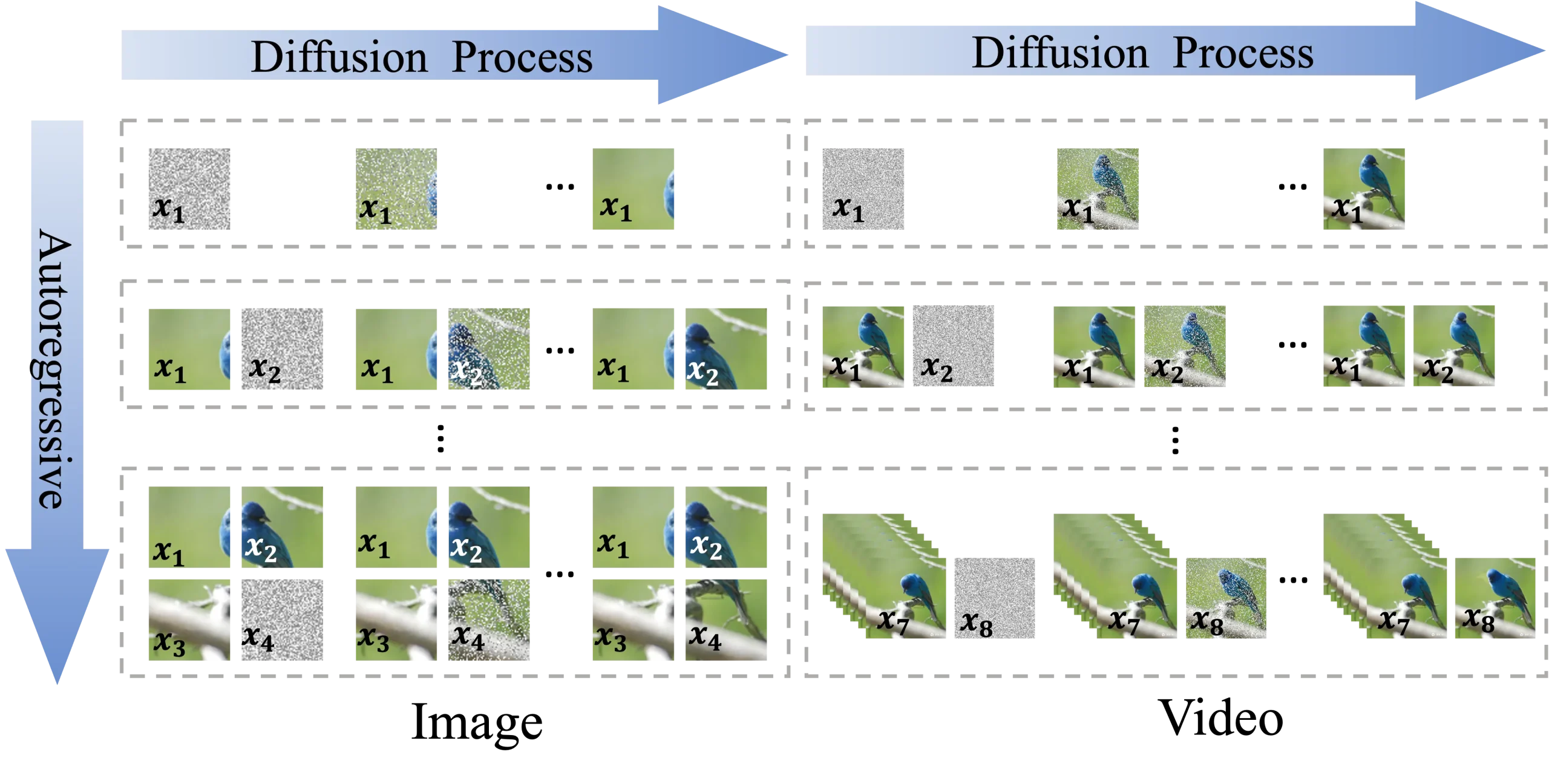
清华大学和字节跳动的研究人员推出ACDIT,它是一种介于自回归模型和扩散模型之间的插值方法,用于处理视觉信息。ACDIT的核心思想是将自回归建模扩展到块级别,而不是单个文本标记,使得每个块的生成可以基于前一个块的条件扩散过程来实现。这种方法允许模型在保持自回归模型的优点的同时,也能利用扩散模型的强大生成能力。
例如,我们要生成一系列图像或视频,其中每个图像或视频帧被视为一个块。在ACDIT框架下,模型会首先基于前一个块(即前一个图像或帧)生成当前块的噪声版本,然后通过迭代去噪过程生成清晰的图像或视频帧。例如,如果我们正在生成一个关于“在公园中玩耍的孩子们”的视频,ACDIT会逐步生成每一帧,同时确保每一帧都与前一帧在视觉上连贯。
主要功能:
- 结合自回归和扩散模型的优点,进行高效的图像和视频生成。
- 灵活调整块大小,以适应不同的生成任务,如图像、视频等。
- 在保持清晰的潜在输入的同时,实现对任何长度的自回归生成。
主要特点:
- 灵活性:ACDIT可以通过调整块大小来适应不同的视觉生成任务。
- 效率:利用KV-Cache(Key-Value Cache)提高推理速度,尤其是在处理长序列时。
- 性能:在图像和视频生成任务中,ACDIT展现出与全序列扩散模型相当的性能,同时具有更高的推理速度。
工作原理:
ACDIT通过引入Skip-Causal Attention Mask(SCAM)来实现自回归和扩散模型的结合。在训练过程中,模型学习如何根据前一个块的条件来预测当前块的噪声。在推理过程中,模型在扩散去噪和自回归解码之间迭代,利用KV-Cache来加速生成过程。这样,ACDIT能够在保持自回归模型的因果依赖性的同时,也能够捕捉到扩散模型中的非因果依赖性。
具体应用场景:
- 图像生成:使用ACDIT生成高质量的图像,如艺术作品、设计图等。
- 视频生成:生成连续的视频内容,如电影预告片、动画短片等。
- 视觉理解任务:利用ACDIT的清晰潜在输入进行图像识别、分类等视觉理解任务。
- 多模态模型:作为构建统一的多模态模型的骨架,整合视觉、文本等不同模态的信息。
- 世界模型:在强化学习等领域,ACDIT可以作为构建能够预测未来状态的世界模型的基础。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...