
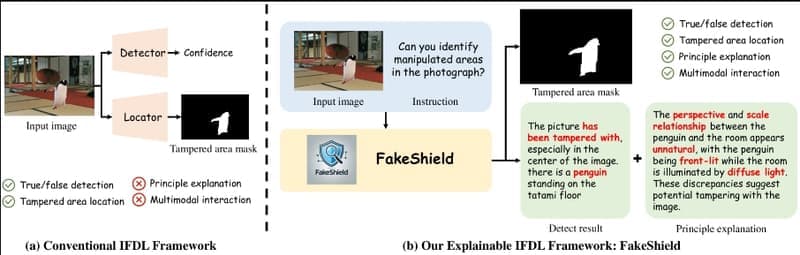
生成式AI的快速发展为内容创作带来了巨大便利,但同时也使得图像篡改变得更加容易且难以检测。当前的图像伪造检测和定位(IFDL)方法虽然通常有效,但仍面临两大挑战:
- 黑箱性质:检测原理未知,难以理解和解释。
- 泛化能力有限:在多种篡改方法(如Photoshop、DeepFake、AIGC-Editing)之间的泛化能力有限。
为了解决这些问题,北京大学电子与计算机工程学院和华南理工大学未来科技学院的研究人员提出了一个新的框架——FakeShield,这是一个多模态框架,能够评估图像的真实性,生成篡改区域掩码,并基于像素级和图像级的篡改线索提供判断依据。
主要功能
这个AI系统,叫做FakeShield,就像一个高级的“图像侦探”。它的主要功能有两个:
- 检测真伪:判断一张图片是否被人为修改过。
- 定位造假区域:如果图片是假的,它能准确地指出图片中哪些部分被修改了。
主要特点
FakeShield的特点在于:
- 可解释性:与传统的黑盒AI模型不同,FakeShield不仅能告诉你图片是假的,还能解释为什么是假的。
- 多模态:它结合了视觉和文本信息,能更全面地理解和分析图片。
- 强大的泛化能力:无论是Photoshop编辑、DeepFake人脸造假,还是AIGC编辑,FakeShield都能检测。
工作原理
FakeShield的工作原理可以分为几个步骤:
- 图像输入:将可疑的图片输入系统。
- 特征提取:系统分析图片的像素级和图像级特征,比如物体边缘、分辨率一致性、光影关系等。
- 文本描述生成:利用大型语言模型(LLM),FakeShield能生成关于图片修改区域的详细文本描述。
- 检测与定位:结合文本描述和图像特征,FakeShield判断图片是否被修改,并定位修改区域。
- 结果输出:输出检测结果和造假区域的掩码(mask),清晰显示哪些部分被修改。
FakeShield 的设计与实现
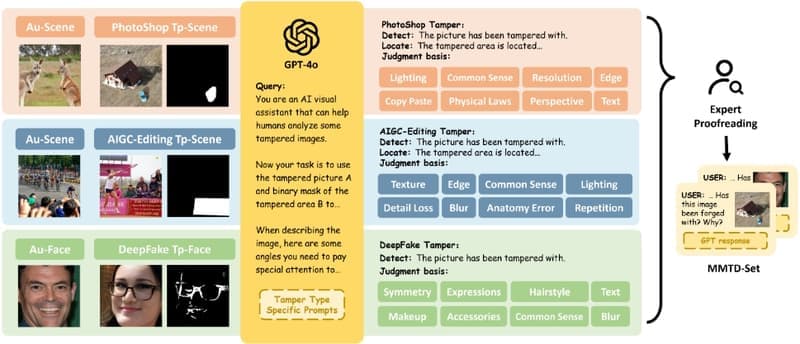
1. 多模态篡改描述数据集(MMTD-Set)
为了增强现有的IFDL数据集,研究人员利用GPT-4o生成了多模态篡改描述数据集(MMTD-Set)。这个数据集包含了丰富的文本描述,用于训练FakeShield的篡改分析能力。这些描述不仅包括图像篡改的技术细节,还包括篡改的目的和方法,从而为模型提供了更多的上下文信息。
2. 领域标签引导的可解释伪造检测模块(DTE-FDM)
FakeShield 包含了一个领域标签引导的可解释伪造检测模块(DTE-FDM)。该模块通过引入领域标签,帮助模型更好地理解和解释不同类型的篡改。领域标签可以是篡改方法(如Photoshop、DeepFake)或篡改目的(如娱乐、欺骗)等,从而提高模型的泛化能力和解释性。
3. 多模态伪造定位模块(MFLM)
除了检测篡改,FakeShield 还包含一个多模态伪造定位模块(MFLM)。该模块能够生成篡改区域的掩码,并基于像素级和图像级的篡改线索提供详细的定位信息。通过结合文本描述和视觉特征,MFLM能够更准确地定位篡改区域,并提供详细的解释。
实验结果
大量的实验表明,FakeShield 能够有效检测和定位各种篡改技术,与之前的IFDL方法相比,提供了一个可解释且更优越的解决方案。具体来说:
- 检测准确性:FakeShield 在多种篡改方法上的检测准确性显著高于现有方法。
- 定位精度:MFLM 能够生成精确的篡改区域掩码,帮助用户更好地理解篡改的位置和范围。
- 可解释性:DTE-FDM 提供了详细的文本描述,帮助用户理解检测结果背后的逻辑和原理。
应用场景
想象一下,你在社交媒体上看到一张令人难以置信的照片,比如一只企鹅站在榻榻米上。你的第一反应可能是:“这是真的吗?”因为企鹅通常不会出现在这种环境中。在这种情况下,FakeShield 可以帮助你快速判断这张照片是否经过篡改,并提供详细的解释,让你更加自信地做出判断。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











