
香港科技大学(广州)、腾讯、香港中文大学和香港科技大学的研究人员推出新型多模态大语言模型SEED-Story,它能够根据用户提供的文本和图片生成长篇的多模态故事。这些故事不仅包含丰富的叙事文本,还包括与文本内容一致的角色和风格的图片。这种模型的应用前景非常广泛,比如在教育、娱乐、儿童故事书制作等领域。
- GitHub:https://github.com/TencentARC/SEED-Story
- 模型:https://huggingface.co/TencentARC/SEED-Story
- 数据:https://huggingface.co/datasets/TencentARC/StoryStream
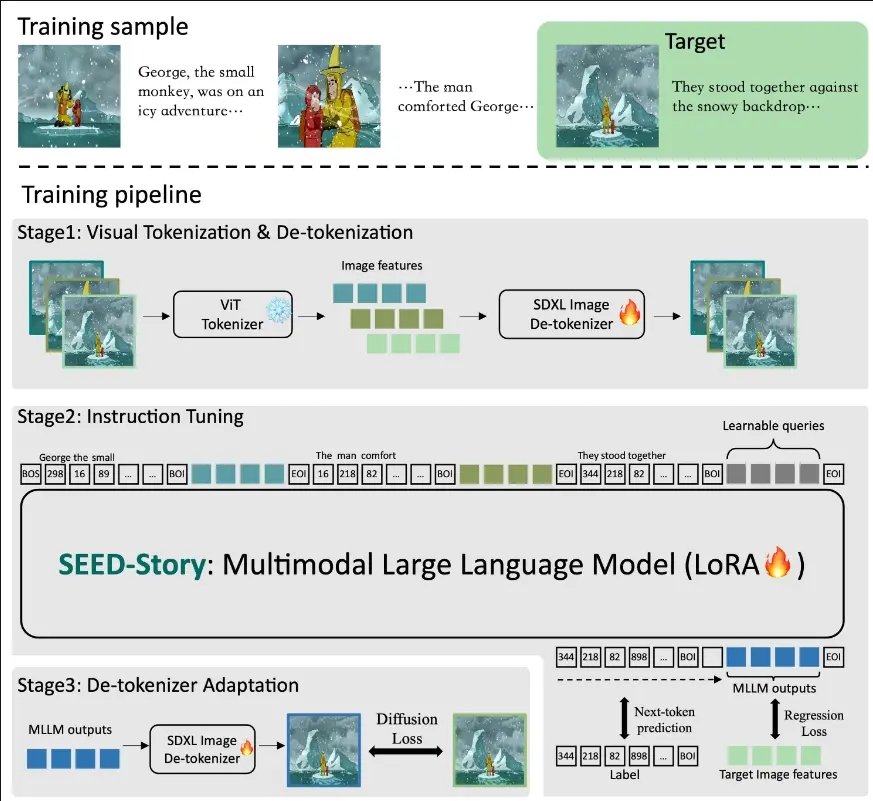
SEED-Story基于多模态大语言模型(MLLM)的强大理解能力,不仅预测文本令牌,还预测视觉令牌,随后通过改进的视觉解令牌器处理这些令牌,以生成角色和风格一致的图像。研究人员进一步提出了多模态注意力下沉机制,使模型能以高度自动回归的方式高效生成多达25个序列(训练时仅为10个)的故事。此外,研究人员还推出一个大规模、高分辨率数据集StoryStream,用于训练模型,并从多个维度定量评估多模态故事生成任务。

例如,你给了一个AI系统几张照片和一小段故事开头,比如“乔治和一只小狗在公园里玩耍”。然后,这个AI能够接着创作这个故事,并且为故事的每个情节配上相应的图片。就像有一个看不见的画家和作家在同时工作,他们不仅能够理解你给出的开头,还能够想象出接下来发生的事情,并且把它们变成文字和图画。
主要功能:
- 生成长篇多模态故事,包含文本和图片。
- 保持故事中角色和风格的一致性。
主要特点:
- 多模态叙事:结合文本和图像,提供沉浸式的叙事体验。
- 长篇故事生成:能够生成长达25个序列的多模态故事,远超训练时使用的序列长度。
- 高效的自回归生成:通过多模态注意力汇聚机制,高效生成长篇故事。
工作原理:
- 视觉编码与解码:使用预训练的视觉Transformer(ViT)作为视觉编码器,将图片转换为特征,再通过扩散模型SD-XL解码成图像。
- 故事指令微调:在给定的图文数据上进行微调,让模型学会预测故事的下一部分文本和图像。
- 去标记器适配:对SD-XL去标记器进行适配,确保生成的图像在风格和细节上与真实图像一致。
- 多模态注意力汇聚:保留关键的文本和图像token,使得模型能够处理和生成比训练时更长的故事序列。
具体应用场景:
- 儿童教育:生成寓教于乐的故事和图像,提高学习兴趣。
- 数字娱乐:为视频游戏或动画制作提供创意故事和视觉素材。
- 互动故事书:在电子书籍中提供互动式的故事体验,用户可以选择不同的情节发展路径。
- 社交媒体内容创作:帮助内容创作者快速生成有吸引力的故事和图像,用于社交媒体分享。
总之,SEED-Story模型通过结合多模态数据的理解和生成能力,为长篇故事创作提供了一个强大的AI工具,它能够根据少量的初始信息,创造出丰富、连贯、视觉吸引的故事内容。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











