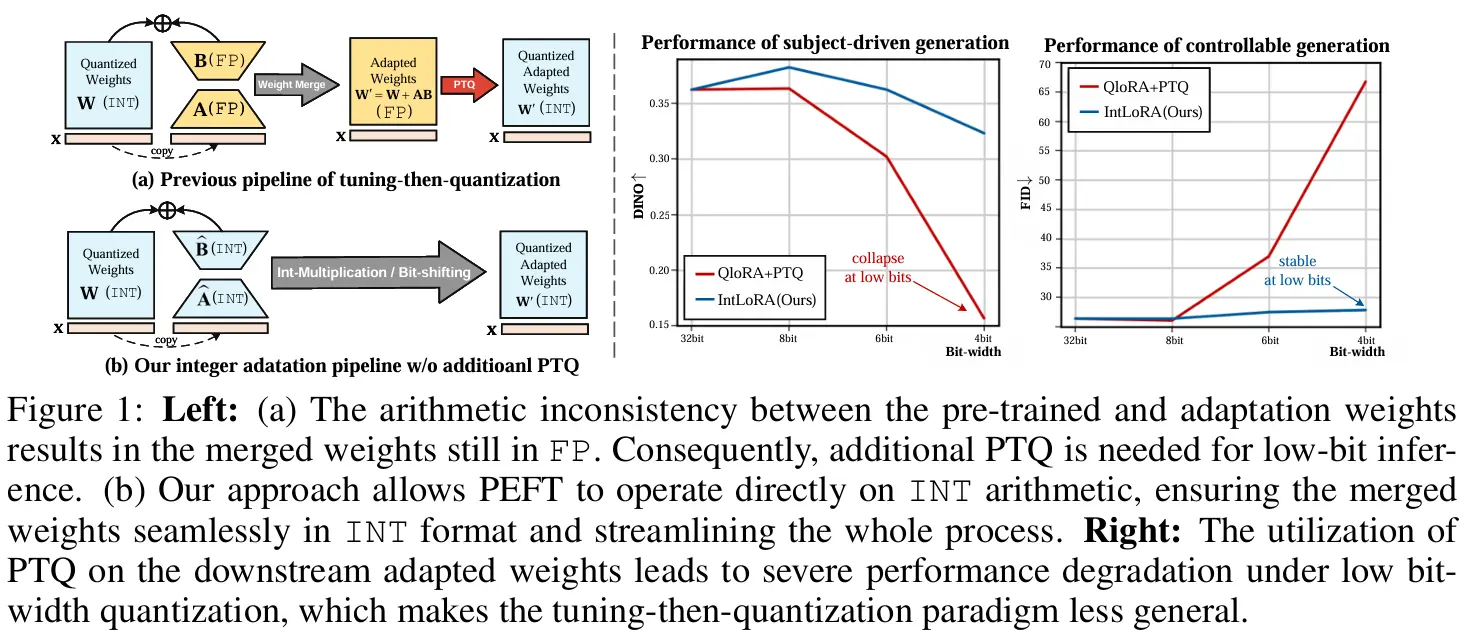
近年来,文生图模型在各种下游任务中取得了显著的成果。然而,微调这些大型模型所需的计算资源非常庞大,限制了其在个性化定制和实际应用中的普及。为了解决这一问题,研究人员开始探索参数高效微调(PEFT)技术,通过少量参数的调整来适应预训练模型。尽管已有研究尝试使用浮点(FP)或量化的预训练权重进行微调,但这些方法仍然受限于FP算术,未能充分利用硬件加速的优势。
在此背景下,清华大学、苏黎世联邦理工学院、深圳大学和鹏程实验室的研究人员提出了一种新的方法——IntLoRA,通过使用整数类型(INT)的低秩参数来适应量化扩散模型,进一步提升了微调的效率。
IntLoRA 的关键优势
减少内存使用:在微调过程中,预训练权重被量化为整数类型,显著减少了内存占用。这对于大规模模型尤其重要,因为它们通常需要大量的内存资源。 节省磁盘空间:预训练权重和低秩权重均以整数形式存储,相比浮点数格式,整数格式占用的磁盘空间更少。这使得模型更容易在资源有限的设备上部署和运行。 高效的推理:在推理阶段,IntLoRA 的整数权重可以直接合并到量化预训练权重中,无需额外的训练后量化步骤。整数乘法和位移操作在现代硬件上通常具有更高的效率,从而加速了模型的推理速度。
主要特点:
适应量化:IntLoRA将适应参数转换为整数算术,使得预训练权重和适应权重可以无缝合并,无需额外的量化步骤。 适应量化分离(AQS):通过引入辅助矩阵,IntLoRA允许在保持梯度的同时进行量化友好的参数调整。 乘法低秩适应(MLA):将原始的加法形式的LoRA转换为乘法形式,允许独立优化适应权重,消除了与预训练权重共享量化器的需要。 方差匹配控制(VMC):通过调整辅助矩阵的方差,控制适应分布,使得对数量化更加有效。
工作原理:
IntLoRA通过以下步骤工作:
量化预训练权重:将预训练的浮点数(FP)权重量化为整数(INT)形式,减少内存使用。 适应量化分离:引入辅助矩阵R,使得适应权重可以在不直接影响梯度的情况下进行量化。 乘法低秩适应:将适应权重与预训练权重的更新通过乘法而非加法结合,使得两者可以独立量化。 方差匹配控制:调整辅助矩阵R的方差,使得适应权重的分布适合对数量化。

实验验证
研究人员进行了广泛的实验,验证了IntLoRA 在多个任务上的性能。实验结果表明,IntLoRA 不仅能够实现与原始LoRA 相当甚至更优的性能,而且在内存使用、磁盘空间和推理速度等方面都表现出显著的优势。
技术细节
IntLoRA 的核心技术包括:
量化预训练权重:将预训练模型的权重从浮点数格式量化为整数格式,减少内存占用。 整数低秩参数:引入低秩参数矩阵,并将其量化为整数格式,用于微调模型。 高效整数运算:在推理过程中,通过高效的整数乘法和位移操作,将低秩参数自然地合并到量化预训练权重中,避免额外的量化步骤。
应用前景
IntLoRA 的推出为大规模文本到图像扩散模型的微调带来了新的可能性。其在内存使用、磁盘空间和推理速度方面的显著优势,使得这些模型更容易在资源有限的设备上部署和运行。具体应用场景包括:
移动设备:IntLoRA 可以在智能手机和平板电脑上实现高性能的图像生成,提升用户体验。 边缘计算:在边缘设备上部署IntLoRA 模型,可以实现低延迟的图像生成和处理,适用于实时应用场景。 云计算:在云环境中,IntLoRA 可以显著减少服务器的内存和存储需求,降低运营成本。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











