
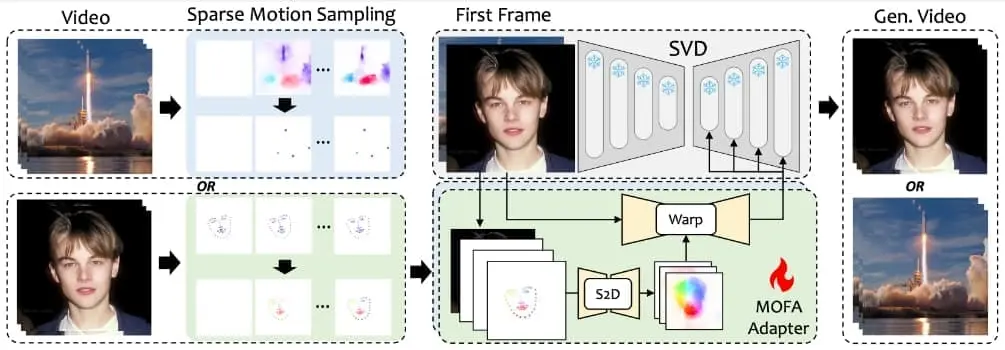
来自东京大学和腾讯AI实验室推出新型可控图像动画方法MOFA-Video,能够根据给定的图像和额外的可控信号(例如人体标记、手动轨迹或提供的其他视频)或它们的组合,从给定的图像中生成视频。这与以往的方法不同,以往的方法只能在特定的运动领域工作,或者在扩散先验下显示出较弱的控制能力。
- 项目主页:https://myniuuu.github.io/MOFA_Video
- GitHub:https://github.com/MyNiuuu/MOFA-Video
- 模型地址:https://huggingface.co/MyNiuuu/MOFA-Video-Traj
为了实现目标,开发人员设计了几种领域感知的运动场适配器(即,MOFA-适配器),在视频生成流程中控制生成的运动。对于MOFA-适配器,开发人员首先考虑视频的时间运动一致性,从给定的稀疏控制条件下生成密集的运动流,然后将给定图像的多尺度特征包裹为引导特征,以实现稳定的视频扩散生成。鉴于手动轨迹和人体关键点都包含了关于控制的稀疏信息,开发人员直观地分别为这两种情况训练了两个运动适配器。训练完成后,不同领域的MOFA-适配器可以协同工作,实现更可控的视频生成。

例如,你是一名动画制作者,想要将一张静态图片中的人物制作成动画。使用MOFA-Video,你可以简单地提供一张图片和一些控制信号,比如人物面部的关键点或者人物的运动轨迹。MOFA-Video将根据这些信息生成一个动画视频,其中人物的动作和表情会根据你提供的控制信号进行动画化。这种方法不仅快速,而且可以生成非常自然和逼真的动画效果,非常适合需要快速动画制作或个性化动画内容的场景。
主要功能:
- 可控图像动画: MOFA-Video可以根据用户提供的控制信号生成视频,这些信号可以是手动绘制的轨迹、人体标记序列,甚至是其他提供的视频。
- 多种适配器: 论文中设计了几种领域感知的运动场适配器(MOFA-Adapters),用于控制视频生成流程中的生成动作。
主要特点:
- 零样本组合: 不同领域的MOFA-Adapters可以在不重新训练的情况下一起工作,实现更可控的视频生成。
- 时间运动一致性: 在考虑视频的时间运动一致性的同时,从给定的稀疏控制条件生成密集的运动流。
- 多尺度特征引导: 利用给定图像的多尺度特征作为稳定视频扩散生成的引导特征。
工作原理:
- 稀疏到密集的运动生成网络(S2D): 首先使用给定的稀疏运动提示生成密集的运动场。
- 参考图像编码器: 提取第一帧的多尺度特征,用于后续的图像变形和生成过程。
- 特征融合编码器: 将变形的特征添加回预训练的视频扩散模型中,以进行生成指导。
具体应用场景:
- 手动轨迹动画: 用户可以手动绘制轨迹,MOFA-Video根据这些轨迹生成动画。
- 面部标记序列动画: 使用如SadTalker这样的工具从音频生成面部标记序列,然后MOFA-Video可以根据这些标记序列生成面部动画。
- 组合适配器: 可以同时使用多个MOFA-Adapters,例如结合手动轨迹和人体标记,以实现更复杂的动画效果。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











