
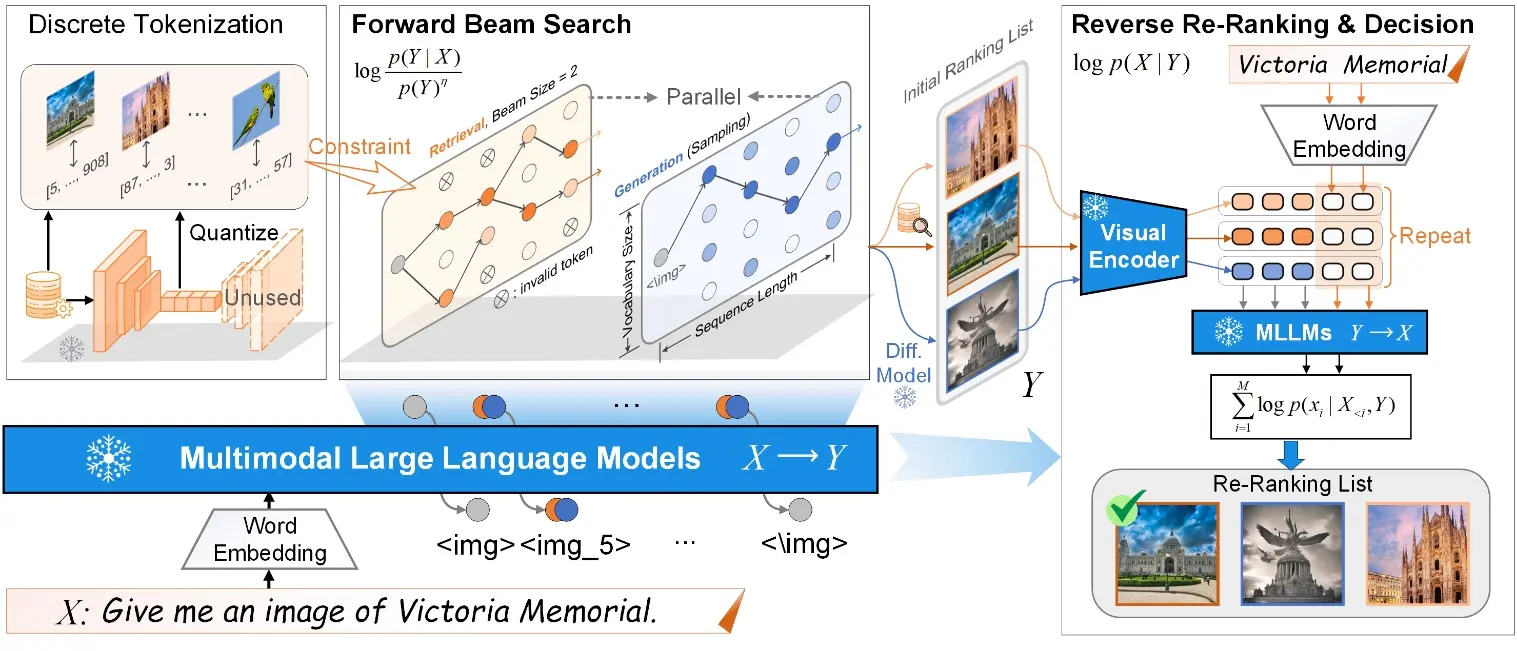
来自新加坡国立大学 NExT++ 实验室、南洋理工大学、香港理工大学和哈尔滨工业大学(深圳)的研究人员推出一个统一的文本到图像生成和检索框架TIGeR,这个框架建立在多模态大语言模型(MLLMs)的基础上。简单来说,这个系统旨在通过文本描述来获取图像,它可以在现有的图像数据库中检索,也可以创造全新的图像来满足用户的需求。
具体而言,开发人员首先探索了MLLMs的内在辨别能力,并引入了一种生成式检索方法,以无需额外训练的方式执行检索。随后,以自回归生成的方式统一生成与检索过程,并提出一个自主决策模块,用于在生成的图像和检索到的图像中选择与文本查询最匹配的一个作为响应。此外,我们构建了一个名为TIGeR-Bench的基准测试集,涵盖了创意和知识密集型领域,以便标准化统一的文本到图像生成与检索的评估。

例如,你想要一张描述“一只独角兽在彩虹上跳舞”的图片,但你的电脑上没有这样的图片。TIGeR框架能够理解你的文本描述,并从数据库中找到最接近的图像,或者直接创造出这张图片。这就像是有一个无限大的图库和一个非常聪明的艺术家,它们可以立即理解你的想法并呈现出来。
主要功能:
- 文本到图像检索(T2I-R):根据文本查询在现有数据库中检索图像。
- 文本到图像生成(T2I-G):根据文本描述创造全新的图像。
- 统一框架:结合检索和生成,提供更灵活和创造性的图像获取方式。
主要特点:
- 无需额外训练:利用MLLMs的内在能力,无需额外的训练即可执行检索任务。
- 生成与检索的统一:通过自回归生成方式,同时进行图像的生成和检索。
- 自主决策模块:能够根据用户提示自动选择生成或检索的图像。
工作原理:
- 利用MLLMs的双向鉴别能力:评估文本到图像和图像到文本的语义相似性。
- 前向束搜索和反向重排:通过前向束搜索快速检索图像,然后使用反向重排来优化检索结果。
- 自回归生成:在生成和检索过程中,MLLMs同步进行无约束和有约束的令牌解码。
- 决策机制:基于MLLMs的内在鉴别能力,选择生成或检索的图像中与文本描述最匹配的一个。
具体应用场景:
- 创意领域:用户需要独特和富有创意的图像,如虚构场景或特定风格的艺术作品。
- 知识密集型领域:用户查询特定知识领域的图像,如地标、物种、食品等,需要模型具有足够的相关知识。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











