在与社区深入交流并综合反馈后,阿里Qwen团队做出一项重要决策:停止使用混合“思维模式”(Thinking Mode)的训练方式,转而采用 Instruct 与 Thinking 模型分离训练 的新策略,以追求更高质量、更专业的模型表现。
今天,Qwen团队正式推出全新版本 ——
Qwen3-235B-A22B-Instruct-2507 及其 FP8 量化版本。
这是一个专注于指令遵循能力的高质量 Instruct 模型,在通用能力、知识覆盖、多语言支持和长上下文理解等方面均有显著提升。我们相信,它将成为你在日常对话、任务执行和内容生成中的得力助手。
🔗 体验地址:https://chat.qwen.ai
📦 Hugging Face:Qwen3-235B-A22B-Instruct-2507 | FP8 版本
💾 ModelScope:主模型 | FP8 版本
为什么放弃“混合思维模式”?
早期的 Qwen3 MoE 模型尝试在一个架构中同时支持 think 和 instruct 两种模式,希望通过条件控制实现灵活切换。然而实践发现:
- 混合训练容易导致模型在两类任务上都难以达到最优
- 思维链(Chain-of-Thought)生成与直接响应之间存在目标冲突
- 用户对输出风格的一致性要求更高
因此,我们决定将路径拆分:
✅ Instruct 模型:专注高质量、直接、准确的指令响应
✅ Thinking 模型:专为复杂推理、逐步分析设计(即将发布)
本次发布的 Qwen3-235B-A22B-Instruct-2507 即为这一新策略下的首款成果。
⚠️ 注意:该模型仅支持非思维模式,不会生成
<think>标签,也无需再设置enable_thinking=False。
主要更新亮点
1. 综合能力全面提升
- 更强的指令遵循能力
- 显著提升的逻辑推理、文本理解、数学解题与代码生成能力
- 工具调用更加稳定可靠
2. 多语言长尾知识增强
- 在低资源语言上的知识覆盖明显改善
- 支持更多小语种问答与翻译任务
3. 输出质量更贴近用户偏好
- 在主观性、开放性任务中对齐更好
- 回答更自然、有帮助,减少机械感
4. 长上下文理解能力升级
- 原生支持 262,144 token 上下文长度
- 在 256K 级长文档摘要、信息抽取等任务中表现优异
模型概览
| 属性 | 值 |
|---|---|
| 模型类型 | 因果语言模型(Causal LM) |
| 训练阶段 | 预训练 + 后训练 |
| 总参数量 | 2350 亿 |
| 激活参数量 | 220 亿(MoE 稀疏激活) |
| 非嵌入参数数 | 2340 亿 |
| 层数 | 94 |
| 注意力机制 | GQA(64 查询头 / 4 键值头) |
| 专家数量 | 128 |
| 每Token激活专家数 | 8 |
| 上下文长度 | 262,144 |
性能对比:全面超越前代
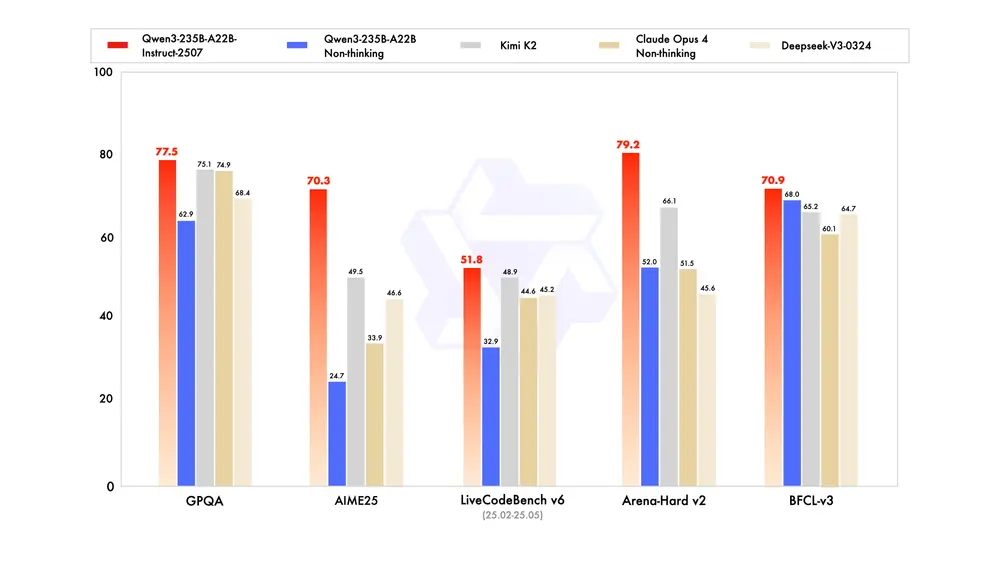
以下是 Qwen3-235B-A22B-Instruct-2507 相较于前一版本及其他主流模型的基准测试结果(数值越高越好):
| 模型 | Qwen3-235B-A22B (旧版) | Qwen3-235B-A22B-Instruct-2507 |
|---|---|---|
| 知识 | ||
| MMLU-Pro | 75.2 | 83.0 |
| MMLU-Redux | 89.2 | 93.1 |
| GPQA | 62.9 | 77.5 |
| SimpleQA | 12.2 | 54.3 |
| CSimpleQA | 60.8 | 84.3 |
| 推理 | ||
| AIME25 | 24.7 | 70.3 |
| ZebraLogic | 37.7 | 95.0 |
| LiveBench 20241125 | 62.5 | 75.4 |
| 编码 | ||
| LiveCodeBench v6 | 32.9 | 51.8 |
| MultiPL-E | 79.3 | 87.9 |
| 对齐 | ||
| Arena-Hard v2* | 52.0 | 79.2 |
| WritingBench | 77.0 | 85.2 |
| 代理能力 | ||
| BFCL-v3 | 68.0 | 70.9 |
| TAU-Retail | 65.2 | 71.3 |
注:Arena-Hard 结果由 GPT-4.1 评估,确保可重复性
从数据可见,新模型在知识、推理、编码和对齐等多个维度均实现大幅跃升,尤其在数学与科学类任务中表现突出。
如何发挥最佳性能?推荐设置
为获得最优体验,建议采用以下配置:
推理参数
temperature: 0.7
top_p: 0.8
top_k: 20
min_p: 0
presence_penalty: 0.5~2.0 (用于抑制重复)输出长度
- 日常任务:建议设置最大输出长度为 8192~16384 tokens
- 复杂生成或长文本处理:可启用完整上下文窗口
提示词技巧
- 数学问题:
“请逐步推理,并将最终答案放在 \boxed{} 中。”
- 选择题:
“请在 answer 字段中仅显示选择字母,例如
"answer": "C"。” - 标准化输出:
在评测或自动化场景中,建议通过提示词统一响应格式。
代理能力:强大且易用
Qwen3 在工具调用方面表现出色。我们推荐结合 Qwen-Agent 框架使用,它已内置:
- 工具调用模板
- JSON 解析器
- MCP 协议支持
你只需定义可用工具(通过 MCP 配置、集成插件或自定义接口),即可快速构建 AI Agent 应用。
这是一个小更新,更大的惊喜正在路上
Qwen3-235B-A22B-Instruct-2507 的发布,标志着我们模型演进策略的重要转变。这不是终点,而是新阶段的开始。
独立训练的 Thinking 模型、更强的多模态版本、更高效的轻量级系列……更多令人期待的产品已在开发中。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...