
在当今数字化快速发展的时代,跨平台的自动化任务变得越来越普遍。对于这些任务而言,数字代理通过直接操作图形用户界面(GUI)来完成工作的重要性日益凸显。然而,将自然语言指令准确映射到具体的GUI元素上一直是这一领域的重大挑战。为了解决这个问题,Rhymes AI与香港大学的研究团队合作开发了Aria-UI——一个专注于GUI映射的大型多模态模型,类似于 Claude Computer use。
- 项目主页:https://ariaui.github.io
- GitHub:https://github.com/AriaUI/Aria-UI
- 模型:https://huggingface.co/Aria-UI/Aria-UI-base
- 数据:https://huggingface.co/datasets/Aria-UI/Aria-UI_Data
- Demo:https://huggingface.co/spaces/Aria-UI/Aria-UI
Aria-UI无需 HTML 或 AXTree 输入,采用纯视觉方法,摒弃了对辅助输入的依赖。为了适应异构的规划指令,我们提出了一种可扩展的数据管道,能够合成多样化的高质量指令样本用于映射。为了处理任务执行中的动态上下文,Aria-UI结合了纯文本和文本-图像交错的行动历史,从而实现强大的上下文感知推理以进行映射。Aria-UI在离线和在线代理基准测试中创下了新的最先进成果,超越了仅依赖视觉和AXTree的基线模型。
Aria-UI的关键特性
✨ 多功能映射指令理解:Aria-UI能够处理多样化的映射指令,擅长解释不同格式的指令,确保在动态场景中或与多样化规划代理配合时具有强大的适应性。
📝 上下文感知的映射:Aria-UI有效地利用历史输入,无论是纯文本还是文本-图像交错的格式,以提高映射的准确性。
⚡ 轻量且快速:Aria-UI是一种专家混合模型,每个令牌激活的参数为39亿。它能够高效编码不同尺寸和宽高比的GUI输入,并支持超高分辨率。
🎉 卓越的性能:Aria-UI在离线和在线代理基准测试中创下了新的最先进成果。特别是,Aria-UI在AndroidWorld上以44.8%的任务成功率获得🏆第一名,在OSWorld上以15.2%的任务成功率获得🥉第三名。(2024年12月)
主要功能
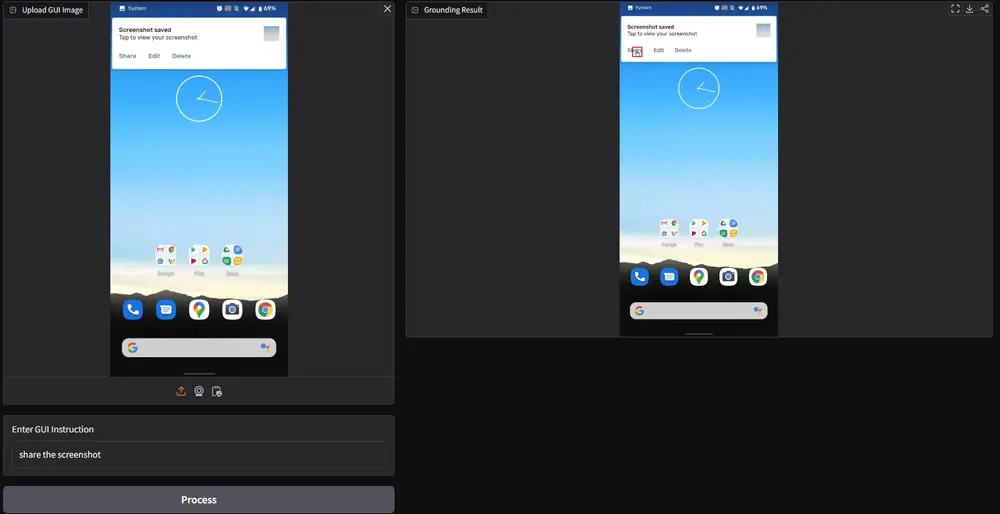
- GUI 元素定位与交互:能够根据用户提供的语言指令,在不同平台(如网页、桌面、移动设备)的 GUI 中准确找到目标元素,并确定与之交互的方式,例如点击按钮、输入文本、选择菜单选项等。比如,在购物网站上,根据 “点击加入购物车按钮” 的指令,Aria-UI 可以定位到相应的按钮元素并模拟点击操作。
- 适应多样化指令:可以处理各种形式和内容的指令,包括对元素的描述、操作意图的表达等,无论指令是简单直接还是复杂抽象,Aria-UI 都能理解并执行相应的接地任务。例如,对于 “在音乐播放应用中,找到播放下一首歌曲的图标并点击它” 这样的指令,Aria-UI 能够成功解析并完成操作。
主要特点
- 纯视觉方法:不依赖 HTML 或 AXTree 等文本输入,仅通过视觉信息进行 GUI 元素的定位和理解,避免了因文本信息缺失或不准确导致的效率低下、幻觉和偏差等问题,同时提高了对视觉或位置相关指令的处理能力。
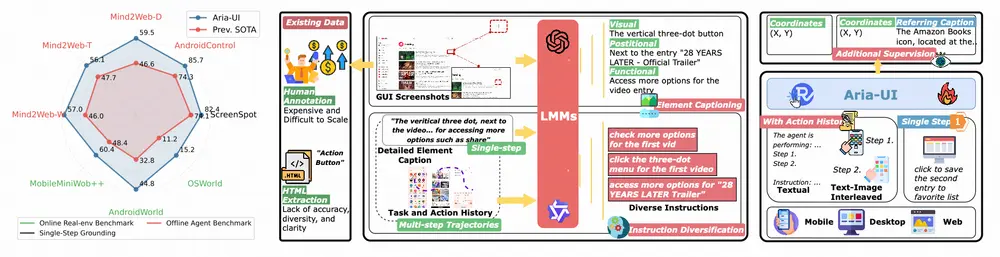
- 大规模多样化数据合成:设计了一种数据合成管道,从 Common Crawl 收集和公共可用数据中生成高质量、多样化的(元素描述,指令)样本。通过利用强大的语言模型(如 GPT-4o 或 Qwen2-VL72B)生成元素描述,并基于这些描述创建多样化的自然语言指令,使模型能够更好地适应不同环境中的各种指令。
- 动态上下文感知:能够利用文本或文本 - 图像交错的动作历史信息,在动态多步骤任务场景中进行有效的接地推理。通过考虑先前的动作历史,模型可以更好地理解任务上下文,提高接地的准确性,避免在连续的接地动作中出现偏差。
工作原理
数据合成与预处理
- 多平台多样化数据缩放:通过两阶段管道将原始样本转换为高质量、多样化的元素指令数据。第一阶段,利用强大的 LMM(如 GPT-4o 或 Qwen2-VL72B)对元素截图和从 HTML 提取的文本进行处理,生成详细准确的元素描述,包括视觉属性、功能、位置关系等信息;第二阶段,使用 LLM 根据元素描述生成多样化的自然语言指令,每个元素生成三条指令。该过程应用于网页、桌面和移动等不同的 GUI 环境,针对各环境的特点进行数据收集和处理,如网页数据通过 Common Crawl 收集并经过严格的筛选和过滤,桌面数据通过自动化的遍历代理收集,移动数据则利用现有的开源数据(如 AMEX)并进行重新生成高质量的描述和指令。
- 基于轨迹的上下文感知数据扩展:利用公开可用的代理轨迹数据来模拟具有上下文的接地任务,构建文本动作历史和文本 - 图像交错历史两种类型的上下文设置。对于轨迹数据中的每个接地步骤,使用上述数据管道生成详细的分步指令,对于非接地动作则使用基于规则的方法进行自然语言编码。通过收集来自多个数据源(如 GUI-Odyssey、Android in the Zoo、Android Control、Android in the Wild 和 AMEX)的轨迹数据,共收集了 992K 个带有上下文的样本。
模型训练与推理
- 模型架构:基于 Aria 模型构建,Aria 是一种多模态原生的 MoE 模型,具有 39 亿激活参数,支持高分辨率图像(在 Aria-UI 中扩展到最大 3920×2940 分辨率),通过将图像分割成小块来处理高分辨率图像,并采用类似 NaViT 的方法保持图像原始比例以确保位置准确性。
- 训练过程:采用两阶段训练程序。第一阶段,利用所有单步接地数据训练 Aria-UI 的基础 GUI 接地能力,模型根据给定的 GUI 图像和指令生成接地答案(元素的相对像素点坐标),并将同一 GUI 图像的所有样本分组为多轮对话格式;第二阶段,将带有文本和文本 - 图像交错历史设置的上下文感知数据输入模型,进一步增强动态设置下的接地能力,同时额外添加 20% 的单步数据样本以保持通用接地能力并避免过拟合。
- 推理过程:Aria-UI 输出归一化到 [0, 1000] 的接地像素坐标,并可以将历史代理动作和接地动作作为聊天历史,在动态环境中形成更强的接地系统。
具体应用场景
- 自动化任务执行:在各种需要与 GUI 交互的自动化任务中发挥关键作用,如自动化测试、智能助手操作等。例如,在软件测试过程中,Aria-UI 可以根据测试脚本中的指令自动在软件界面上执行操作,模拟用户行为,提高测试效率和准确性。
- 智能设备控制:用于控制智能设备(如智能手机、平板电脑、智能电视等)的界面操作,实现更加便捷的用户交互。用户可以通过语音或文本指令,让 Aria-UI 在设备界面上执行相应操作,如打开应用、切换设置、播放媒体等。
- 无障碍访问辅助:帮助残障人士或有特殊需求的用户更方便地使用 GUI 应用程序,通过将用户的指令转换为界面操作,实现无障碍访问。例如,视力障碍用户可以通过语音指令让 Aria-UI 在屏幕上找到特定元素并执行操作,提高他们对数字设备的使用能力。
- 虚拟代理与客服系统:在虚拟代理或客服系统中,Aria-UI 可以理解用户的问题并在相关的 GUI 界面上查找答案或执行操作,为用户提供更加准确和高效的服务。例如,在在线客服场景中,Aria-UI 可以根据用户的咨询在相关系统界面中查找信息并回复用户,或者引导用户完成一系列操作来解决问题。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











