小红书 hi lab 团队正式发布 dots.vlm1 ——这是“dots”模型家族中的首款视觉-语言模型(VLM),标志着其在多模态理解方向上的重要突破。
- GitHub:https://github.com/rednote-hilab/dots.vlm1
- 模型:https://huggingface.co/rednote-hilab/dots.vlm1.inst
- Demo:https://dotsvlm.xiaohongshu.com
该模型基于 12亿参数的自研视觉编码器 NaViT 与 DeepSeek-V3 大语言模型 构建,在视觉感知、图文推理和跨模态理解任务中展现出接近当前最优(SOTA)的性能,同时在纯文本任务上也保持了良好的通用能力。
不同于简单拼接现有组件的做法,dots.vlm1 从训练策略、数据构建到架构设计,均体现了系统性的技术创新。
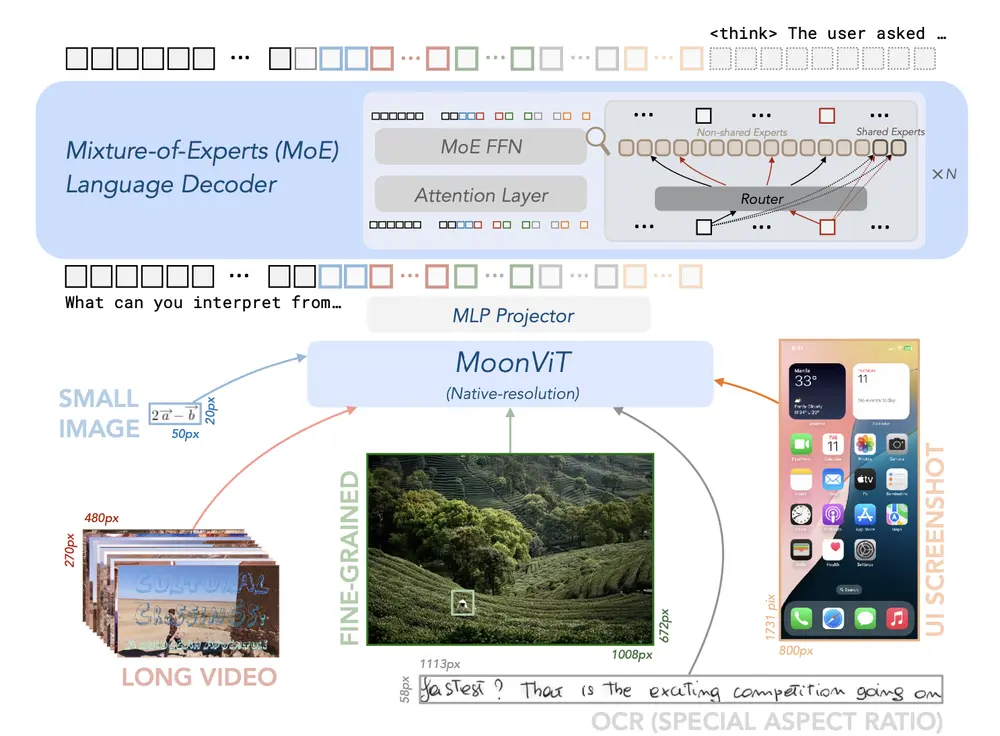
核心架构:从零构建的视觉编码器 + 高性能语言模型
✅ NaViT:原生支持动态分辨率的视觉编码器
NaViT 是一个完全从零训练(而非微调已有模型)的视觉主干网络,具备以下关键特性:
- 42层 Transformer 架构,采用 SwiGLU 激活函数与 2D 旋转位置编码(RoPE),增强空间建模能力
- 原生支持动态分辨率输入,无需固定尺寸裁剪或缩放,适应不同尺度图像
- 两阶段训练策略,参考 AimV2 设计:
- 阶段一:基础预训练
- 输入统一为 224×224 图像
- 使用 NTP(Next Token Prediction in Images)与 NPG(Next Patch Generation)双重监督信号,提升图像内部结构理解能力
- 阶段二:分辨率扩展训练
- 逐步提升输入分辨率至千万级像素(如 1440×1440)
- 引入 OCR、目标定位(grounding)、视频帧等多样化高分辨率数据,增强模型泛化性
- 阶段一:基础预训练
这种训练方式显著提升了模型对文档、图表等复杂视觉内容的感知上限。
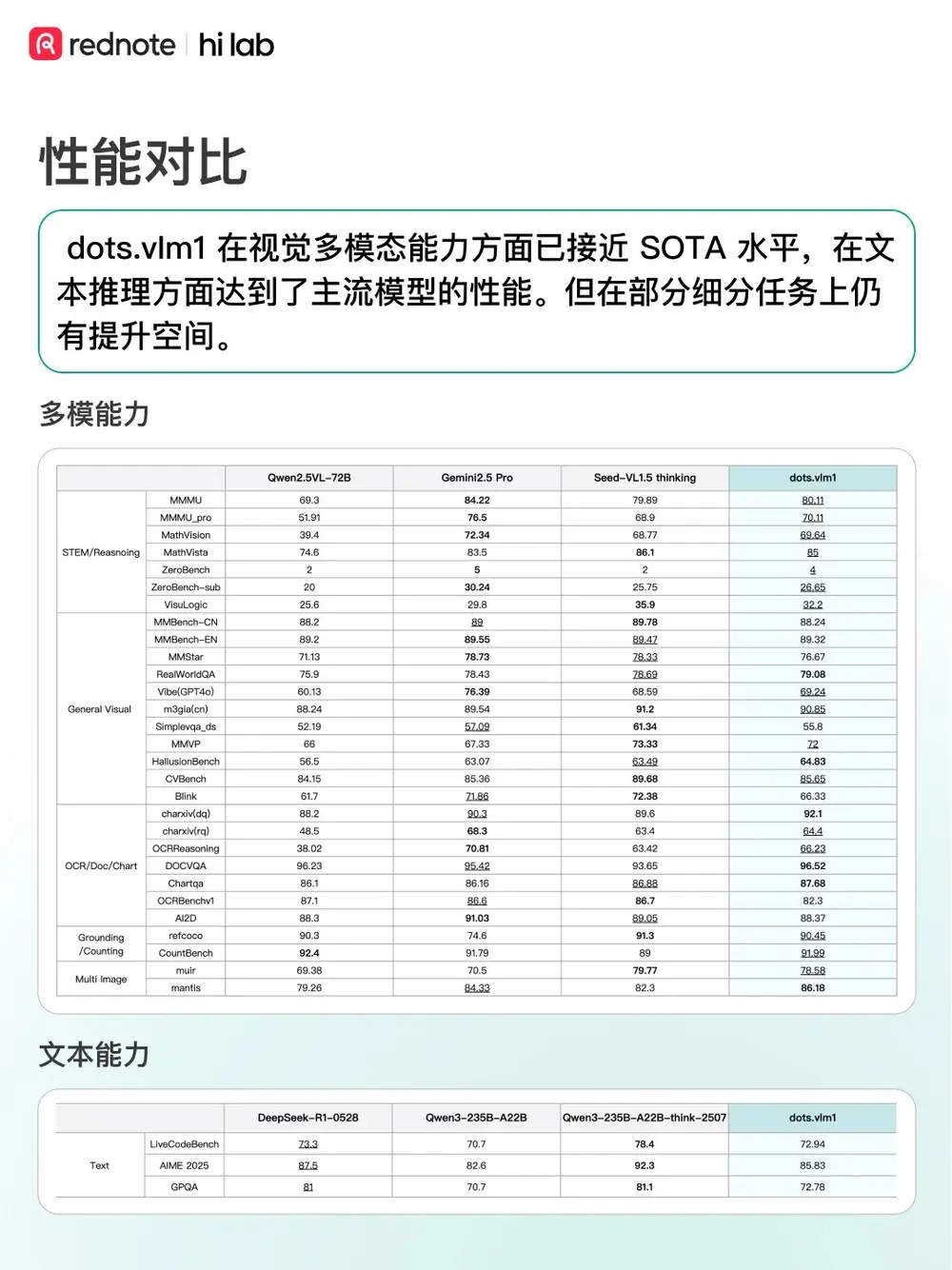
模型能力表现
经过大规模预训练与精细化后训练,dots.vlm1 在多个维度展现出强大能力:
| 类别 | 表现 |
|---|---|
| 视觉-语言任务 | 在 MMMU、MathVista 等高难度多模态基准上,性能接近 Gemini 2.5 Pro 与 Seed-VL1.5 thinking,处于开源模型领先水平 |
| OCR 与版面理解 | 在文档图像理解、图文对齐、表格识别等任务中表现突出,得益于高质量合成数据与自研 OCR 数据参与训练 |
| 数学与代码推理 | 在 AIME、LiveCodeBench 等任务中,表现与 DeepSeek-R1-0528 相当,具备较强的通用推理能力 |
| 复杂文本推理 | 在 GPQA 等需要深度知识推理的任务上仍有提升空间,是后续优化重点 |
注:当前性能评估基于公开基准与团队内部测试集。
数据策略:高质量、多样化、强对齐
数据是多模态模型性能的基石。dots.vlm1 的训练数据构建策略具有鲜明特色:
1. 跨模态互译数据
覆盖多种图像类型与对应文本描述,包括:
- 图像 + 替代文本(Alt Text)
- 图表 + 结构化标注(如 JSON 形式的数据说明)
- 多语言文档图像 + OCR 标注结果
- 视频帧 + 时间对齐字幕
这类数据强化了模型对“图像说了什么”的基本理解能力。
2. 跨模态融合数据
通过自研多模态系统生成更高阶的训练样本:
- 利用强大 VLM 重写网页内容,将图文混排页面转化为结构化描述,提升图文语义对齐质量
- 自研 OCR 工具解析 PDF 文档,生成带版面信息的图文对,用于训练模型理解文档布局
- 引入遮挡训练(Masked Image Modeling 类似策略),让模型学会从局部推测整体
这些策略有效提升了模型在真实场景下的图文理解鲁棒性。
应用潜力与技术意义
dots.vlm1 不只是一个性能出色的模型,更代表了一种端到端、可扩展的多模态建模范式:
- 统一处理多种视觉输入:无论是自然图像、图表、文档截图还是界面截图,均可在同一框架下解析
- 支持细粒度图文交互:可完成 grounding(指代表达)、密集描述、跨模态检索等任务
- 轻量高效架构设计:视觉编码器仅12亿参数,配合高效训练策略,具备良好部署潜力
对于需要处理复杂图文内容的应用场景——如知识库构建、智能客服、自动化办公、教育辅助等——dots.vlm1 提供了一个兼具性能与灵活性的新选择。
未来方向
团队明确表示,dots.vlm1 是 dots 系列多模态演进的第一步。后续工作将聚焦于:
- 进一步提升复杂推理能力,特别是在 GPQA、AIME-hard 等挑战性任务上
- 增强视频理解能力,扩展至时序建模与动态内容解析
- 推进模型轻量化与推理优化,支持边缘设备部署
- 探索以 VLM 为核心的统一感知框架,整合检测、OCR、描述生成与语义理解
此外,解析文档中的图片内容(如图表语义提取)也将成为重点攻关方向。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











