程序化视频理解正在成为构建智能视觉系统的基础设施。从内容审核到自动化标注,从辅助功能到视频搜索引擎,开发者需要一种高效、可靠的方式,将原始视频帧转化为结构化、可搜索、可操作的数据。

为此,Inference.net 研究团队联合 Grass 推出 ClipTagger-12B —— 一个专为大规模视频理解设计的 120亿参数开源视觉语言模型(VLM)。该模型已在万亿级视频帧标注任务中完成实战验证,在保持前沿性能的同时,将推理成本降低 15–17 倍,为视频 AI 应用提供了全新的性价比选择。
✅ 开源地址:https://huggingface.co/inference-net/ClipTagger-12b
🚀 托管 API:https://docs.inference.net/use-cases/video-understanding
为什么需要专用视频理解模型?
通用大模型(如 GPT-4、Claude)虽具备图像理解能力,但在处理视频时面临三大瓶颈:
- 成本过高:按 token 计费模式在高帧率视频处理中迅速累积;
- 输出不一致:同一场景在不同帧中可能生成语义漂移的描述;
- 非结构化输出:自然语言响应难以直接用于数据库索引或规则引擎。
ClipTagger-12B 正是为解决这些问题而生。它不是通用模型的“副产品”,而是从训练数据、架构设计到输出格式,全链路专为视频理解优化。
核心优势一览
| 特性 | 说明 |
|---|---|
| 🔥 前沿质量 | 与 GPT-4.1 相当,优于 Claude 4 Sonnet |
| 💰 成本极低 | 比 GPT-4.1 便宜 15 倍,比 Claude 便宜 17 倍 |
| 🏭 生产就绪 | 已在万亿级视频帧标注场景中验证 |
| ⏱ 时间一致性 | 跨帧语义稳定,适合时间序列分析 |
| 📦 结构化输出 | 每帧输出固定模式 JSON,便于下游处理 |
| 🔓 完全开源 | 可本地部署,无需依赖闭源 API |
模型能力:像理解文本一样理解视频
ClipTagger-12B 的核心能力是将每一帧图像转化为结构化标签数据,例如:
{
"scene": "城市街道",
"objects": ["行人", "电动车", "交通灯"],
"actions": ["过马路", "等待红灯"],
"context": "白天,晴天,高峰时段"
}
这种模式一致的输出,使得开发者可以:
- 构建可全文检索的视频数据库;
- 实现自动化内容审核与合规检测;
- 提升视频无障碍访问能力(如为视障用户提供实时描述);
- 驱动基于视觉语义的推荐系统。
更重要的是,模型具备时间感知能力,在连续帧间保持语义连贯性,避免“同一辆车一会儿是红色,一会儿是蓝色”的逻辑错误。
技术架构与优化
基础架构
ClipTagger-12B 基于 Gemma-12B 架构构建,并针对视觉-语言对齐任务进行了深度调优。选择 Gemma 作为基础,兼顾了性能、开源合规性与部署灵活性。
推理优化:FP8 量化无损提速
模型采用 FP8 量化技术,在 RTX 40 系列和 H100 GPU 上实现最大吞吐量。实测表明,FP8 与 BF16 相比无显著质量损失,但显存占用更少、推理速度更快。
| 硬件支持 | 说明 |
|---|---|
| NVIDIA H100 | 原生支持 FP8,推理效率最大化 |
| RTX 4090/4080 | 兼容运行,适合本地开发与中小规模部署 |
训练方法:高质量蒸馏确保输出一致性
由于直接标注百万级视频帧成本高昂,ClipTagger-12B 采用 教师-学生知识蒸馏 策略:
- 教师模型:多个高质量闭源模型(如 GPT-4V、Claude)生成初始标注;
- 数据集:100 万个来自公开视频的精选帧,覆盖多样场景(室内、户外、运动、静态等);
- 目标:学习教师模型的判断逻辑,同时保证输出格式统一、语义稳定。
这一方法在控制成本的同时,确保了模型的泛化能力与输出可靠性。
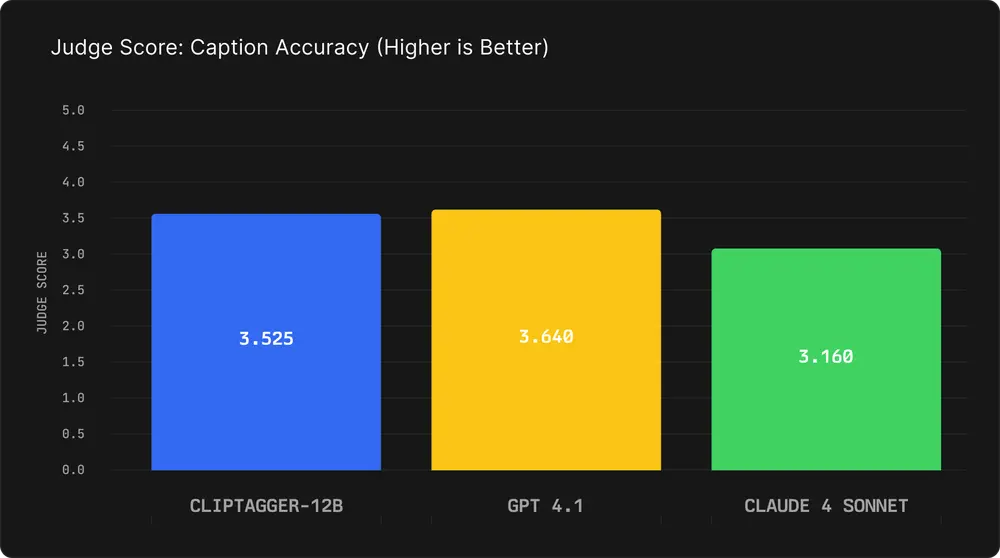
性能对比:媲美 GPT-4.1,远超 Claude
我们使用 Gemini 2.5 Pro 作为独立评判模型,对各模型生成的标注质量进行盲评打分(满分 5 分),并在标准指标上对比结果。
标注质量评估(内部测试集)
| 模型 | 平均评判分 | ROUGE-1 | ROUGE-L | BLEU |
|---|---|---|---|---|
| ClipTagger-12B | 3.53 | 0.674 | 0.520 | 0.267 |
| GPT-4.1 | 3.64 | 0.581 | 0.376 | 0.119 |
| Claude 4 Sonnet | 3.16 | 0.463 | 0.281 | 0.060 |
✅ 结论:ClipTagger-12B 质量接近 GPT-4.1,显著优于 Claude 4 Sonnet
尤其在 描述准确性和信息完整性 方面,ClipTagger-12B 表现突出,且输出更结构化、更少冗余。
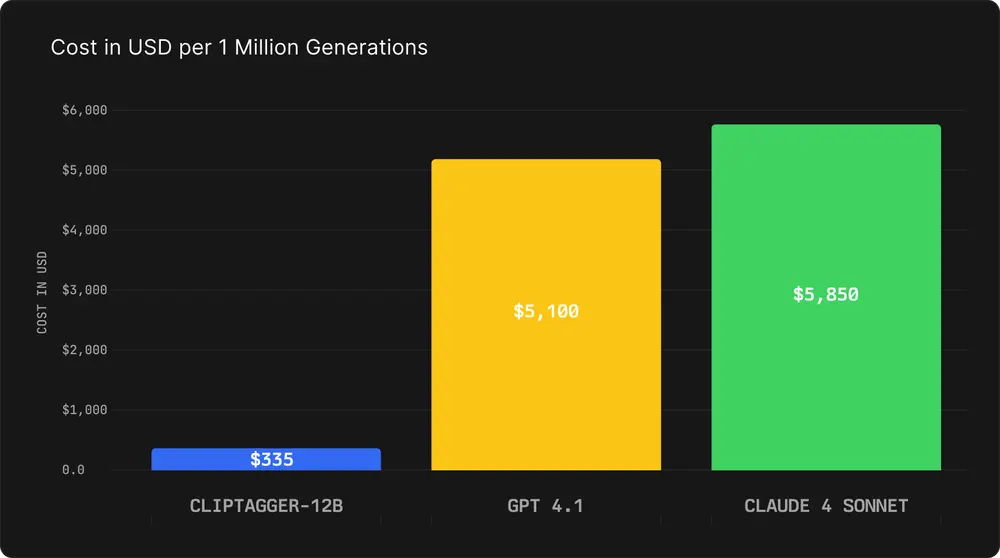
成本对比:真正的“平民化”视频理解
以下是基于典型请求(700 输入 token + 250 输出 token)的成本测算:
| 模型 | 输入/百万token | 输出/百万token | 单次生成成本 | 每百万次成本 |
|---|---|---|---|---|
| ClipTagger-12B | $0.30 | $0.50 | $0.000335 | $335 |
| GPT-4.1 | $3.00 | $12.00 | $0.0051 | $5,100 |
| Claude 4 Sonnet | $3.00 | $15.00 | $0.00585 | $5,850 |
📌 成本优势:
- 相比 GPT-4.1,节省 93% 成本(约 15 倍)
- 相比 Claude 4 Sonnet,节省 94% 成本(约 17 倍)
对于每天处理百万级视频帧的企业而言,这意味着每年节省数百万美元的 API 开支。
使用方式:灵活部署,开箱即用
1. 开源模型本地部署
模型已发布于 Hugging Face,支持本地加载与推理:
支持输入格式:JPEG、PNG、WebP、GIF(单帧 ≤ 1MB)
2. 托管 API(推荐用于生产)
对于需要高可用、自动扩缩容和批处理能力的团队,推荐使用 Inference.net 提供的托管服务:
- ✅ 支持批量提交视频帧
- ✅ 自动重试与 Webhook 回调
- ✅ 实时监控与日志追踪
- ✅ 动态扩缩容应对流量高峰
适用场景
ClipTagger-12B 特别适用于以下场景:
- 内容平台:自动生成视频标签、关键词、摘要,提升 SEO 与推荐效果
- 安防监控:实时识别异常行为、人员聚集、物品遗留
- 媒体归档:将历史视频资料转化为可检索数据库
- 无障碍服务:为视障用户提供实时画面描述
- 广告审核:自动识别违规内容、品牌露出、敏感场景
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











