
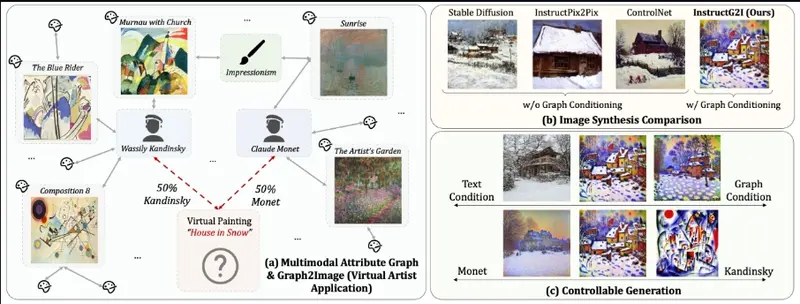
多模态属性图(MMAGs)作为一种强大的数据结构,能够以图的形式表示实体之间的关系,节点中包含图像和文本信息。尽管 MMAGs 在图像生成中具有多功能性,但它们受到的关注相对较少。这是因为 MMAGs 存在一些显著的挑战,尤其是在图大小的爆炸、图实体依赖性和图条件中的可控性需求等方面。
图大小的爆炸:图的组合复杂性导致图的大小呈指数增长,特别是当引入包含图像和文本的局部子图时。这种现象使得模型的训练和推理变得更加困难,需要有效的解决方案来管理图的规模。 图实体依赖性:节点特征是相互依赖的,这意味着它们的接近度反映了文本和图像中实体之间的关系及其在图像生成中的偏好。例如,生成浅色衬衫时应偏好浅色调,如粉彩。这种依赖性要求模型能够理解并保持图中实体之间的关系。 图条件中的可控性需求:生成图像的可解释性必须受到控制,以遵循图中实体之间连接定义的所需模式或特征。这要求模型能够根据图中的结构生成具有特定属性的图像,确保生成的内容与图中的信息一致。
InstructG2I:图上下文感知扩散模型
为了解决上述挑战,伊利诺伊大学的研究人员开发了 InstructG2I,这是一个利用多模态图信息的图上下文感知扩散模型,它能够根据多模态属性图(MMAGs)生成图像。
- 项目主页:https://instructg2i.github.io
- GitHub:https://github.com/PeterGriffinJin/InstructG2I
- 模型:https://huggingface.co/PeterJinGo/VirtualArtist
例如,我们有一个由许多画作组成的庞大数据库,每幅画作都以其图像和标题存在,并且它们通过风格或作者的相似性相互连接。INSTRUCTG2I模型可以利用这些信息,根据给定的文本描述和图中的连接关系,生成新的画作图像。这就像是在艺术作品中,你可以根据一位艺术家的风格和他们的作品网络来创造一幅新的虚拟艺术作品。
主要功能和特点
信息邻居采样:模型首先通过一种特殊的算法,从图中选择与目标节点最相关的邻居节点。 图信息编码:然后,它使用一种叫做Graph-QFormer的编码器,将这些图中的信息转换成一种辅助的图提示,以指导图像生成过程。 可控生成:通过调整图中指导的强度和多个连接边的影响,模型可以灵活地在不同风格之间转换,创造出具有特定风格的新图像。
工作原理
图结构和多模态信息:模型首先分析图结构和节点中的图像、文本信息,以选择信息量最丰富的邻近节点。 图编码器:接着,Graph-QFormer编码器将这些节点的信息编码成图提示,这些提示将用于指导图像生成过程。 扩散模型:最后,模型使用一个扩散模型,这是一个逐步去除噪声并生成清晰图像的过程,同时考虑到文本和图提示。
InstructG2I 主要通过以下几种方式解决问题:
图条件Token压缩:使用基于语义个性化PageRank(PPR)的图采样方法,将图中的上下文压缩为固定容量的图条件Token,从而解决图空间复杂性问题。 Graph-QFormer架构:Graph-QFormer 是一个双Transformer模块,用于捕捉基于文本和图像的依赖关系。它使用多头自注意力处理图像-图像依赖关系,使用多头交叉注意力处理文本-图像依赖关系。交叉注意力层将图像特征与文本提示对齐,生成相关图像。 可调边长引导:使用无分类器引导技术,通过调整图强度来控制生成过程,确保生成的图像符合图中定义的关系和属性。
实验结果
InstructG2I 在三个不同领域的数据集上进行了测试:ART500K、Amazon 和 Goodreads。实验结果表明,InstructG2I 在多项任务中显著优于基线模型:
定量评估:InstructG2I 在 CLIP 和 DINOv2 评分上优于所有基线模型。 定性评估:InstructG2I 生成的图像最符合文本提示和图上下文的语义,确保生成的内容和上下文从图中邻居学习并准确传达信息。
结论
InstructG2I 有效地解决了多模态属性图中的图大小爆炸、实体间依赖性和可控性等重大挑战,并在图像生成任务中超越了基线模型。未来的研究将继续探索如何更好地处理 MMAGs 中图像和文本之间复杂的异构关系,进一步提升图像生成的质量和可控性。InstructG2I 的成功为图与图像生成的结合提供了新的思路,有望在更多领域得到应用和发展。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











