随着AI系统逐渐向多模态方向发展,视觉感知模型的角色也变得更加复杂。传统的视觉编码器通常针对特定任务进行优化,例如图像分类、目标检测或语言生成,但这种碎片化的方法不仅增加了模型的复杂性,还限制了其在开放世界场景中的通用性和可扩展性。
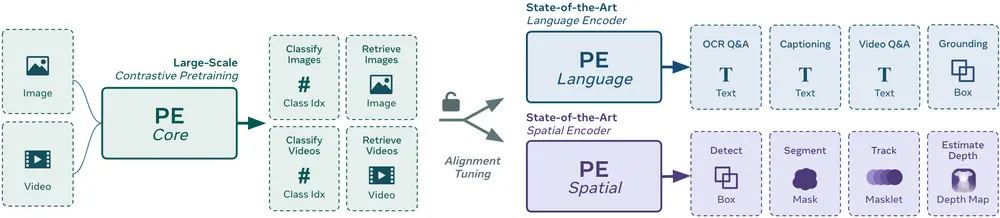
为了解决这一问题,Meta AI 推出了感知编码器 (Perception Encoder, PE),一款通过单一对比学习目标训练的通用视觉编码器。PE 不仅在多个视觉任务中表现出色,还展示了如何通过精心设计的训练方法和对齐策略实现统一的视觉表征。这为构建高效、可扩展的多模态 AI 系统提供了新的可能性。
- GitHub:https://github.com/facebookresearch/perception_models
- 模型:https://huggingface.co/collections/facebook/perception-encoder-67f977c9a65ca5895a7f6ba1
感知编码器的核心特点
1. 统一的对比学习目标
与传统方法依赖多种预训练目标(如对比学习、描述生成和自监督学习)不同,PE 仅使用单一的对比视觉-语言目标进行训练。这种方法简化了模型的设计,同时展示了对比学习在生成通用视觉表征方面的潜力。
2. 多尺度架构
PE 提供三种不同的模型变体,分别适用于不同的计算资源和任务需求:
PEcoreB(基础规模) PEcoreL(大型规模) PEcoreG(超大规模,参数量达 20 亿)
这些模型能够处理从图像到视频的广泛任务,并在分类、检索和多模态推理方面表现出强大的性能。
3. 针对下游任务的对齐策略
尽管 PE 使用单一的对比学习目标,但它在中间层具有分布式的通用表征。为了适应不同的下游任务,Meta 引入了两种对齐策略:
语言对齐:用于视觉问答、描述生成等语言相关任务。 空间对齐:用于检测、跟踪、深度估计等空间理解任务,结合自蒸馏和 SAM2 的空间对应蒸馏技术。
训练方法:两阶段流程
第一阶段:鲁棒的对比学习
PE 的训练始于一个大型精选图像-文本数据集(包含 54 亿对),并通过一系列增强技术提高模型的准确性和鲁棒性。这些增强技术包括:
渐进式分辨率缩放:逐步增加输入图像的分辨率以提升细节捕捉能力。 大批量大小:使用高达 13.1 万的批量大小,确保模型在多样化数据上的泛化能力。 优化器选择:采用 LAMB 优化器以加速收敛。 位置编码:引入 2D RoPE(旋转位置编码)以更好地建模空间信息。 数据增强与掩码正则化:通过调整数据增强策略和掩码正则化减少过拟合。
第二阶段:视频理解的引入
在第二阶段,PE 使用视频数据引擎合成高质量的视频-文本对。该引擎整合了来自感知语言模型(PLM)的描述、帧级描述和元数据,并通过 Llama 3.3 进行总结。这些合成的标注使得 PE 能够通过简单的帧平均微调扩展到视频任务。
性能表现:跨模态的卓越能力
1. 图像任务
PE 在广泛的图像基准测试中展现了强大的零样本泛化能力。以下是 PEcoreG 的一些关键结果:
ImageNet-val上达到86.6%的准确率。 ImageNet-Adversarial上达到92.6%的准确率。 ObjectNet上达到88.2%的准确率。 在细粒度分类数据集(如 iNaturalist、Food101 和 Oxford Flowers)上表现优异。
这些结果表明,PE 不仅匹配甚至超越了许多在私有数据集(如 JFT-3B)上训练的专有模型。
2. 视频任务
PE 在视频任务中同样表现出色,在零样本分类和检索基准测试中实现了最先进的性能。特别是:
在分类任务上比仅使用图像的基线提高了+3.9%。 在检索任务上提高了+11.1%。
值得注意的是,PE 在视频任务中仅使用简单的平均池化(而非复杂的时序注意力机制),这进一步证明了高质量训练数据的重要性。
消融研究:验证设计的有效性
Meta 进行了一系列消融实验,验证了 PE 各个组件的有效性:
视频数据引擎:合成视频数据显著提升了模型在视频任务中的表现。 对齐策略:语言对齐和空间对齐分别增强了模型在语言和空间任务中的性能。 架构简单性:即使没有复杂的时序建模,PE 依然能够生成高质量的视频表征。
这些实验结果突显了 PE 设计的稳健性和高效性。
意义与展望
感知编码器的推出标志着视觉编码器设计的一个重要突破。它证明了通过单一对比学习目标和适当的对齐策略,可以构建一个通用且高效的视觉编码器。PE 不仅在各自领域匹配了专门的模型,还以统一的方式实现了这一目标,为多模态 AI 系统的发展铺平了道路。
开源贡献
Meta 已将 PE 的代码库和 PE 视频数据集开源,为研究社区提供了一个可重现且高效的基础。这一举措无疑将推动多模态 AI 的进一步发展,并为未来的研究提供宝贵的资源。
未来方向
随着视觉推理任务的复杂性和范围不断扩大,PE 为实现更集成和更强大的视觉理解提供了一条清晰的道路。未来的研究可以进一步探索如何将 PE 应用于更多实际场景,例如自动驾驶、医疗影像分析和虚拟助手等领域。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章




暂无评论...











