
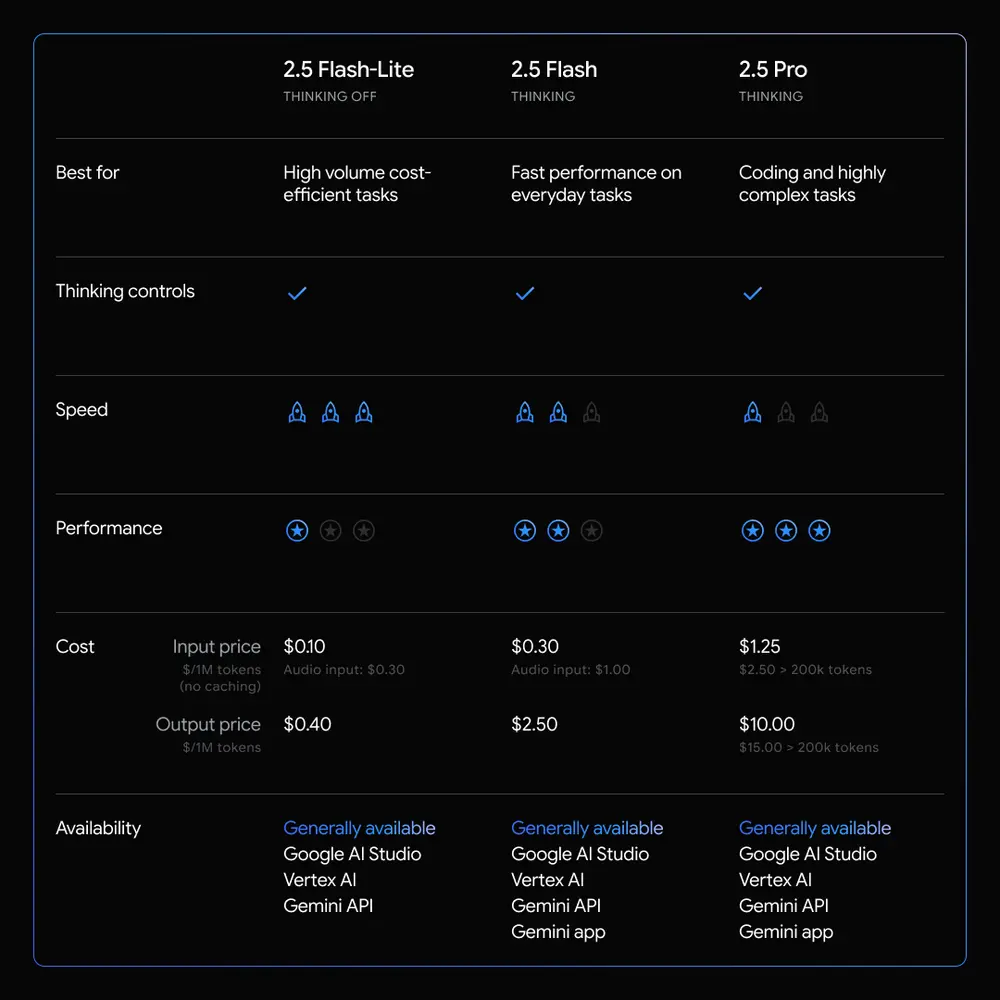
谷歌宣布,Gemini 2.5 Flash-Lite 正式进入稳定版本并全面开放使用。作为 Gemini 2.5 模型系列中速度最快、成本最低的成员,该模型旨在为大规模生产场景提供高性价比的智能推理能力。
其定价为:
- 输入:每百万 token 0.10 美元
- 输出:每百万 token 0.40 美元
同时,谷歌还将音频输入成本在预览期基础上降低了40%,进一步优化使用体验。
随着 Flash-Lite 的正式上线,Gemini 2.5 系列现已形成完整的产品矩阵,涵盖从高性能到高效率的多种模型选择,满足不同应用场景的需求。

核心优势:速度、成本与质量的平衡
Gemini 2.5 Flash-Lite 专为对延迟敏感且请求量大的任务设计,在保持轻量化的同时并未牺牲输出质量,适用于翻译、分类、内容摘要等高频应用场景。
✅ 顶级速度
在广泛的提示测试中,Gemini 2.5 Flash-Lite 的响应延迟显著低于前代模型 Gemini 2.0 Flash-Lite 和 2.0 Flash,能够支持实时性要求高的服务部署。
✅ 卓越成本效益
这是目前 Gemini 2.5 系列中成本最低的模型,适合需要处理海量请求但预算有限的应用场景。结合低延迟特性,使其成为高吞吐系统(如自动化内容处理、大规模分类任务)的理想选择。
✅ 智能且轻量
尽管定位为轻量级模型,Gemini 2.5 Flash-Lite 在编码、数学、科学推理、多模态理解等多个基准测试中的整体表现优于 2.0 Flash-Lite,体现了“小而强”的技术进步。
✅ 功能齐全
开发者在使用该模型时,仍可获得完整的 Gemini 生态支持,包括:
- 100万 token 上下文窗口
- 可控推理预算(可选择性启用深度推理)
- 原生工具调用支持:如 Google 搜索结果对接(grounding)、代码执行、URL 内容解析等
实际应用案例
自预览版发布以来,已有多个企业将 Gemini 2.5 Flash-Lite 成功应用于实际业务中,展现出强大的实用价值。
🛰️ Satlyt:优化卫星数据处理
Satlyt 正在构建一个去中心化的空间计算平台,利用该模型进行在轨遥感数据摘要、自主任务调度和星间通信解析。得益于其高速响应,关键诊断任务的延迟降低 45%,功耗相比基线模型下降 30%。
🎥 HeyGen:AI 视频内容全球化
HeyGen 使用 Gemini 2.5 Flash-Lite 自动化视频脚本规划、内容分析,并将视频内容翻译成180多种语言,显著提升了本地化效率,为用户提供个性化的跨国视频体验。
📄 DocsHound:长视频转文档自动化
DocsHound 利用该模型处理长时视频,提取关键帧并生成结构化文档。整个流程延迟低、速度快,不仅能快速生成产品说明文档,还可作为 AI 代理的训练数据源,效率远超传统人工方式。
🔍 Evertune:品牌AI影响力监测
Evertune 借助 Gemini 2.5 Flash-Lite 快速扫描和综合各大 AI 模型中的品牌提及与语义表现,为客户提供动态、实时的品牌认知洞察,响应速度大幅提升。
如何开始使用?
开发者可通过以下方式接入 Gemini 2.5 Flash-Lite,该模型现已在以下平台开放:
⚠️ 注意:如果你此前使用的是预览版本别名,建议尽快切换至正式名称
gemini-2.5-flash-lite。谷歌计划于 8月25日 移除旧的预览别名。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











