阿里通义Qwen团队发布全新代码大模型系列 Qwen3-Coder,这是目前 Qwen 系列中最具代理(Agent)能力的代码模型。此次发布的最大版本为 Qwen3-Coder-480B-A35B-Instruct,采用 MoE 架构,总参数量达 4800 亿,激活参数 350 亿,原生支持 256K token 上下文长度,并可通过 YaRN 技术扩展至 1M token。
- 体验地址:https://chat.qwen.ai
- 项目主页:https://qwenlm.github.io/zh/blog/qwen3-coder
- GitHub:https://github.com/QwenLM/Qwen3-Coder
- Demo:https://huggingface.co/spaces/Qwen/Qwen3-Coder-WebDev
| 模型名 | 类型 | 尺寸 | 下载 |
|---|---|---|---|
| Qwen3-Coder-480B-A35B-Instruct | instruct | 256k | Hugging Face • ModelScope |
| Qwen3-Coder-480B-A35B-Instruct-FP8 | instruct | 256k | Hugging Face • ModelScope |
该模型在多项代理式编程任务中表现突出,在 Agentic Coding(自主编程)、Agentic Browser-Use(浏览器操作)和 Agentic Tool-Use(工具调用)等评测中达到开源模型中的 SOTA 水平,整体能力可与 Claude Sonnet 4 相当。

多尺寸覆盖,面向不同场景
Qwen3-Coder 系列包含多个尺寸版本,满足从轻量级开发到复杂工程任务的不同需求。本次优先推出最强版本 480B-A35B-Instruct,旨在为研究者和开发者提供当前最具潜力的开源代码 Agent 基座。
预训练:系统性扩展提升代码能力
为了全面提升模型的编程理解与生成能力,Qwen3-Coder 在预训练阶段进行了多维度“Scaling”:
- 数据规模扩展:使用总计 7.5TB 的高质量训练数据,其中代码数据占比 70%,兼顾通用语言、数学推理与编程能力。
- 上下文长度优化:原生支持 256K token 上下文,结合 YaRN 技术可扩展至 1M,特别针对代码仓库级任务(如 Pull Request 分析)和动态数据处理进行优化。
- 合成数据增强:利用 Qwen2.5-Coder 对低质量代码数据进行清洗与重写,显著提升训练数据整体质量,形成正向反馈闭环。
后训练:聚焦真实场景的强化学习
不同于多数模型集中于竞赛类代码生成任务,Qwen3-Coder 的后训练更关注真实软件工程场景下的执行驱动学习。
1. 大规模 Code RL 训练
Qwen团队构建了基于执行反馈的强化学习框架,在丰富的实际编码任务上开展训练。通过自动扩展测试用例,生成大量高质量训练样本,充分释放强化学习潜力。实验表明,这种方法不仅提升了代码执行成功率,也对其他编程任务产生正向迁移效果。
Qwen团队将持续探索“难解易验”(Hard to Solve, Easy to Verify)的任务类型,作为强化学习的理想训练场。
2. Agent-Level 强化学习
在 SWE-Bench 这类真实软件工程任务中,模型需在复杂环境中自主规划、调用工具、接收反馈并迭代决策——这是一个典型的长周期强化学习(Long-Horizon RL)问题。
为此,Qwen团队在 Qwen3-Coder 上实施了 Agent RL 训练策略,鼓励模型通过多轮交互完成任务。核心挑战在于环境可扩展性,Qwen团队为此构建了一套可验证环境扩展系统,依托阿里云基础设施,支持同时运行 20,000 个独立沙箱环境,实现大规模并行训练与评估。
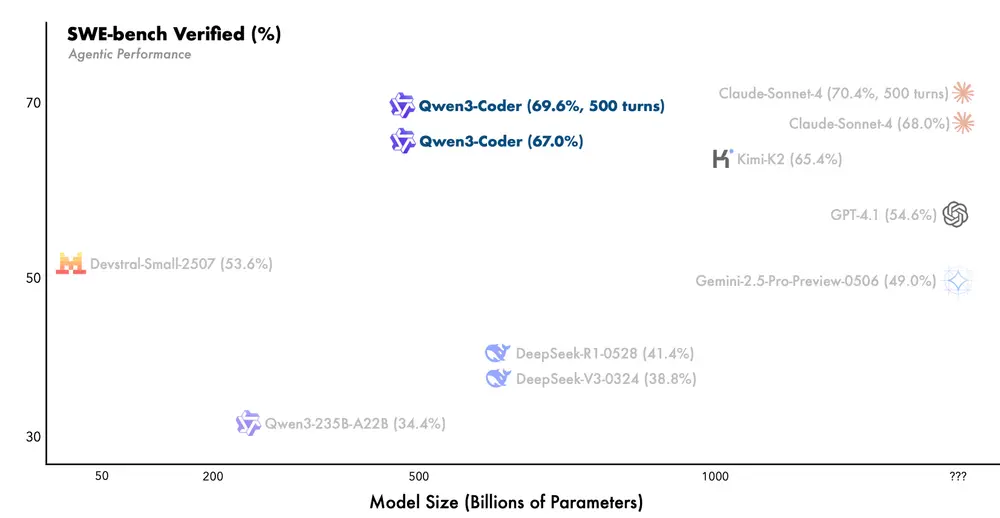
最终,Qwen3-Coder 在 SWE-bench Verified 基准上达到开源模型最优性能。
开源工具:Qwen Code CLI
为更好发挥 Qwen3-Coder 的代理编程能力,Qwen团队同步推出并开源命令行工具 Qwen Code。
Qwen Code 基于 Gemini Code 项目二次开发,针对 Qwen3-Coder 的推理特性,重构了 prompt 工程与工具调用协议,显著提升其在复杂编程任务中的表现。它支持与多种主流编程工具集成,如 Claude Code、Cline 等,可作为灵活的基础组件嵌入现有开发流程。
Qwen团队希望 Qwen3-Coder 能成为开发者手中的“通用代码代理”,真正实现 Agentic Coding in the World —— 在真实世界中自主完成编程任务。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











