Hugging Face 最新发布了一款轻量级多模态模型SmolVLM2,专为视频内容分析而设计。该模型以高效性和适应性为核心目标,旨在将视频理解能力扩展到从手机到服务器的各种设备上。SmolVLM2 提供了三种不同规模的模型(2.2B、500M 和 256M 参数),其中 500M 和 256M 模型是目前发布的最小的视频语言模型。
- 官方介绍:https://huggingface.co/blog/smolvlm2
- 模型:https://huggingface.co/collections/HuggingFaceTB/smolvlm2-smallest-video-lm-ever-67ab6b5e84bf8aaa60cb17c7
- Demo:https://huggingface.co/spaces/HuggingFaceTB/SmolVLM2
SmolVLM2 的核心理念:高效与普及
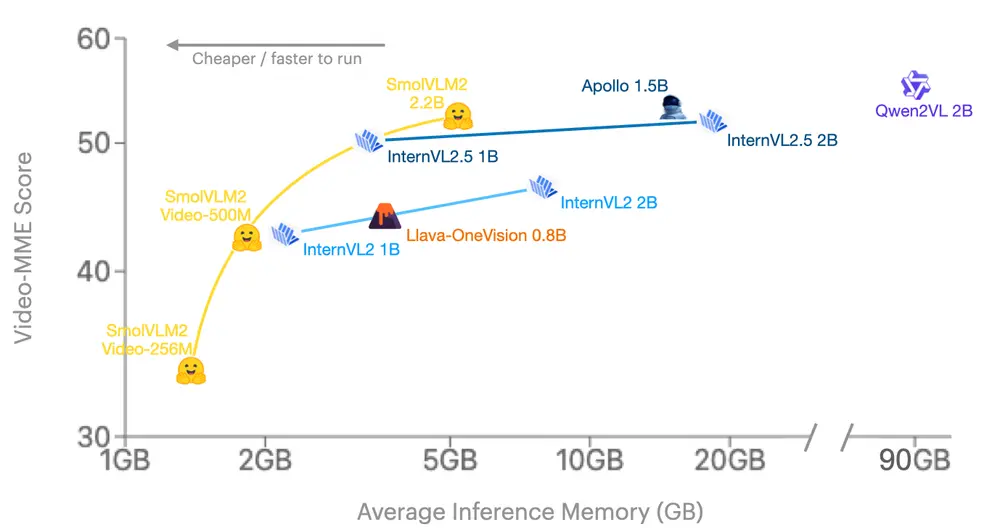
SmolVLM2 的发布标志着视频理解领域的一次重要转变——从依赖大量计算资源的大规模模型转向能够在任何地方运行的高效模型。Hugging Face 的目标是让视频理解技术变得更加普及,适用于各种设备和场景,包括移动设备、嵌入式系统和边缘计算环境。
为了实现这一目标,SmolVLM2 不仅提供了强大的性能,还显著降低了内存消耗和计算需求。此外,该模型支持 MLX(Python 和 Swift API),便于开发者在多种平台上快速集成和部署。
模型规格与性能
1. SmolVLM2-2.2B:视觉和视频任务的首选
- 参数规模:22亿参数
- 特点:
- 是解决复杂视觉和视频任务的理想选择。
- 在 Video-MME(视频领域的关键基准)上表现优异,优于其他同规模模型。
- 内存效率极高,甚至可以在免费的 Google Colab 环境中运行。
- 应用场景:
- 处理带有图像的数学问题。
- 阅读照片中的文本。
- 理解复杂图表和科学视觉问题。
2. SmolVLM2-500M:小而强大的视频模型
- 参数规模:5亿参数
- 特点:
- 性能接近 SmolVLM2-2.2B,但体积仅为后者的不到四分之一。
- 在视频理解能力上表现出色,适合对计算资源有限的应用场景。
- 意义:
- 展示了小型模型在保持高性能的同时大幅减少资源消耗的可能性。
3. SmolVLM2-256M:实验性的超小型模型
- 参数规模:2.56亿参数
- 特点:
- 是一个实验性版本,探索了小型模型在视频理解领域的极限。
- 虽然性能略逊于较大规模的模型,但仍具有一定的实用价值。
- 用途:
- 激发创造性应用和专门的微调项目。
技术亮点
1. 数据混合学习
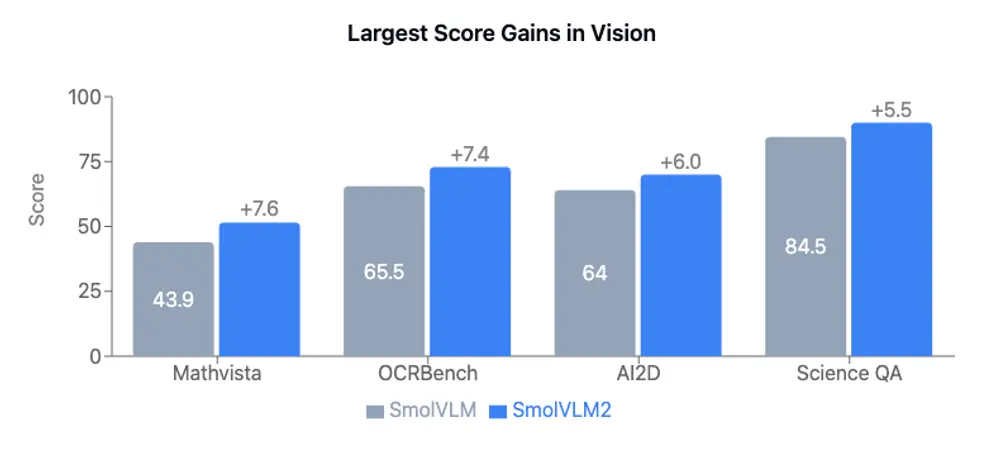
SmolVLM2 的性能提升得益于 Hugging Face 在《阿波罗:大型多模态模型中的视频理解探索》中提出的数据混合学习方法。这种方法实现了视频/图像性能的良好平衡,使模型能够更好地处理多样化的任务。
2. 内存效率
SmolVLM2 在内存消耗方面优于现有模型。即使是最小的 256M 版本,也能在资源受限的环境中运行,为边缘计算和移动端应用提供了可能性。
3. 综合基准测试
Video-MME 是视频领域的权威基准,覆盖了多种视频类型、不同时长(11秒到1小时)、多种数据模态(包括字幕和音频)以及高质量专家注释(涵盖900个视频,总计254小时)。SmolVLM2 在该基准上的表现证明了其广泛适用性和可靠性。
SmolVLM2 的实际应用
为了展示 SmolVLM2 的多功能性,Hugging Face 构建了三个演示应用程序,涵盖了以下功能:
- 视觉和视频理解。
- 图像中的文本识别。
- 科学图表解析。
此外,SmolVLM2 还支持通过 Transformers 和 MLX 快速集成到现有工作流中。开发者可以通过对话 API 轻松运行推理,无需复杂的输入准备。
微调与开发支持
Hugging Face 提供了详细的微调指南,帮助开发者根据具体需求优化 SmolVLM2。例如:
- 使用较小的 500M 模型时,推荐完全微调以获得最佳效果。
- 对于较大的 2.2B 模型,可以尝试 QLoRA 或 LoRA 方法进行微调。
微调示例基于 VideoFeedback 数据集中的视频字幕,相关代码已公开在 Colab 笔记本中,方便开发者快速上手。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











