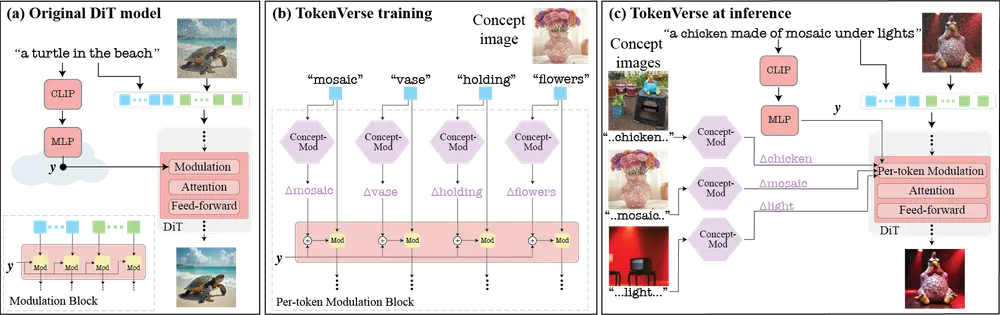
谷歌 DeepMind、特拉维夫大学、以色列理工学院和魏茨曼研究所的研究人员推出新型多概念个性化方法TokenVerse,旨在通过预训练的DiT架构文生图模型实现从单张或多张图像中提取复杂视觉概念,并支持无缝组合这些概念以生成新的图像。该方法的核心在于能够从少量图像中解耦复杂的视觉元素和属性,并通过文本提示灵活地生成新的图像组合。
例如,我们有两张图像:一张是“穿着衬衫和项链的狗”,另一张是“在花园中的男人”。TokenVerse 可以从这两张图像中分别提取“狗”、“衬衫”、“项链”、“男人”和“花园”等概念,并将它们组合成新的图像,例如“穿着衬衫和项链的男人在花园中”。这种能力使得用户能够通过简单的文本提示生成具有高度个性化和多样性的图像。

主要功能
- 多概念解耦:从单张或多张图像中提取多个复杂的视觉概念,包括对象、配件、材质、姿势和光照条件。
- 灵活组合:支持将从不同图像中提取的概念无缝组合成新的图像。
- 个性化生成:通过文本提示控制生成图像的具体内容,支持高度个性化的创作。
- 无需额外监督:无需分割掩码或边界框等额外监督信息,仅依赖于图像的文本描述即可完成概念提取和生成。
主要特点
- 基于调制空间(M+)的优化框架:通过优化每个文本标记在调制空间中的方向,实现对复杂概念的局部控制。
- 模块化设计:支持从不同图像中提取的概念的无缝组合,具有高度的模块化和灵活性。
- 广泛的适用性:能够处理多种类型的视觉概念,包括非对象概念(如姿势、材质和光照条件)。
- 高效的训练和生成:通过两阶段优化过程(全局方向优化和逐块方向优化),提高生成图像的质量和概念保真度。
工作原理
调制空间(M)和逐标记调制空间(M+):
- 调制空间(M):通过修改全局调制向量来实现对生成图像的语义修改,但这些修改通常是全局性的,可能会影响图像中的多个概念。
- 逐标记调制空间(M+):通过仅修改特定文本标记的调制向量,实现对特定概念的局部控制,从而更精确地修改生成图像中的特定部分。
概念提取和优化:
- 给定一张图像及其对应的文本描述,TokenVerse 通过优化每个文本标记的调制向量,学习每个概念的个性化表示。
- 通过两阶段优化过程(全局方向优化和逐块方向优化),进一步提高生成图像的质量和概念保真度。
- 引入概念隔离损失(Concept Isolation Loss),减少从不同图像中提取的概念之间的干扰。
生成过程:
- 在生成阶段,用户可以通过简单的文本提示组合从不同图像中提取的概念,生成新的图像。
- 通过将优化后的调制向量应用于相应的文本标记,实现对生成图像的精确控制。
优势和局限性
优势:
- 多概念解耦:能够从单张图像中提取多个复杂概念,并支持灵活组合。
- 无需额外监督:无需分割掩码或边界框,仅依赖于文本描述即可完成概念提取。
- 广泛的适用性:支持多种类型的视觉概念,包括非对象概念(如姿势、材质和光照条件)。
- 高效的训练和生成:通过两阶段优化过程,提高生成图像的质量和概念保真度。
局限性:
- 独立训练导致的概念混合:在某些情况下,从不同图像中独立训练的概念可能会相互影响,导致生成图像中出现混合对象。
- 相同标识符的冲突:当两个概念共享相同的标识符时,可能会导致生成图像中出现冲突或不一致的结果。
- 不兼容组合:某些不兼容的概念组合(如具有极短四肢的玩偶尝试复杂姿势)可能导致生成不理想的图像。
TokenVerse 通过其创新的多概念个性化方法,为文本到图像生成领域带来了新的可能性,特别是在个性化内容创作和故事创作方面具有广泛的应用前景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











