近年来,基础视觉语言模型(VLMs)的发展彻底改变了计算机视觉领域的研究方向。这些模型,尤其是 CLIP,不仅推动了开放词汇计算机视觉任务的研究,还在多个领域取得了显著成果。然而,尽管 VLMs 在开放词汇语义分割(OVSS)任务中展现出了初步的积极效果,但其密集预测能力仍有待进一步提升。
研究背景与目标
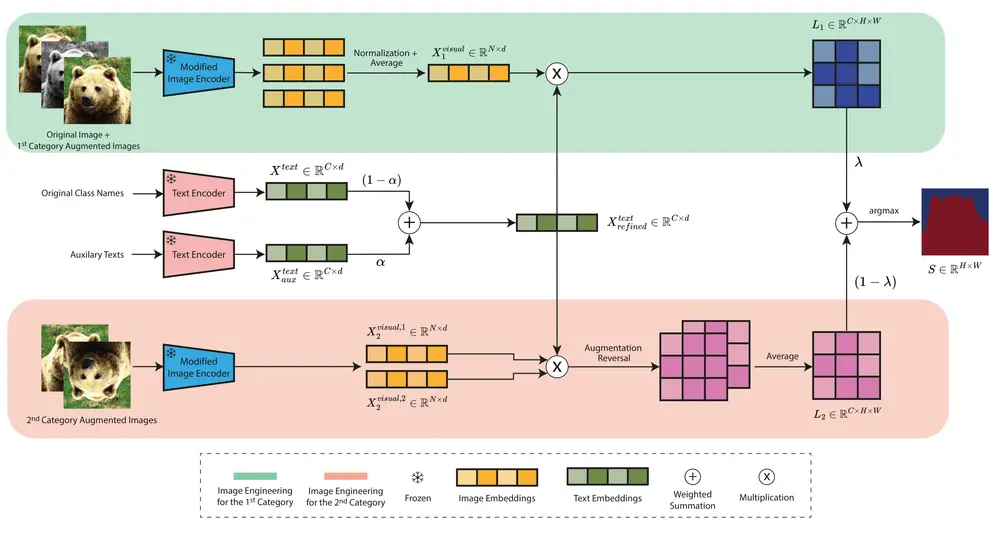
为了克服现有 VLMs 在语义分割中的局限,比尔肯特大学、亚琛工业大学、慕尼黑工业大学和伊斯坦布尔技术大学的研究人员合作,提出了一个名为ITACLIP(Image-Text-Architectural Enhanced CLIP)的方法,旨在提升无训练(training-free)语义分割的性能。该方法通过结合图像、文本和架构增强来提高CLIP模型在开放词汇(open-vocabulary)语义分割任务中的性能。ITACLIP通过引入新的模块和修改,增强了CLIP模型的密集预测能力,特别是在处理图像中的纹理保持和尺寸感知适配方面的挑战。
这些改进措施包括:
- 架构更改:在 Vision Transformer (ViT) 的最后一层进行结构调整,并将中间层的注意力图与最后一层的输出相结合,以提高模型的特征表示能力。
- 图像工程:通过应用数据增强技术,丰富输入图像的表示,进一步提升模型的泛化能力。
- 语言模型辅助:利用大语言模型(LLMs)为每个类别名称生成定义和同义词,充分利用 CLIP 的开放词汇能力,增强模型对不同类别的理解。
例如,你有一个城市街景的图片,想要进行语义分割,即识别并分割出图片中的每个物体和场景元素(如行人、车辆、建筑物等)。使用ITACLIP,你可以得到一个精确的分割结果,其中每个像素都被标记为属于哪个类别。例如,所有的行人都会被识别并分割出来,与车辆和建筑物区分开来。
主要功能:
- 无训练语义分割: 不需要额外的训练或像素级标注数据,即可实现对图像中各个对象和场景元素的识别和分割。
- 开放词汇支持: 能够处理不仅仅是预定义类别,还包括任意类别名称的像素级分类任务。
工作原理
研究人员提出的免训练方法 ITACLIP 具体包括以下几个步骤:
- 架构优化:通过对 ViT 最后一层的结构进行调整,并融合中间层的注意力图,ITACLIP 能够更准确地捕捉图像中的关键特征。
- 数据增强:通过应用多种数据增强技术,如随机裁剪、旋转和颜色变化,ITACLIP 可以在训练过程中获得更加多样化的输入数据,从而提高模型的鲁棒性。
- 语言模型辅助:借助 LLMs 生成的类别定义和同义词,ITACLIP 能够更好地理解不同类别的含义,从而在语义分割任务中表现出更强的识别能力。
- 加权求和: 对图像工程和LLM生成的文本特征进行加权求和,以整合多源信息。
实验结果
实验结果显示,ITACLIP 在多个标准分割基准上均取得了优异的成绩,包括 COCO-Stuff、COCO-Object、Pascal Context 和 Pascal VOC。这些结果表明,ITACLIP 不仅在分割精度上超过了当前最先进的方法,还在多个数据集上展示出了一致的高性能。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











