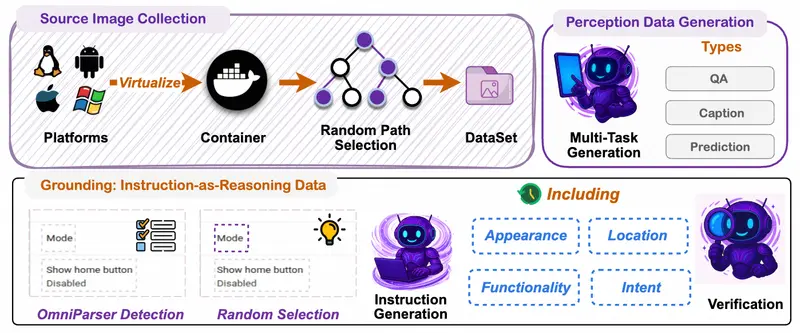
随着多模态大模型的不断发展,我们对技术边界的认知也在持续被刷新。从最初的 QwenVL 到如今的 Qwen2.5 VL,我们在提升模型图像理解能力方面不断取得进步。
今天,阿里 Qwen 项目组正式推出全新多模态统一理解与生成模型——Qwen VLo。这是一款集“理解”与“生成”于一体的先进模型,不仅能够“看懂”世界,更能基于理解进行高质量的再创造,真正实现了从感知到生成的跨越。

⚠️ 注意:Qwen VLo 目前为预览版本,您可通过 Qwen Chat 访问体验。
🌟 如何使用 Qwen VLo?
您可以通过自然语言指令轻松控制图像生成与编辑任务:
- 发送类似“生成一张可爱猫咪的图片”的提示,即可创建新图像;
- 或上传一张已有图像,并输入“给猫咪头上加顶帽子”,即可完成图像修改。
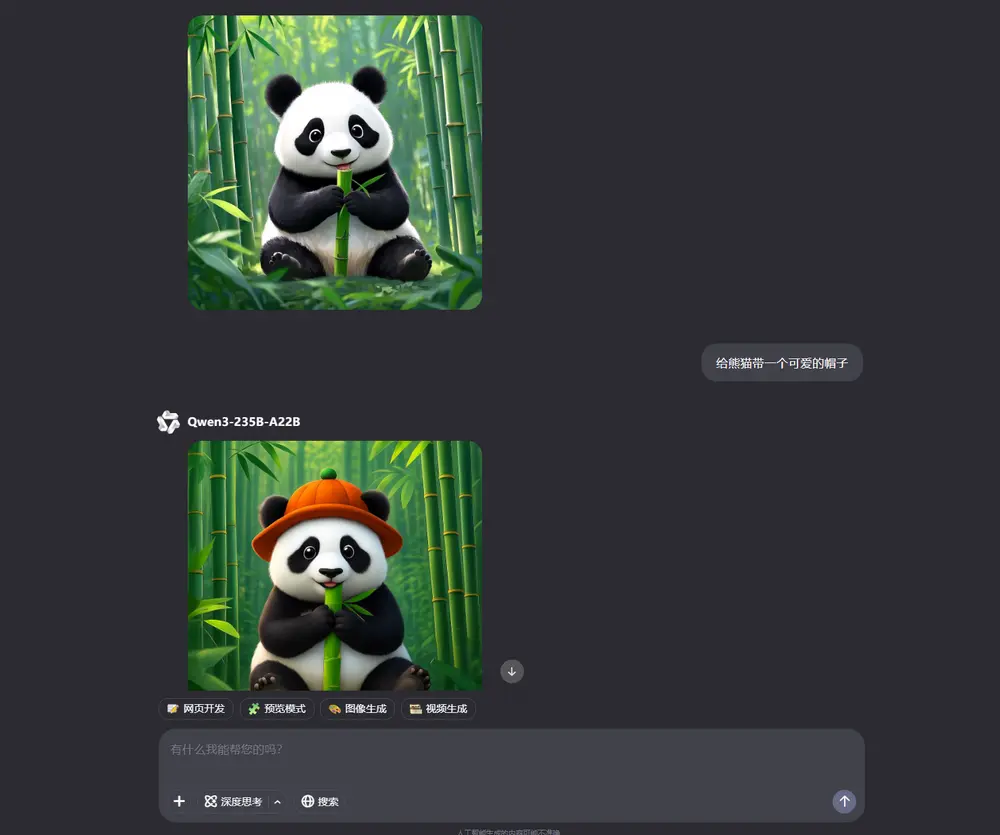
🎨 渐进式生成机制:更灵活、更可控的创作体验
Qwen VLo 采用一种渐进式图像生成机制:从左到右、从上到下逐步构建图像。在生成过程中,模型会不断调整预测内容,确保最终结果在视觉和语义上保持一致。
这种机制不仅提升了生成质量,也为用户带来了更强的交互性与控制力,特别适合需要精细调整的图像任务。
🔍 核心亮点:更精准的理解与更一致的生成
✅ 更精准的内容理解与再创造
相比以往的多模态模型,Qwen VLo 在语义一致性方面有了显著提升。例如,在收到“更换汽车颜色”的指令时,模型不仅能准确识别车型,还能保留原有结构特征,并自然地完成色彩风格转换,使结果既符合预期又不失真实感。
✅ 支持开放指令编辑与复杂修改
Qwen VLo 可响应各种创意性指令,如:
- “将这张画风改为梵高风格”
- “让这张照片看起来像19世纪的老照片”
- “给这张图片添加一个晴朗的天空”
无论是艺术风格迁移、场景重构还是细节修饰,它都能灵活应对。甚至一些传统视觉感知任务(如深度图、分割图、检测图、边缘信息等)也可通过简单指令完成。
此外,Qwen VLo 还能处理包含多个操作的复杂指令,例如同时修改物体、添加文字、更换背景等,实现一次生成多重目标。
✅ 多语言支持,全球通用
Qwen VLo 支持中文、英文等多种语言指令,打破语言壁垒,为全球用户提供统一、便捷的交互体验。
🖼️ 应用样例:像人类画师一样思考与创作
Qwen VLo 的表现更像是一个具备理解与创造力的人类画师,能够根据需求进行多样化的图像生成与修改:
- 直接生成图像:如卡通、写实、插画等;
- 图像修改:替换背景、添加主体、风格迁移;
- 开放指令修改:执行复杂视觉任务,如检测、分割等;
- 多图输入支持(即将上线):支持多张图像理解与生成;
- 动态长宽比支持(部分功能暂未上线):可生成高达 4:1、1:3 等极端比例图像。
不仅如此,Qwen VLo 还能对生成内容进行再分析与理解,例如识别图像中的猫狗品种、判断场景元素等,进一步拓展了其应用场景。
📐 动态分辨率支持:适配多种场景需求
Qwen VLo 采用动态分辨率训练机制,支持任意分辨率和长宽比的图像生成。无论你是要制作海报、插图、网页 Banner 还是社交媒体封面,Qwen VLo 都能灵活应对。
此外,它还引入了一种全新的生成机制:从上到下、从左到右的渐进式生成方式。这一机制尤其适用于带有大量文本的图像任务,如广告设计、漫画分镜等,让用户可以实时观察生成过程并进行微调,获得最佳效果。
🧪 当前局限性
作为预览版本,Qwen VLo 尚存在一些不足之处,包括:
- 生成结果可能不完全符合事实;
- 对原图的理解可能存在偏差;
- 指令执行不够稳定;
- 图像生成与意图理解之间仍有一定差距。
我们正在持续优化模型性能,不断提升其稳定性与鲁棒性。
🚀 下一步展望:用图像表达想法,用生成促进理解
随着多模态大模型逐渐具备双向图文输入输出能力,我们正迈向一种全新的表达与交互方式。未来,模型不仅可以使用文本回答问题,还可以通过图像传递思想与情感。
例如:
- 生成示意图辅助解释复杂概念;
- 添加辅助线、标注关键区域以增强沟通效率。
此外,模型通过生成任务也能反向验证自身的理解是否正确。例如,通过生成分割图、检测图等中间结果来评估自身对图像内容的理解程度,从而进一步提升整体性能。
这将是我们在多模态领域持续探索的重要方向。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











