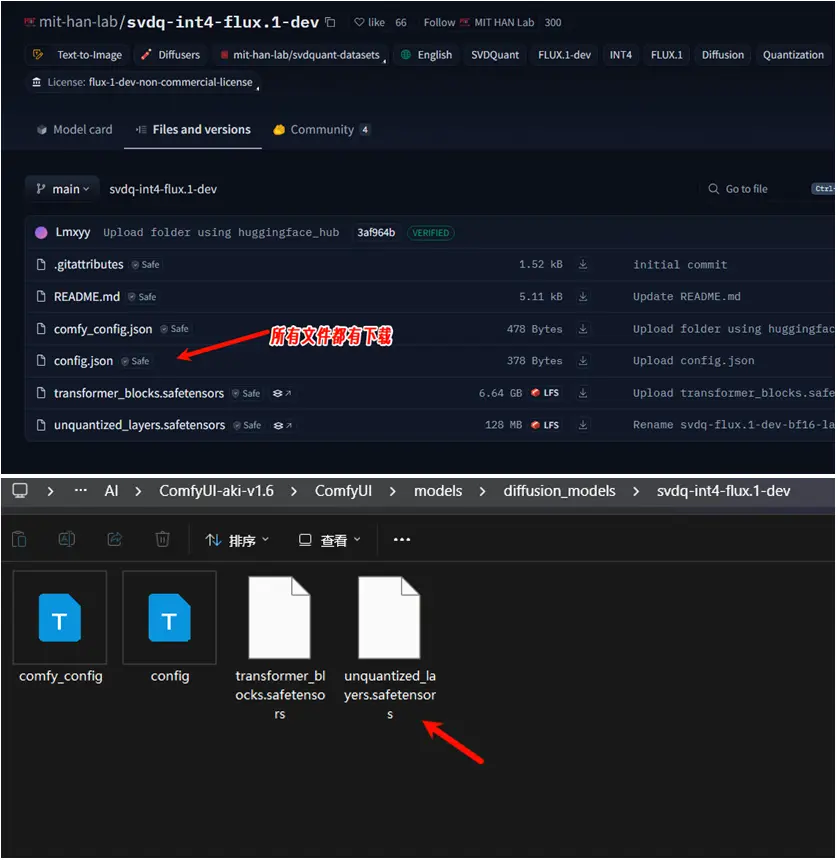
2. 下载必要模型
- 所有 4 位量化模型均可从 Hugging Face 或 魔塔下载。
- 下载后,将整个模型文件夹放入
models/diffusion_models目录中。
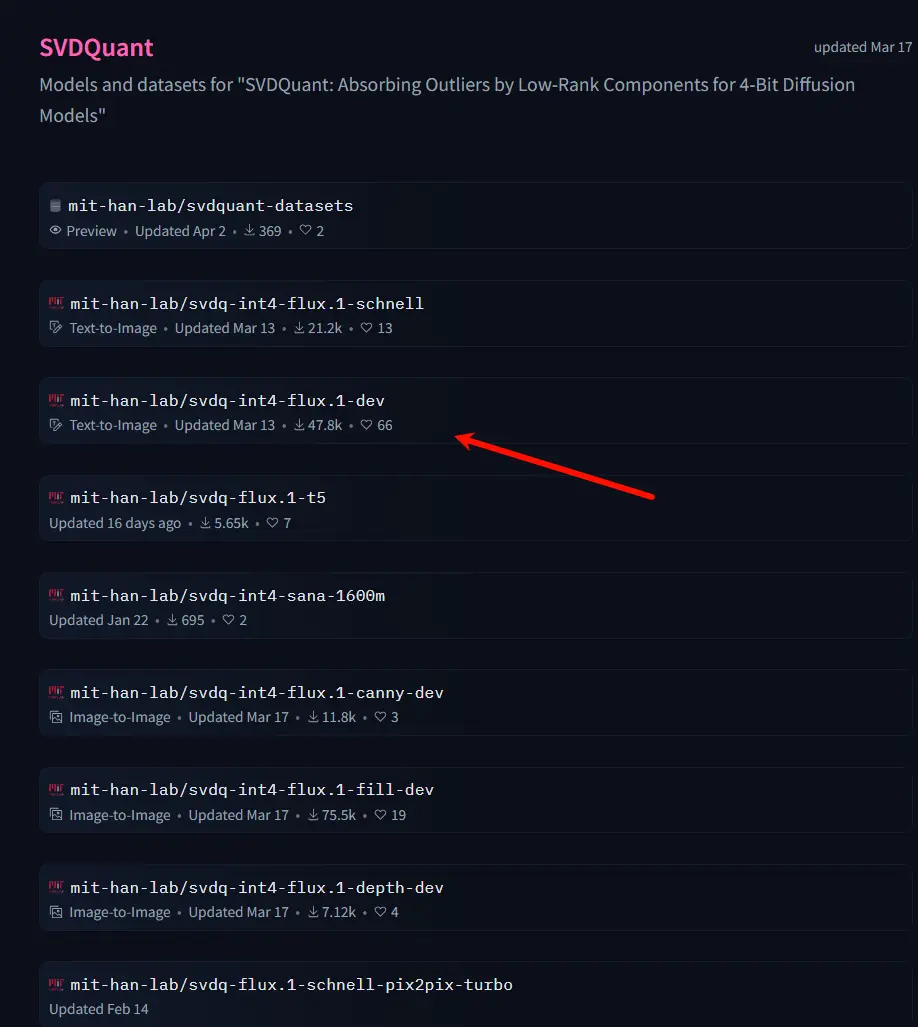
- Hugging Face:https://huggingface.co/collections/mit-han-lab/svdquant-67493c2c2e62a1fc6e93f45c
- 魔塔:https://modelscope.cn/collections/svdquant-468e8f780c2641
五、Nunchaku 关键节点详解
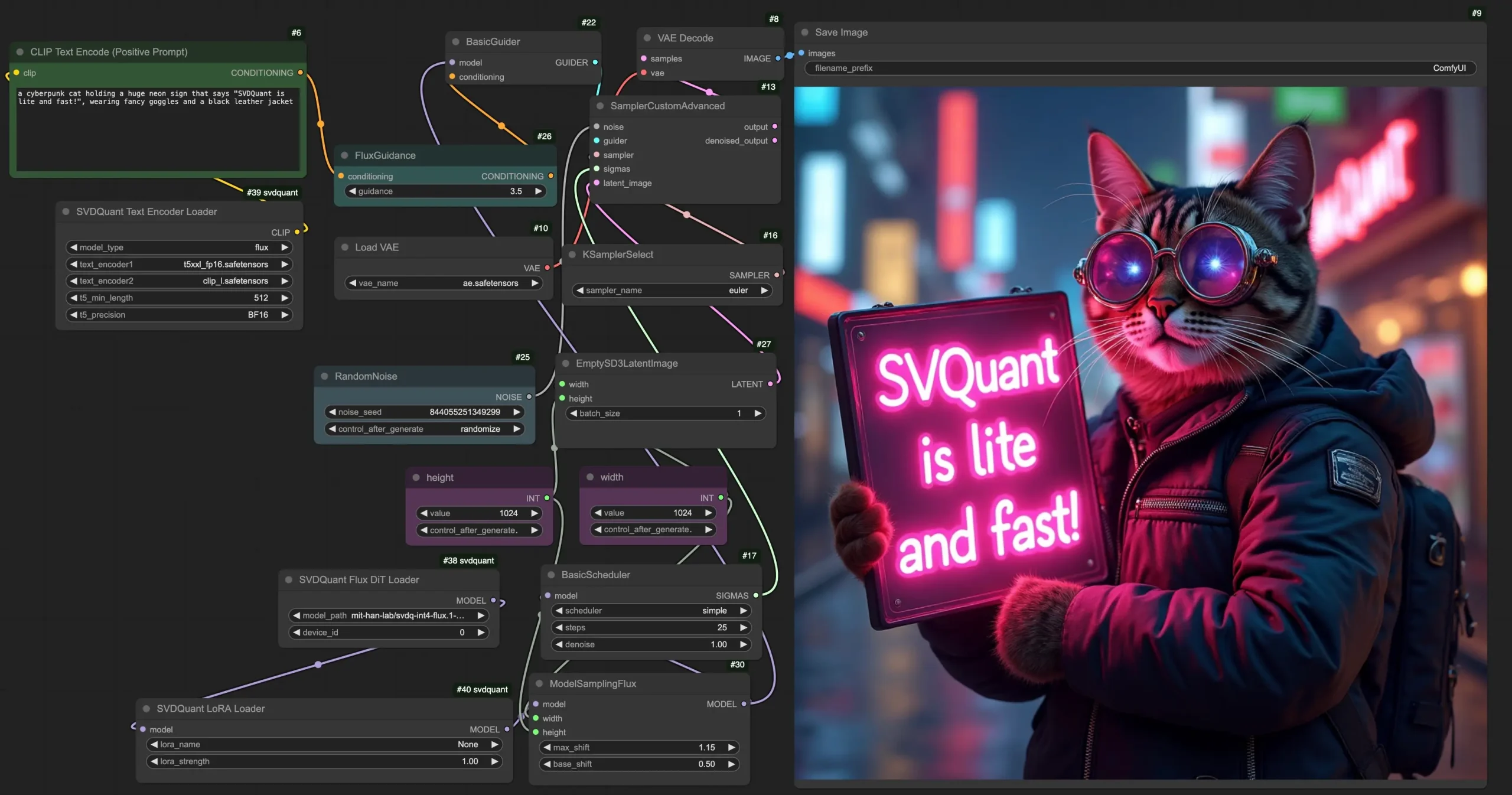
1. Nunchaku Flux DiT Loader
- 功能:用于加载 FLUX模型。
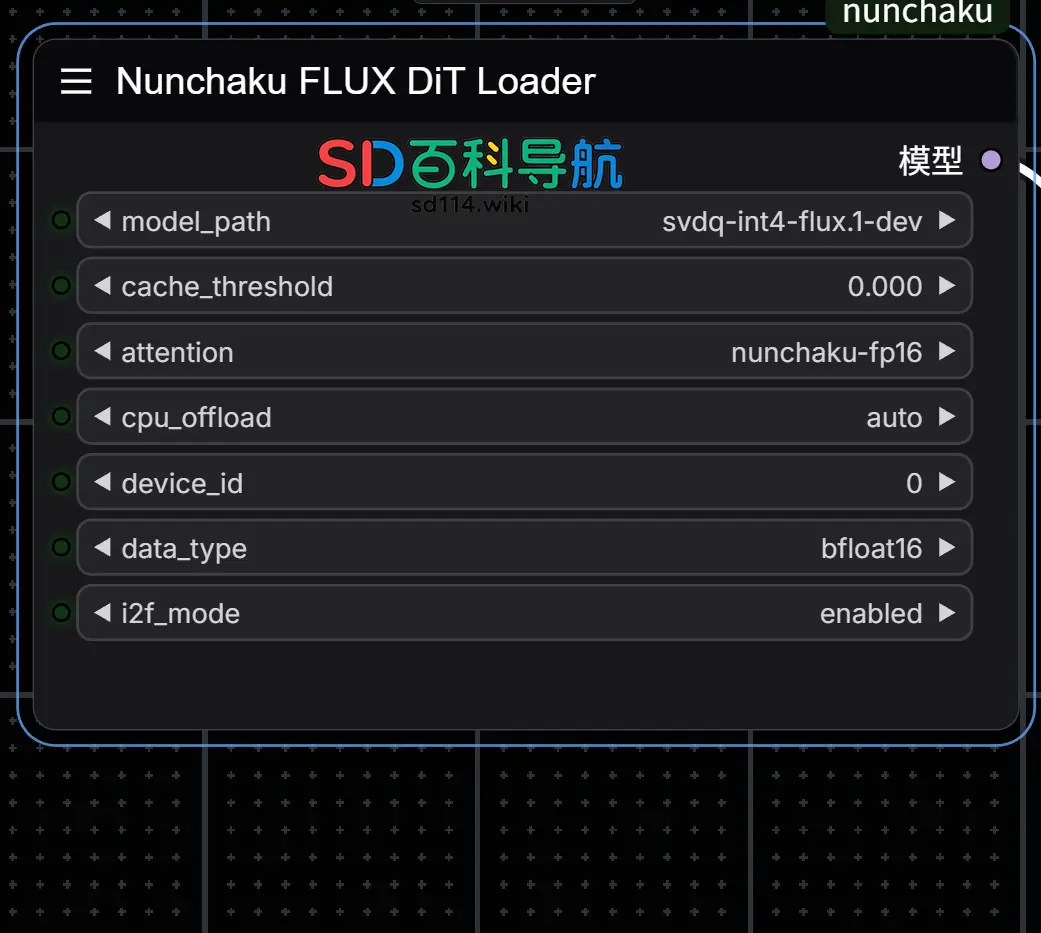
- 参数说明:
model_path:指定模型文件夹名称。cache_threshold:控制First-Block Cache的容差,类似于WaveSpeed中的residual_diff_threshold。增加此值可以提高速度,但可能会降低质量。典型值为 0.12。将其设置为 0 将禁用该效果。attention:定义 attention 的实现方法. 您可以在flash-attention2或nunchaku-fp16之间进行选择。nunchaku-fp16在不影响精度的情况下大约比flash-attention2快1.2x倍。对于Turing架构的显卡(20系), 如果不支持flash-attention2,则必须使用 nunchaku-fp16。flash-attention2:性能较高,但可能不支持所有硬件。nunchaku-fp16:在不影响精度的情况下,比flash-attention2快约 1.2 倍。
cpu_offload:启用 CPU 卸载以减少 GPU 显存占用。虽然这减少了GPU内存的使用,但它可能会减慢推理速度。- 设置为
auto时,系统会自动检测 GPU 内存。若内存超过 14GiB,则禁用卸载;否则启用。
- 设置为
device_id:指定使用的 GPU ID。data_type:定义去量子化张量的数据类型。- Turing 架构(20 系显卡)仅支持
float16。
- Turing 架构(20 系显卡)仅支持
i2f_mode:针对 20 系显卡的 GEMM 实现模式,其他架构 GPU 可忽略。
2. Nunchaku FLUX LoRA Loader
- 功能:用于加载 SVDQuant FLUX 模型的 LoRA 模型
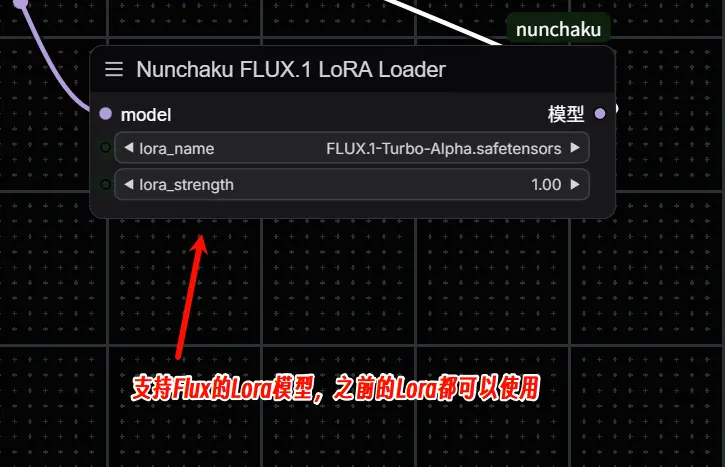
- 参数说明:
- 将 LoRA Checkpoints 文件放入
models/loras目录中。 lora_strength:控制 LoRA 模型的强度。- 支持连接多个 LoRA 节点。
- 注:从0.2.0版本开始,不需要转换LoRA了。可以在加载器中加载原始的LoRA文件
- 将 LoRA Checkpoints 文件放入
3. Nunchaku Text Encoder Loader
- 功能:用于加载文本编码器。
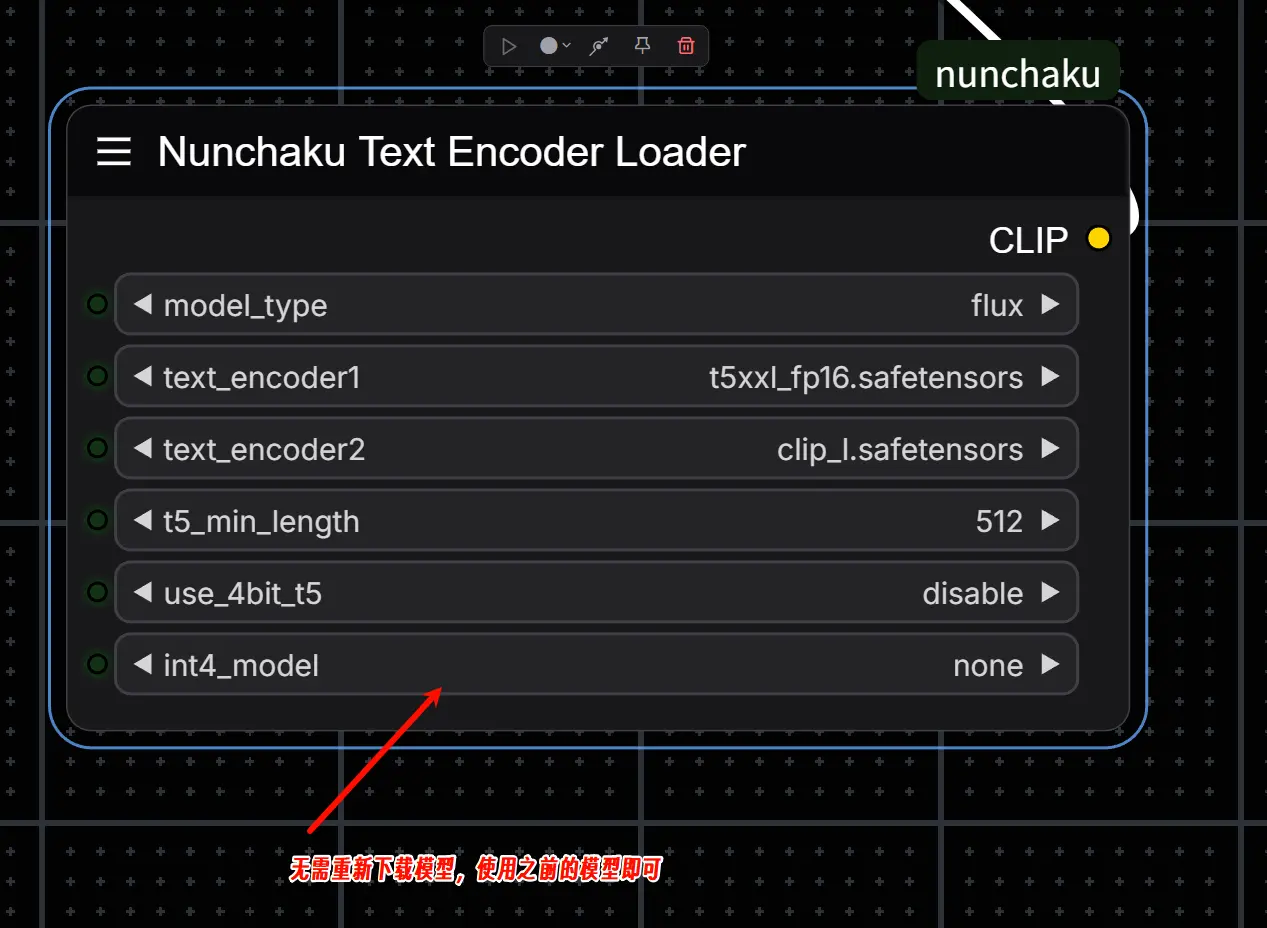
- 参数说明:
- 对于 FLUX 模型,请使用以下文件:
text_encoder1:t5xxl_fp16.safetensors(或 FP8/GGUF 版本)。text_encoder2:clip_l.safetensors。
t5_min_length:设置 T5 文本嵌入的最小序列长度,推荐值为512。use_4bit_t5:启用 4 位量化 T5 模型以节省显存。int4_model:指定 INT4 T5 模型的位置(仅在use_4bit_t5启用时使用)。
- 对于 FLUX 模型,请使用以下文件:
注意:目前加载 4-bit T5 模型可能会消耗较多内存,官方表示将在未来优化。
六、总结
通过上述步骤,你应该能够顺利安装和运行 Nunchaku 插件,并在 ComfyUI 中体验 SVDQuant 技术带来的高效推理能力。
PS:本人4070显卡,使用svdq-int4-flux.1-dev生成一张图,约7秒;其他工作流大家可自行测试。
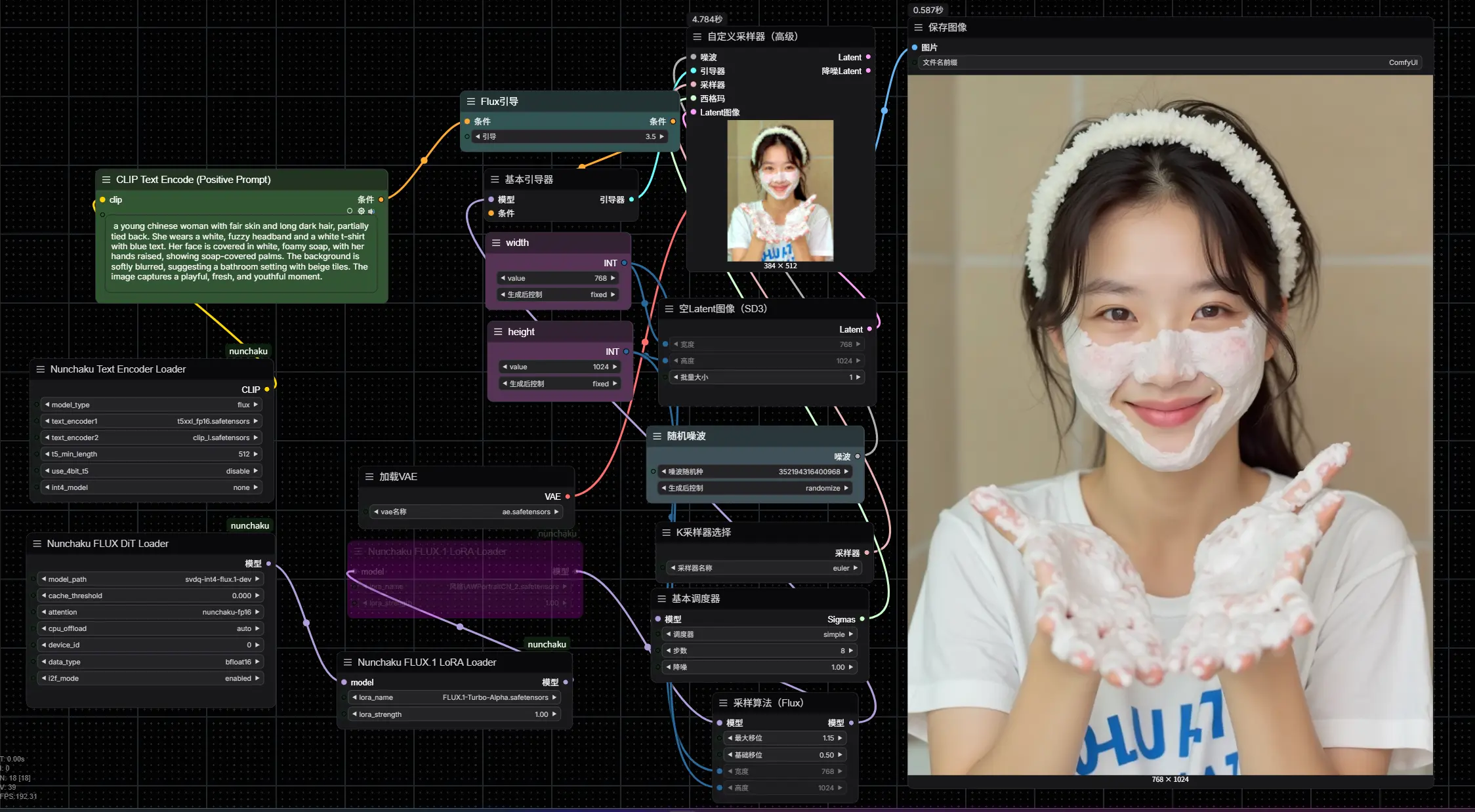
svdq-int4-flux.1-dev生成一张图,约7秒
如果你在安装或使用过程中遇到任何问题,可以参考官方 GitHub 页面的文档和视频教程,或者在留言寻求帮助。

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











