来自微软亚洲研究院、清华大学、北京大学和澳大利亚国立大学的研究团队推出文本编码器Glyph-ByT5,它是为了提高视觉文本渲染的准确性而设计的。Glyph-ByT5通过微调一个字符感知的ByT5编码器,并使用精心策划的配对字形-文本数据集进行训练,以增强其对字形(glyphs)的认识和对齐能力。
- 项目主页:https://glyph-byt5.github.io
- GitHub:https://github.com/AIGText/Glyph-ByT5
- 模型:https://huggingface.co/GlyphByT5/Glyph-SDXL
Glyph-ByT5与现有的文本编码器相比,在视觉文本渲染方面的性能提升是显著的。具体来说,Glyph-ByT5在设计图像基准测试中的文本渲染准确率从不到20%提高到近90%。这一提升是通过将Glyph-ByT5与SDXL模型集成得到的Glyph-SDXL模型实现的。

主要功能和特点:
- 字符感知和字形对齐: Glyph-ByT5能够识别和处理文本中的每个字符,并将其与视觉字形对齐,这对于精确渲染文本至关重要。
- 集成到SDXL模型中: 通过与SDXL模型结合,Glyph-ByT5显著提高了设计图像生成中的文本渲染准确性,将准确率从不到20%提高到近90%。
- 段落文本渲染: Glyph-ByT5能够处理包含数十到数百个字符的文本段落,并自动进行多行布局规划。
工作原理:
- 数据集构建: 为了训练Glyph-ByT5,研究者们创建了一个包含约100万对合成数据的字形-文本数据集,这些数据集通过图形渲染技术生成。
- 字形增强策略: 为了提高文本编码器对字符的感知能力,研究者们采用了字形增强策略,包括字符替换、重复、删除和添加等。
- 微调ByT5: 使用上述数据集和一种新颖的框级对比损失函数,研究者们有效地将ByT5微调成一个系列化的定制文本编码器,即Glyph-ByT5。
- 与SDXL集成: 通过一个高效的区域级交叉注意力机制,Glyph-ByT5被无缝集成到SDXL模型中,显著提升了原始扩散模型的文本渲染性能。

具体应用场景:
- 设计图像生成: Glyph-ByT5可以用于生成包含丰富文本内容的设计图像,如海报、卡片和宣传册。
- 场景文本渲染: 通过微调Glyph-SDXL模型,Glyph-ByT5能够生成包含场景文本的真实感图像,如路标、广告牌或文本密集的T恤上的文本。
- 文本编辑和修正: Glyph-ByT5还可以用于编辑现有图像中的文本,例如修正DALL·E3生成的图像中的文本样式。
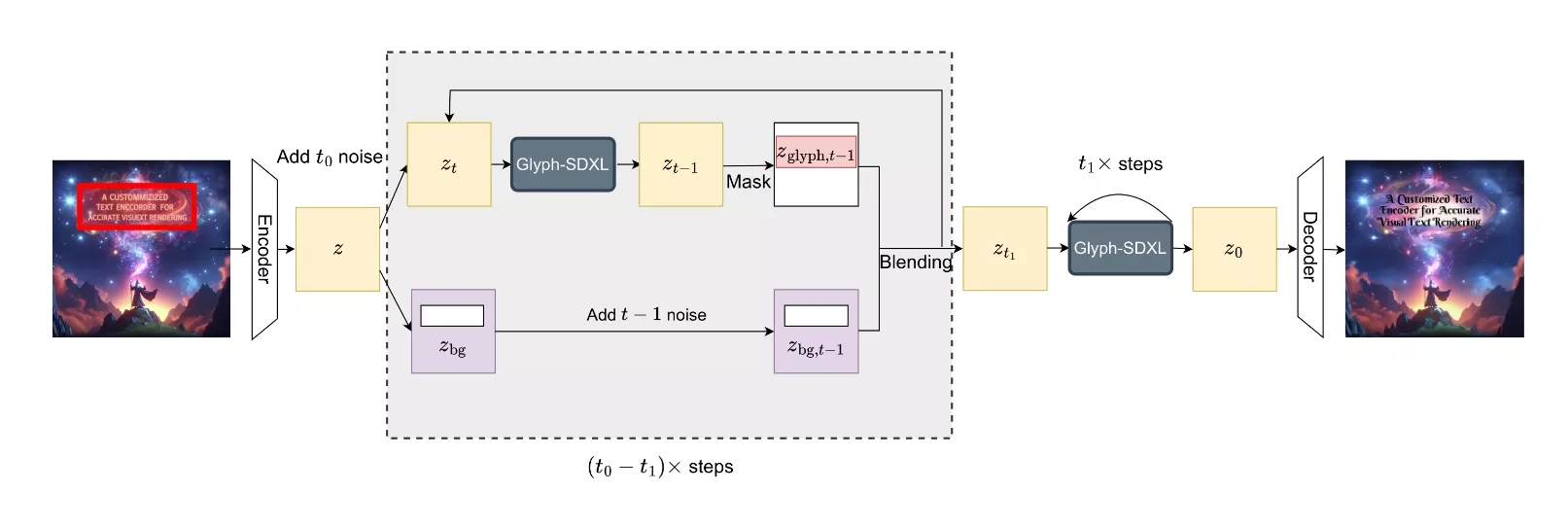
总的来说,Glyph-ByT5是一个强大的文本编码器,它通过专门针对视觉文本渲染的定制训练,显著提高了从文本到图像生成任务中文本的准确性和质量。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











