
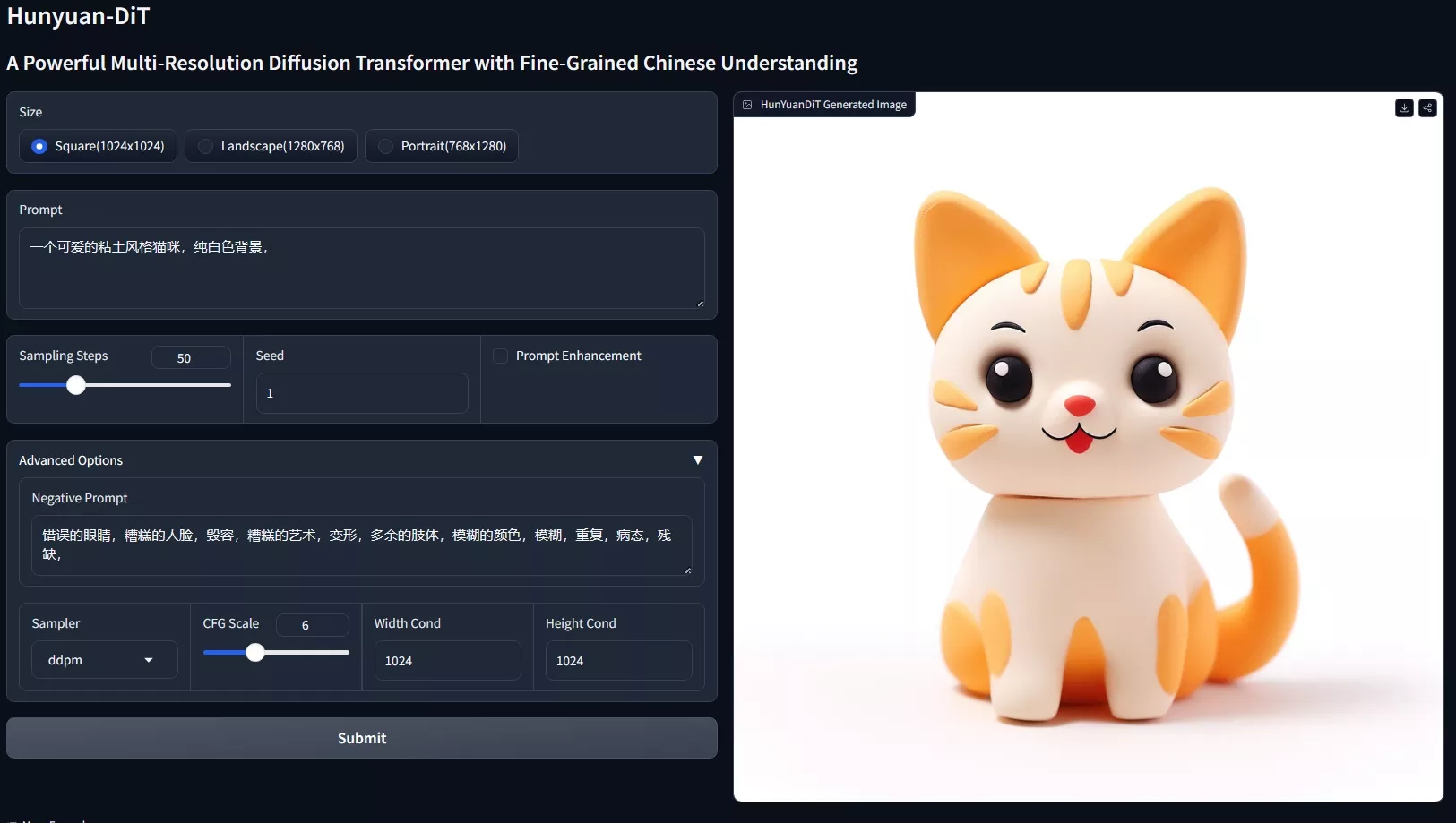
腾讯混元团队推出支持中英双语提示词的文生图模型Hunyuan-DiT,它特别擅长理解中文和英文的文本提示,并据此生成图像,Hunyuan-DiT能够根据上下文与用户进行多轮多模态对话,生成并优化图像。

例如,一个用户想要生成一张“中国古典园林中荷花盛开的景象”的图片,他可以通过 Hunyuan-DiT 输入这段描述性的中文文本,模型就会生成一张符合描述的图像。如果用户对生成的图像有特定的要求或想要进行一些调整,还可以通过多轮对话与模型交互,逐步优化图像的细节。
- 项目主页:https://dit.hunyuan.tencent.com
- GitHub:https://github.com/Tencent/HunyuanDiT
- 模型地址:https://huggingface.co/Tencent-Hunyuan/HunyuanDiT
- 官方地址:https://image.hunyuan.tencent.com/authorize
- Demo:https://huggingface.co/spaces/multimodalart/HunyuanDiT
- Colab:https://github.com/camenduru/HunyuanDiT-jupyter
主要功能:
- 文本到图像的生成:用户可以输入一段描述性的文本,Hunyuan-DiT 能够根据这段文本生成相应的图像。
- 多分辨率生成:模型能够根据不同的分辨率要求,生成不同清晰度的图像。
- 多轮对话交互:Hunyuan-DiT 支持与用户进行多轮对话,根据对话内容逐步优化生成的图像。
主要特点:
- 双语理解:它结合了双语 CLIP(Contrastive Language-Image Pre-training)和多语言 T5 编码器,以提高对输入文本的理解。
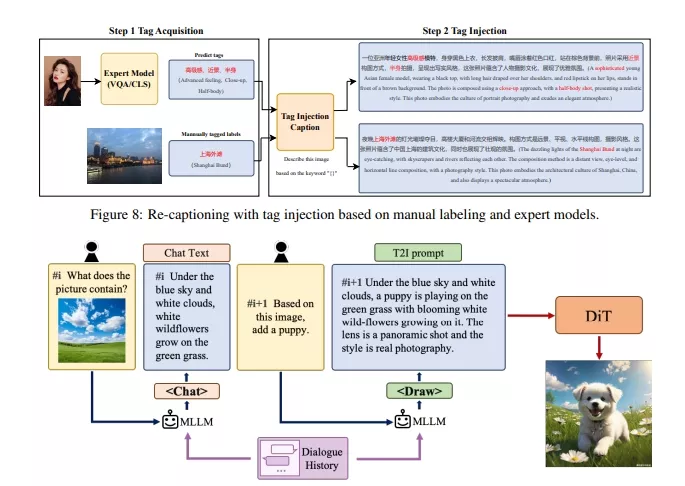
- 数据流水线:构建了全新的数据处理流程,包括数据获取、解释、分层和应用,以迭代优化模型。
- 大型多模态语言模型:使用多模态大型语言模型(MLLM)来提炼和改进图像的标题,增强数据质量。
- 多轮对话能力:通过与用户的多轮对话,模型能够更好地理解用户的意图,并生成更准确的图像。
工作原理:
- 变分自编码器(VAE):首先使用预训练的 VAE 将图像压缩到低维潜在空间。
- 扩散模型:接着训练一个扩散模型来学习数据分布,该模型使用变换器(transformer)进行参数化。
- 文本编码:利用双语 CLIP 和多语言 T5 编码器来编码文本提示。
- 位置编码:使用旋转位置嵌入(RoPE)来编码图像域中的绝对位置和相对位置依赖。
- 多分辨率支持:通过扩展位置编码和集中插值位置编码来支持不同分辨率的图像生成。
- 训练稳定性:采用特定的技术来稳定训练过程,如 QK-Norm 和 FP32 以避免数值错误。
硬件要求:
官方模型库包含两个模型:DialogGen(提示增强模型)和 Hunyuan-DiT(文生图模型),腾讯后续还将更新TensorRT 版本
- DialogGen + Hunyuan-DiT需要32G显存才能运行
- Hunyuan-DiT需要11G显存才能运行

© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











