
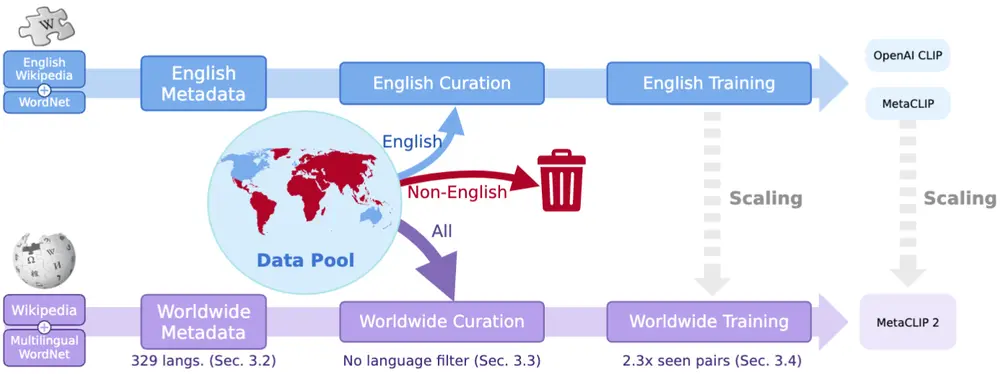
MetaCLIP 2 是一种新型的多语言对比语言-图像预训练(CLIP)模型,旨在从全球范围内的网络数据中学习图像和文本的表示。传统的 CLIP 模型主要基于英语数据进行训练,而 MetaCLIP 2 则扩展了训练范围,涵盖了全球范围内的多语言数据。
例如,MetaCLIP 2 可以处理来自不同语言(如中文、法文、阿拉伯文等)的图像-文本对,从而生成更全面和多样化的视觉和语言表示。
主要功能
- 多语言支持:MetaCLIP 2 能够处理和理解多种语言的图像-文本对,而不仅仅是英语。
- 零样本分类和检索:在没有额外训练的情况下,MetaCLIP 2 可以直接应用于图像分类和检索任务。
- 文化多样性:通过使用全球范围内的数据,MetaCLIP 2 能够更好地捕捉不同地区的文化和社会经济特征。
主要特点
- 打破多语言诅咒:MetaCLIP 2 通过扩展模型容量和训练数据量,成功克服了多语言模型中常见的“多语言诅咒”(即多语言模型的英语性能不如单语言模型)。
- 数据平衡:通过精心设计的元数据和数据平衡算法,MetaCLIP 2 确保了训练数据的多样性和平衡性。
- 高效训练:MetaCLIP 2 采用了高效的数据处理和训练框架,能够在大规模数据上进行有效的训练。
工作原理
- 元数据扩展:MetaCLIP 2 将英语元数据扩展到 300 多种语言,包括多语言 WordNet 和维基百科。
- 数据平衡算法:通过语言特定的子字符串匹配和平衡算法,MetaCLIP 2 确保了非英语数据的训练分布与英语数据相似。
- 训练框架:MetaCLIP 2 设计了一个全球范围内的训练框架,包括增加训练中看到的图像-文本对的数量,并研究了最小可行的模型容量,以适应全球范围内的数据规模。
- 多语言文本编码器:MetaCLIP 2 使用多语言文本编码器(如 XLM-V),以支持多种语言的文本处理。
测试结果
- 零样本分类:在 ImageNet 数据集上,MetaCLIP 2 的 ViT-H/14 模型达到了 81.3% 的准确率,超过了其英语版本(80.5%)。
- 多语言基准测试:MetaCLIP 2 在多个多语言基准测试中取得了新的最高水平,例如 XM3600(64.3%)、Babel-ImageNet(50.2%)和 CVQA(57.4%)。
- 文化多样性:在 Dollar Street、GeoDE 和 GLDv2 等文化多样性基准测试中,MetaCLIP 2 表现优于其他多语言 CLIP 模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...











