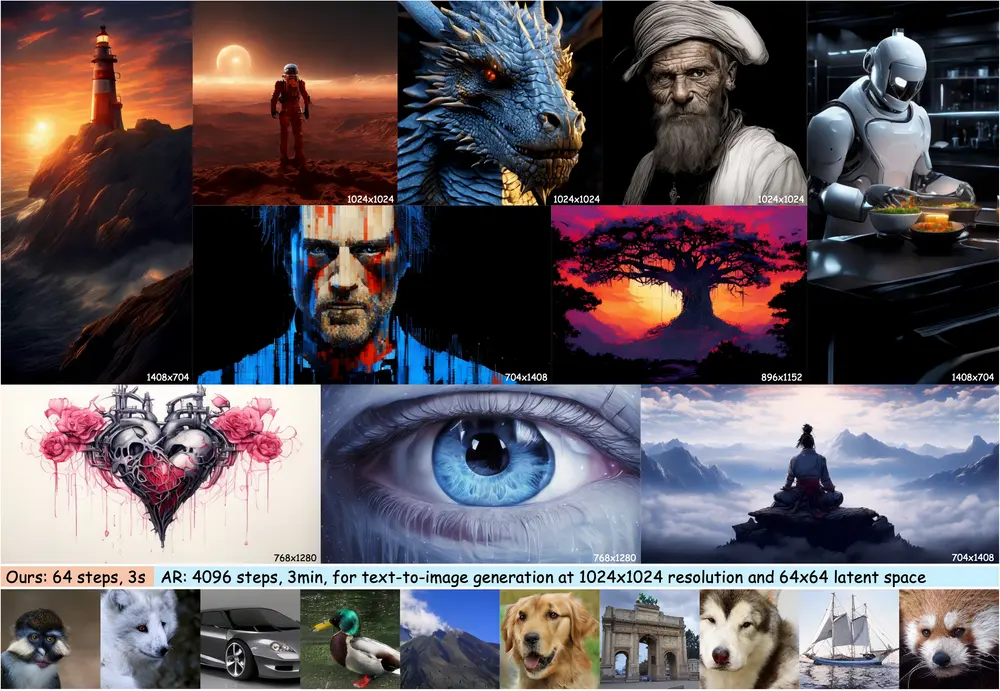
阿尔伯塔大学电子与计算机工程系、华为技术加拿大公司和华为麒麟解决方案的研究人员推出新型文本到图像生成方法FRAP,旨在提高由文本提示生成图像的真实性和忠实度,确保生成的图像与文本描述的内容精确匹配。FRAP基于自适应调整每个词汇的提示权重来改善生成图像与提示之间的一致性和真实性。研究人员设计了一个在线算法来自适应更新每个词汇的权重系数,这是通过最小化一个统一的目标函数实现的,该目标函数鼓励对象的存在以及对象-修饰词对的绑定。
例如,一个用户想要生成一幅画有“一只棕色的狗和一只红色的鞋”的图片,他们只需要提供这样的文本描述作为提示。FRAP会分析文本,理解其中的对象和颜色修饰符,然后生成一幅图像,确保图像中有一只棕色的狗和一只红色的鞋,并且这两者在视觉上是协调和真实的。

主要功能:
- 提升图像与文本的一致性:确保生成的图像严格符合文本提示的要求。
- 保持图像的真实感:生成的图像在视觉上看起来自然且逼真。
主要特点:
- 自适应提示权重:FRAP通过自适应调整文本提示中每个词的权重来优化图像生成过程。
- 在线算法:设计了一个在线算法,可以在推理过程中动态更新每个词的权重系数。
- 统一目标函数:通过最小化一个统一的目标函数来加强对象存在性并鼓励对象-修饰符对的绑定。
工作原理:
- 文本编码器:使用文本编码器将文本提示转换为嵌入向量。
- 交叉注意力机制:在生成过程中,利用交叉注意力机制将文本信息注入到图像生成模型中。
- 自适应权重调整:根据交叉注意力图的反馈,动态调整文本提示中每个词的权重,以强化对象的存在并确保修饰符正确绑定到对象上。
具体应用场景:
- 艺术创作:艺术家和设计师可以使用FRAP根据文本描述生成具有特定风格和内容的图像。
- 数字媒体:在数字媒体和广告领域,FRAP可以用来快速生成符合广告文案的视觉内容。
- 游戏开发:游戏开发者可以利用FRAP生成游戏内的角色、场景等元素的概念图。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











