
英伟达推出新型文生图模型BlobGEN,这个模型的核心思想是将场景分解为视觉原语——被称为密集的blob(斑点)表示——这些表示包含了场景的细粒度细节,同时具备模块化、易于理解和构建的特点。例如,一个用户想要生成一幅画有“海滩上的日落”的图像。在BlobGEN中,用户可以创建几个斑点表示:一个斑点代表海滩,其参数指定了海滩的位置和大小,描述则可能包含“金色的沙滩”和“平静的海浪”;另一个斑点代表太阳,参数定义了太阳在天空中的位置和大小,描述可能是“橙色的圆盘”和“温暖的阳光”。然后,BlobGEN会根据这些斑点表示生成一幅图像,其中包含了用户描述的视觉元素和布局。如果用户想要调整图像,比如移动太阳的位置或改变海滩的颜色,他们只需修改相应的斑点表示,BlobGEN会相应地更新生成的图像。

主要功能:
- BlobGEN能够根据文本提示生成图像,并且能够更好地控制生成的图像的布局和内容。
- 它支持零样本生成(zero-shot generation),即在没有见过特定类别图像的情况下,也能根据文本描述生成相应的图像。
主要特点:
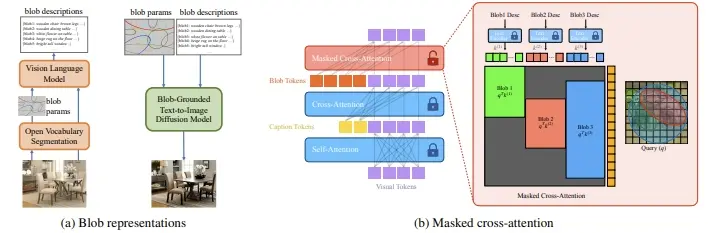
- 密集的blob表示:BlobGEN使用由斑点参数和斑点描述组成的斑点表示来引导图像生成。斑点参数定义了斑点的位置、大小和方向,而斑点描述则用文本描述斑点的外观和属性。
- 模块化和可解释性:由于斑点表示是模块化的,用户可以容易地编辑或操作图像的特定部分。
- 新的masked cross-attention模块:这个模块允许模型在局部区域内将斑点表示与视觉特征相融合,提高了生成过程的可控性。
工作原理:
- 图像分解:首先,BlobGEN将输入图像分解为一系列的斑点表示,每个斑点表示对应场景中的一个视觉原语(例如一个物体)。
- 斑点嵌入:斑点参数和斑点描述被编码成嵌入向量,这些向量随后被输入到生成模型中。
- masked cross-attention:在生成过程中,模型使用masked cross-attention机制,确保每个斑点仅与其对应的视觉特征进行交互,从而保持了图像生成的局部性和模块化。
- LLM辅助:BlobGEN还设计了一种新的上下文学习方法,利用大型语言模型(LLMs)从文本提示中生成斑点表示,这增强了模型在复杂图像生成任务中的表现。
具体应用场景:
- 艺术创作:艺术家和设计师可以使用BlobGEN来生成符合他们想象中的图像,或者对现有图像进行编辑和调整。
- 游戏和电影制作:在游戏和电影的制作过程中,BlobGEN可以用来快速生成或修改场景和角色的视觉元素。
- 虚拟现实:在虚拟现实环境中,BlobGEN可以根据用户的描述生成或调整虚拟环境的元素。
- 教育和培训:BlobGEN可以用于教育领域,帮助学生理解复杂概念的视觉表示,或者在培训中生成教学材料。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











