华盛顿大学、澳大利亚国立大学和艾伦人工智能研究所的研究人员提出了一种新的对抗性引导方法——负标记合并(Negative Token Merging, NegToMe)。该方法旨在通过直接利用参考图像或其他批次图像的视觉特征,而非仅依赖文本提示,来更有效地排除不希望的视觉元素。这种方法特别适用于避免生成受版权保护的角色等复杂视觉概念。
- 项目主页:https://negtome.github.io
- GitHub:https://github.com/1jsingh/negtome
- Demo:https://a62ec09c8038aea4ee.gradio.live
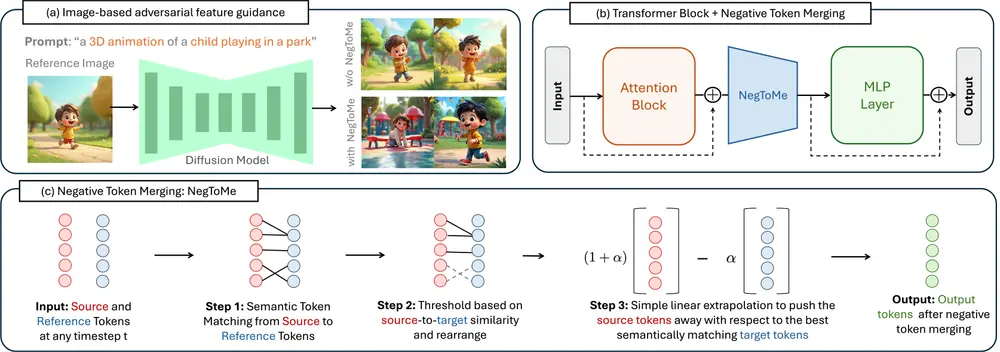
NegToMe 是一种无需训练的方法,它通过在反向扩散过程中选择性地推动匹配的语义特征(在参考图像和生成输出之间)来执行对抗性引导。这种方法可以直接使用参考图像或其他图像的视觉特征来进行对抗性引导,而不仅仅依赖于负面提示(negative prompt)。
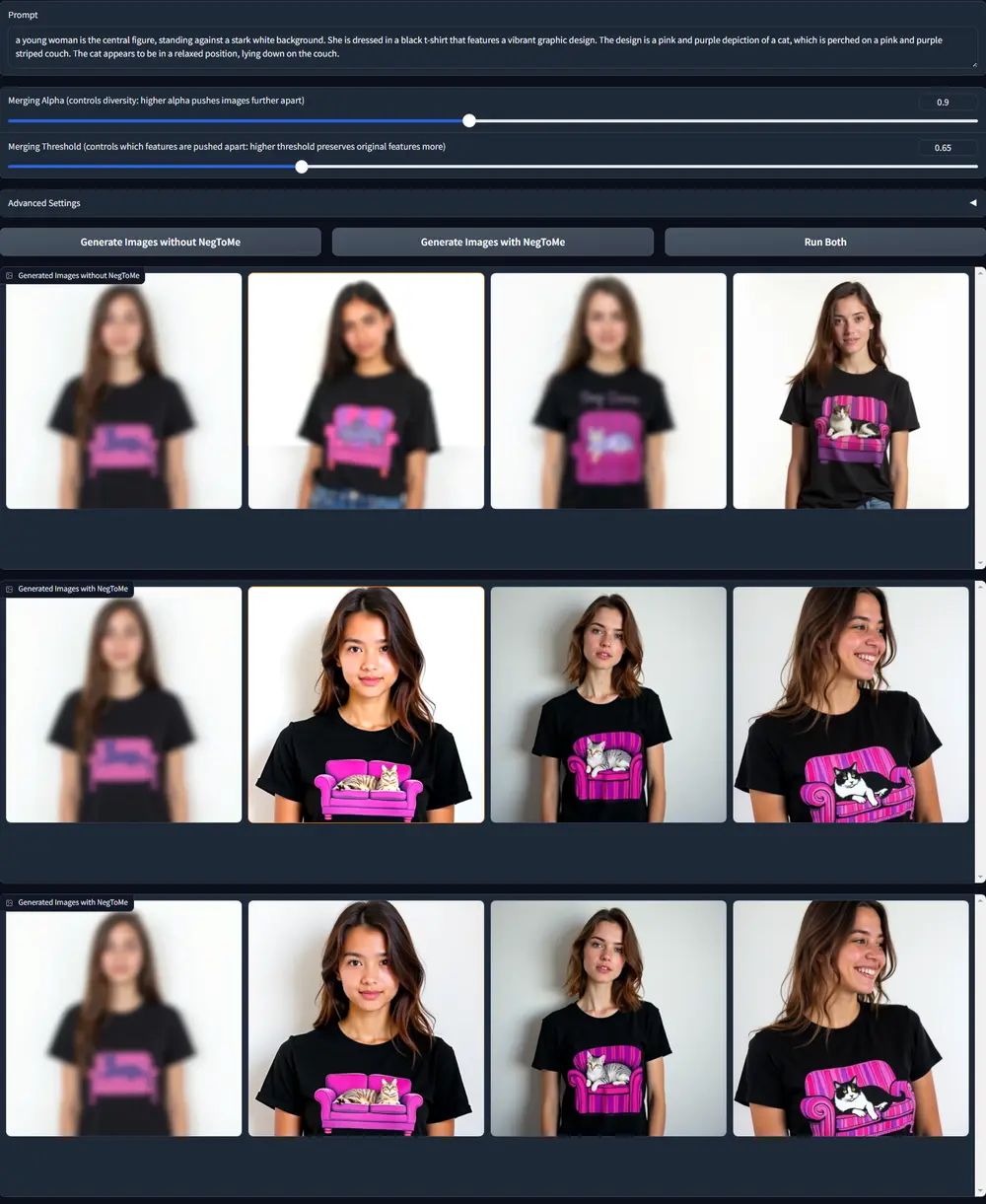
例如,假设我们想要生成一系列不同种族、性别和风格的人物图像。使用NegToMe,我们可以将每个生成的图像的特征与参考图像或同批次中的其他图像的特征进行比较,并在生成过程中将它们相互推开,从而增加输出的多样性。另一个例子是,如果我们想要减少生成图像与某个版权角色的相似性,NegToMe可以通过将生成的特征与版权图像的特征进行比较,并在生成过程中避免接近这些特征,从而降低视觉相似性。
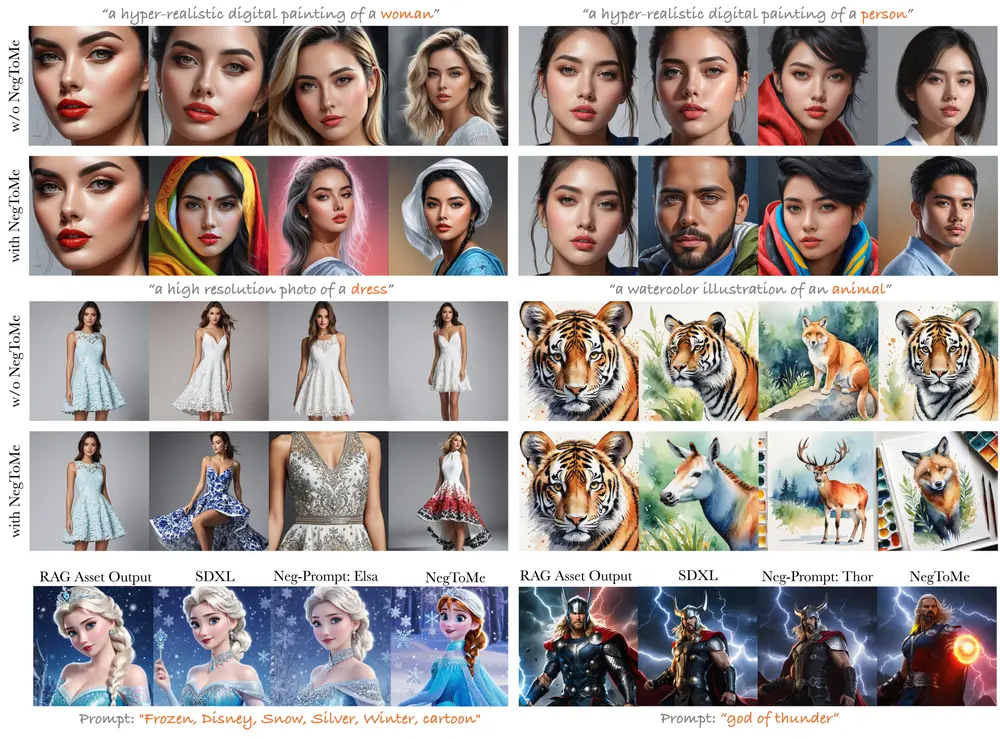
超越文本的对抗性引导
传统的对抗性引导主要依靠负面文本提示,将生成的输出特征推离不希望的概念。然而,这种基于文本的方法在处理复杂的视觉概念时可能存在局限性。NegToMe通过引入视觉特征作为引导信号,弥补了这一不足。它能够在反向扩散过程中选择性地分离匹配的语义特征,确保生成的图像与不希望的视觉元素保持距离。
主要功能和主要特点
- 对抗性引导:NegToMe 通过在生成过程中推动特征分开,增强了对抗性引导的能力。
- 无需训练:这种方法不需要额外的训练,可以直接集成到现有的扩散模型中。
- 提高多样性:NegToMe 能够显著提高输出多样性,包括种族、性别和视觉多样性,而不牺牲图像质量。
- 减少版权内容相似性:NegToMe 有助于减少与版权内容的视觉相似性,例如减少与特定版权角色的相似度。
- 易于实现:NegToMe 实现简单,只需几行代码,并且对推理时间的影响很小(<4%)。
工作原理
NegToMe的核心思想是在反向扩散的过程中,动态地对比参考图像和当前生成的图像之间的语义特征。当检测到两者之间存在相似的特征时,NegToMe会采取措施削弱这些特征在生成过程中的影响,从而实现对抗性引导。这种方法不仅能够有效避免不希望的视觉元素,还能显著增加输出图像的多样性,特别是在种族、性别等方面,同时保持高质量的图像输出。
- 语义令牌匹配:计算生成令牌和参考图像令牌之间的相似性。
- 阈值处理和重排:根据源到目标的相似度进行阈值处理,并重排令牌。
- 线性外推:对源令牌进行简单的线性外推,将其与最佳语义匹配的目标令牌推开。
实验结果与优势
实验结果显示,NegToMe在多个方面表现出色:
- 增加输出多样性:当与同一批次中的其他图像一起使用时,NegToMe显著增加了输出图像的多样性,涵盖种族、性别和视觉风格等多个维度。
- 减少版权内容相似度:特别是对于受版权保护的内容,NegToMe帮助减少了生成图像与原内容的视觉相似度,最高可达34.57%。
- 高效且易于实现:NegToMe的实现非常简单,只需几行代码,对推理时间的影响也较小(<4%),并且可以泛化到不同的扩散架构,如Flux,即使这些架构原本不支持单独的负面提示。
应用前景
NegToMe作为一种无需训练的简单而有效的方法,为对抗性引导提供了一个新的视角。它不仅提升了生成模型的灵活性和控制力,还为解决版权问题提供了实用的解决方案。随着技术的不断进步,我们期待看到更多像NegToMe这样的创新方法,进一步推动生成式AI的发展,并为创作者提供更多工具来实现他们的创意愿景。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











