在当前大模型普遍追求“深度推理”的趋势下,一个更现实的问题逐渐浮现:是否每个问题都需要长篇思维链?
过度使用思维链(Chain-of-Thought, CoT)不仅增加计算开销、拖慢响应速度,还可能导致“过度思考”——对简单问题进行冗余推理,反而影响准确性和用户体验。
为解决这一问题,快手 Kwaipilot 团队正式开源其最新大语言模型:Kwaipilot-AutoThink(简称 KAT)。
KAT 是一个 400亿参数 的开源大模型,首次系统性地引入 “自动思考”(AutoThink)训练范式,让模型学会自主判断何时该深入推理,何时应直接作答,在效率与质量之间实现动态平衡。
核心目标:让推理成为“可选项”,而非“默认项”
传统大模型在处理任务时通常采用固定策略:
- 要么始终启用思维链(CoT),导致简单问题也“绕圈子”;
- 要么完全关闭推理,牺牲复杂任务的表现。
KAT 的突破在于:
它能根据输入任务的复杂性,动态决定是否激活推理路径。
例如:
- 输入:“2+2等于几?” → 模型识别为简单任务,输出
<think_off><answer>4,直接响应。 - 输入:“请推导勾股定理的几何证明” → 模型判定需推理,输出
<think_on><think>...详细步骤...<answer>证毕。
这种“有选择地思考”的能力,使 KAT 在保持高推理性能的同时,显著降低延迟与资源消耗。
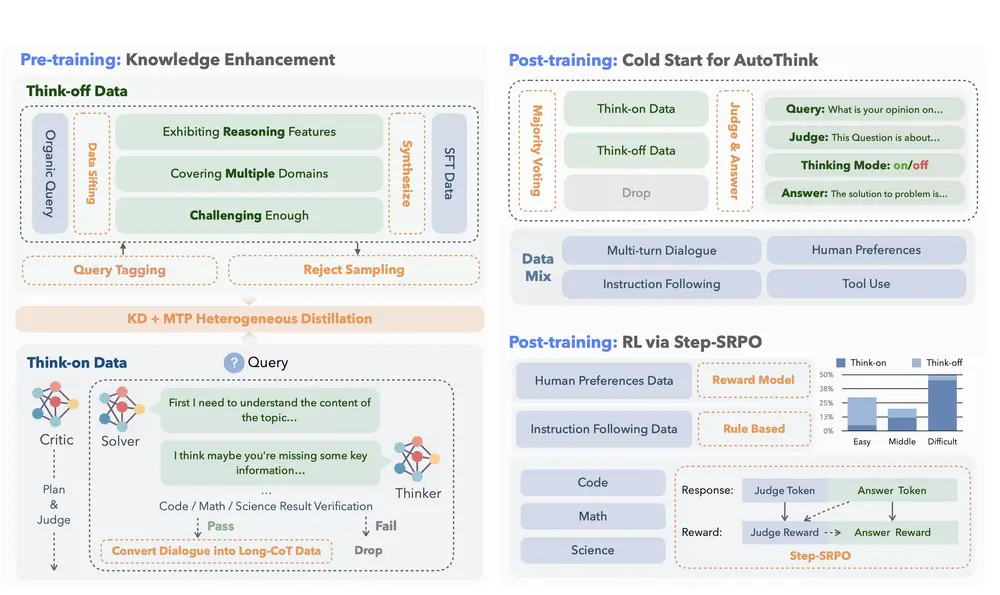
训练方法:两阶段构建“会判断的模型”
KAT 采用简洁高效的两阶段训练流程,兼顾能力获取与模式控制。
阶段一:预训练 —— 分离“推理”与“直答”能力
| 核心理念 | 在知识注入过程中,明确区分两类任务模式 |
|---|
关键技术:
- 双模式数据构建:
Think-off数据:通过自定义标记系统标注的无需推理任务(如事实问答、简单计算)。Think-on数据:由多代理求解器生成的复杂推理样本(如数学证明、代码调试)。
- 知识蒸馏 + 多标记预测(MTP):
- 从教师模型中提取推理路径与答案联合知识;
- 通过预测
<judge>、<think_on/off>等未来标记,增强模型对任务类型的感知能力。
✅ 成果:基础模型在不增加预训练成本的前提下,获得强大的事实记忆与初步推理能力。
阶段二:后训练 —— 让推理“按需触发”
| 核心理念 | 推理不应是默认行为,而应是可优化的决策过程 |
|---|
关键技术:
- Cold-start AutoThink:
- 利用多数投票机制为初始训练提供模式选择先验;
- 结合意图感知提示,帮助模型快速建立“什么问题需要想”的直觉。
- Step-SRPO(Step-wise Supervised Reinforcement Policy Optimization):
- 引入中间监督信号,分别奖励:
- 正确的模式选择(该想的时候想,不该想的时候不绕弯);
- 在选定模式下的答案准确性。
- 实现端到端的结构化优化。
- 引入中间监督信号,分别奖励:
✅ 成果:模型学会仅在推理真正有益时才启动思维链,减少冗余标记使用,提升推理效率。
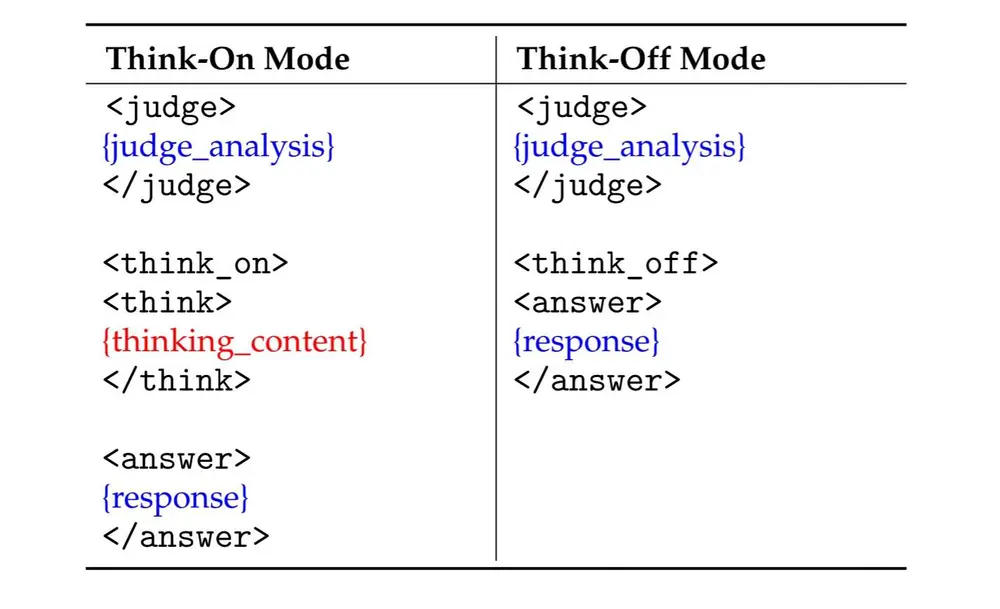
输出格式:结构化响应,机器可解析
KAT 采用标准化标记系统输出响应,确保推理路径清晰、可追溯、可自动化处理。
| 标记 | 作用说明 |
|---|---|
<judge> | 分析输入,判断任务复杂性 |
<think_on> / <think_off> | 明确声明是否启用推理模式 |
<think> | 推理过程开始(仅在 think_on 下出现) |
<answer> | 最终答案输出起点,面向用户 |
这种结构化设计特别适用于下游应用(如代码助手、客服机器人),便于系统自动提取答案或监控推理行为。
主要特点与创新
| 特点 | 说明 |
|---|---|
| ✅ 动态推理门控 | 模型自主决策是否启用 CoT,避免“一刀切” |
| ✅ 高效知识迁移 | 借助 MTP 与知识蒸馏,小模型也能继承强推理能力 |
| ✅ 双模式数据合成 | 多智能体框架生成高质量 think-on 数据,提升训练有效性 |
| ✅ 中间监督强化学习 | Step-SRPO 在训练中同时优化“模式选择”与“答案质量” |
| ✅ 工业级验证 | 已在快手内部编码助手 Kwaipilot 中落地,显著提升开发效率 |
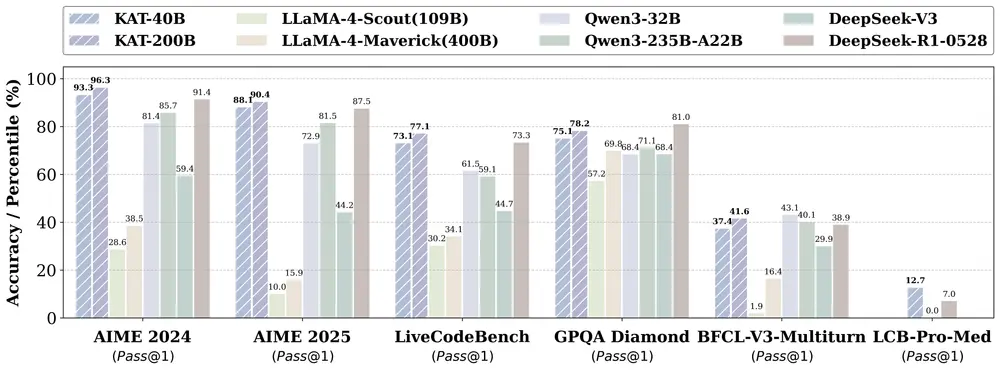
性能表现:多项基准超越现有模型
KAT 在多个权威评测中表现优异,尤其在推理效率与准确性平衡方面展现出领先优势。
数学推理(AIME 系列)
| 模型 | AIME2024 | AIME2025 | 平均标记数 |
|---|---|---|---|
| KAT-40B | 93.3 | 88.1 | 显著低于 SOTA 模型 |
| 其他开源模型 | <85 | <80 | 更高 |
💡 在达到更高分数的同时,使用的推理标记更少,说明其推理更精准、无冗余。
编程能力测试
| 基准 | KAT 表现 | 对比情况 |
|---|---|---|
| LiveCodeBench Pro | 超过所有开源模型 | 优于 Seed、o3-mini 等专有系统 |
| HumanEval | 95.1 | 领先主流开源模型 |
| MBPP | 85.2 | 显著优于同规模模型 |
未来计划
快手团队表示,后续将陆续开源更多资源,推动 AutoThink 范式的广泛应用:
即将发布:
- 📄 配套论文:全面介绍 AutoThink 框架,涵盖:
- Cold-start 初始化机制
- Step-SRPO 算法细节
- 数据构建与奖励函数设计
- 🧩 训练资源开源:
- 双模式标注数据集
- 强化学习训练代码库
- 📦 模型套件扩展:
- 开源 1.5B、7B、13B 参数版本的 KAT 检查点
- 所有模型均采用 AutoThink 门控训练,支持轻量部署
为什么 KAT 值得关注?
| 维度 | 传统模型 | KAT 改进 |
|---|---|---|
| 推理策略 | 固定启用或关闭 CoT | 动态判断,按需推理 |
| 资源消耗 | 高(尤其简单任务) | 显著降低冗余计算 |
| 响应速度 | 受限于长 CoT 输出 | 简单问题秒回 |
| 可控性 | 推理路径不可控 | 结构化输出,易于监控与集成 |
| 实际部署 | 易出现“过度思考” | 已在工业场景验证有效性 |
KAT 不仅是一个更强的模型,更是一种新的推理范式探索——
让 AI 学会“停下来想想要不要想”,或许是通向高效智能的重要一步。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











