Meta推出多模态基础模型家族Chameleon,它们是专为理解和生成图像与文本而设计,多模态意味着这些模型能够同时处理多种类型的数据,比如图片和文字。例如,你给Chameleon一个描述或者一张图片,它能够生成相关的文本,或者反过来,给你一个文本描述,它能够创造出相应的图片。总的来说,Chameleon模型的推出标志着在统一建模多模态文档方面迈出了重要的一步,它能够灵活地处理和生成混合了多种内容形式的文档。
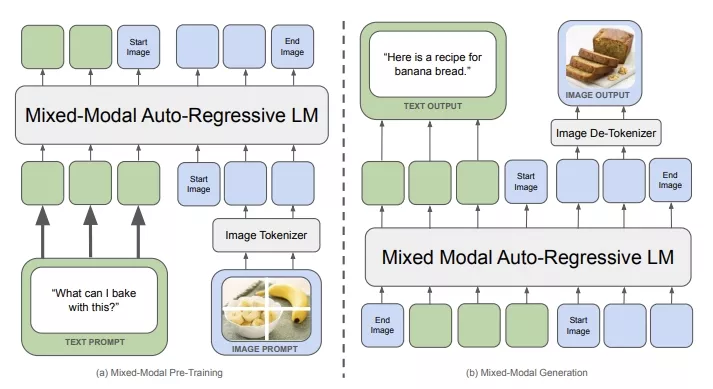
Chameleon是一个基于早期融合令牌的混合模态模型家族,它能够理解和生成任何任意序列的图像和文本。Meta从概念设计开始,概述了一种稳定的训练方法,包括一套对齐方案和针对早期融合、基于令牌的混合模态设置量身定制的架构参数化。这些模型在广泛的任务上进行了评估,包括视觉问题回答、图像描述生成、文本生成、图像生成以及长格式混合模态生成。Chameleon展现了广泛且全面的能力,包括在图像描述生成任务中达到最先进性能,同时在仅文本任务中超越Llama-2,并且与Mixtral 8x7B和Gemini-Pro等模型具有竞争力。此外,它还能够执行非平凡的图像生成,所有功能都集成在一个模型中。根据人类对新长格式混合模态生成评估的判断,Chameleon的表现与甚至超过了包括Gemini Pro和GPT-4V在内的大型模型,其中提示或输出均包含图像和文本的混合序列。Chameleon标志着在全多模态文档统一建模领域取得了重大进步。
主要功能:
- 图像和文本的理解与生成:Chameleon能够处理混合了图像和文本的复杂任务,比如根据一张图片生成描述性的文本,或者根据一段描述生成相应的图片。
- 多任务学习:它在多种不同的任务上都表现出色,包括视觉问题回答、图像字幕生成、文本生成、图像生成以及长形式的混合模态生成。
主要特点:
- 早期融合:Chameleon采用了一种称为早期融合的方法,这意味着它从一开始就将所有模态(图像、文本等)投影到一个共享的表示空间中,从而实现无缝的跨模态推理和生成。
- 统一架构:它使用统一的架构来处理所有类型的数据,不需要为每种模态单独设计编码器或解码器。
- 优化稳定性:通过一系列架构创新和训练技术,Chameleon解决了早期融合模型在优化稳定性和扩展性方面的重大技术挑战。
工作原理:
Chameleon模型通过将图像量化为离散的标记(类似于文本中的单词),然后使用变换器架构(一种深度学习模型)来处理这些图像和文本标记的序列。这种方法允许模型以统一的方式理解和生成混合了图像和文本的内容。
具体应用场景:
- 视觉问题回答:用户可以上传一张图片,并提出与图片相关的问题,Chameleon能够提供准确的答案。
- 图像字幕生成:给定一张图片,Chameleon能够生成描述图片内容的文本。
- 创意内容生成:用户可以提供一个文本提示,Chameleon能够根据这个提示创造出新的图像。
- 长形式内容生成:Chameleon能够处理包含大量图像和文本的长篇文章或报告的生成。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...