清华大学的研究人员推出高效语音分离模型TIGER,解决低延迟语音处理系统中的高效率问题。语音分离是指从混合音频信号中准确分离出不同声音源的任务,类似于人类在嘈杂环境中专注于特定语音信号的“鸡尾酒会效应”。
- 项目主页:https://cslikai.cn/TIGER
- GitHub:https://github.com/JusperLee/TIGER
- 模型:https://huggingface.co/JusperLee/TIGER-DnR
- Demo:https://huggingface.co/spaces/fffiloni/TIGER-audio-extraction

主要功能
- 高效语音分离:TIGER能够在保持高分离性能的同时,显著减少模型参数和计算成本。
- 复杂环境适应:通过引入包含噪声和真实混响的EchoSet数据集,TIGER能够更好地适应复杂的真实世界声学环境。
- 跨任务泛化:TIGER不仅在语音分离任务中表现出色,还在电影音效分离等类似任务中展现了良好的泛化能力。
主要特点
- 轻量级架构:通过频带分割策略,TIGER大幅减少了参数数量和计算量,使其更适合在计算资源受限的设备上部署。
- 多尺度选择性注意力模块(MSA):能够提取多尺度特征,增强模型对重要特征的捕捉能力。
- 全频帧注意力模块(F3A):整合时间维度和频率维度的信息,提升模型对全局上下文的建模能力。
- 时间-频率交织结构:通过交替处理时间和频率特征,更高效地提取音频特征。
工作原理
- 频带分割:利用先验知识将频率带划分为不同宽度的子带,重点处理对语音分离更重要的低频和中频带。
- 特征提取:通过MSA模块提取多尺度特征,再通过F3A模块整合全局信息。
- 交替建模:在分离器中,时间路径和频率路径交替处理特征,实现时间-频率交织。
- 频带恢复:将分割后的子带恢复到原始宽度,生成每个说话者的掩模并应用于混合音频,最终通过逆STFT生成清晰语音。
测试结果
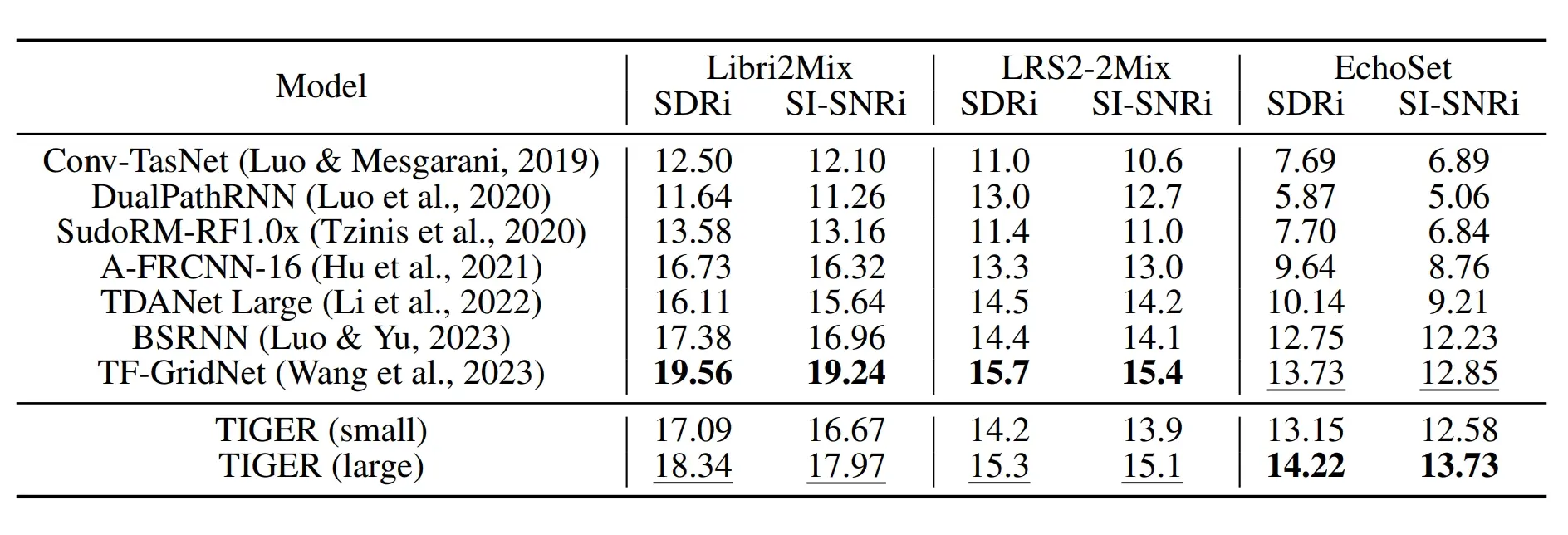
- 性能提升:在EchoSet数据集上,TIGER(large)的SDRi达到14.22 dB,超越了现有的SOTA模型TF-GridNet。
- 效率优化:TIGER(large)的参数数量仅为0.82 M,MACs为15.27 G/s,相比TF-GridNet减少了94.3%的参数和95.3%的计算量。
- 泛化能力:在真实世界数据测试中,TIGER也展现了最佳的分离性能,证明了其在复杂环境下的适用性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











