小红书 hi lab 团队近期发布了一款名为 dots.ocr 的多语言文档解析模型。它不是传统OCR工具的简单升级,而是一次架构层面的重构——将布局检测与内容识别统一在一个视觉-语言模型(VLM)中,同时保持准确的阅读顺序输出。
尽管其基于仅 17亿参数的LLM 作为基础,dots.ocr 在多项任务上达到了当前最优(SOTA)水平,展现出小模型也能实现高性能的可能性。
✅ 核心优势
1. 性能领先:在关键指标上达到SOTA
在标准测试集 OmniDocBench 上,dots.ocr 表现全面:
- 文本识别准确率高
- 表格结构还原能力强
- 阅读顺序保持良好
尤其值得注意的是,在公式识别方面,其表现接近甚至媲美更大规模的模型(如 Doubao-1.5 和 Gemini 1.5 Pro),说明其在复杂语义理解上的潜力。
数据参考:EN、ZH 指标来自 OmniDocBench 的端到端评估结果。
2. 多语言支持扎实,低资源语言表现突出
针对非英语语种的文档处理,许多现有模型存在明显短板。而 dots.ocr 在内部构建的 dots.ocr-bench 多语言基准上,展现了更强的泛化能力。
无论是拉丁语系、阿拉伯语,还是东亚语言(如日文、韩文),模型在布局检测和文本识别两个环节均表现出稳定优势,尤其对低资源语言的支持更具实用性。
数据参考:多语言指标基于 dots.ocr-bench 的端到端评估。
3. 架构统一,使用灵活
传统文档解析流程通常依赖多个独立模块:先用目标检测模型做版面分析,再分别调用OCR、表格识别、公式识别等子系统,流程复杂且易出错。
dots.ocr 则采用单一视觉-语言模型完成所有任务。通过更换输入提示(prompt),即可切换不同功能,例如:
prompt_layout_only_en:仅提取布局prompt_ocr:完整OCR解析prompt_grounding_ocr:定位+识别
这种设计不仅简化了部署流程,也验证了VLM在文档理解任务中具备与专业检测模型(如 DocLayout-YOLO)相竞争的能力。
4. 推理速度快,资源消耗低
得益于17亿参数的紧凑结构,dots.ocr 在推理速度上优于多数基于大模型的同类系统。这意味着:
- 更低的部署成本
- 更快的响应时间
- 更适合边缘设备或高并发场景
对于需要实时处理大量文档的应用场景(如知识库构建、自动化办公),这一特性尤为关键。
⚖️ 与其他模型的对比
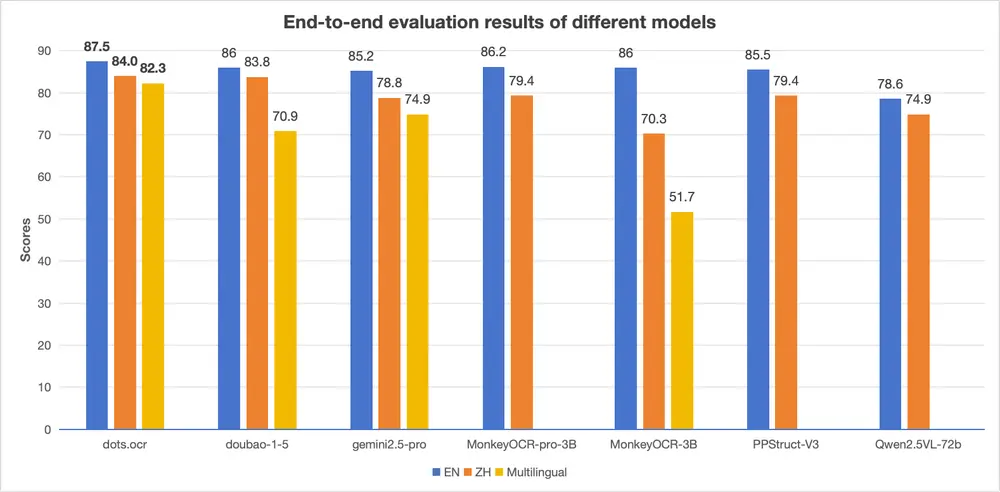
注:性能对比基于公开测试集及团队内部评估。
⚠️ 当前局限性
尽管表现优异,dots.ocr 仍处于持续迭代阶段,存在以下几点限制:
1. 复杂元素处理有待提升
- 表格:对嵌套、跨页或高度非结构化的表格,还原精度尚未完全理想。
- 数学公式:虽已具备基本识别能力,但对复杂LaTeX结构的还原仍有误差。
- 图像内容:目前无法解析文档中的插图、图表或图像文字(如截图中的说明文字)。
2. 特定情况下的解析失败风险
- 分辨率过低或字符过小:当字符像素比例过低时,识别准确率下降。建议:
- 提高PDF转图像的DPI(推荐200)
- 图像总像素不超过11289600(约3360×3360),以保证推理效率
- 连续特殊字符干扰:如
...或___可能导致输出重复。可通过切换提示词缓解。
3. 大文件处理尚未优化
目前模型未针对大规模PDF文档的批量吞吐进行专项优化,在处理上百页文档时可能存在性能瓶颈。
🔮 未来方向
团队已明确下一步研发重点:
- 提升表格与公式的解析精度,尤其是复杂排版场景下的结构还原
- 增强OCR鲁棒性,覆盖更多字体、噪声、倾斜文档等边缘情况
- 开发更高效的推理机制,支持长文档、大批量处理
- 探索基于VLM的通用感知框架,整合:
- 通用目标检测
- 图像描述生成
- OCR与语义理解
- 实现图片内容解析:让文档中的图表、示意图也能被“读懂”
团队强调,这些目标的实现离不开社区协作与开放反馈。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











