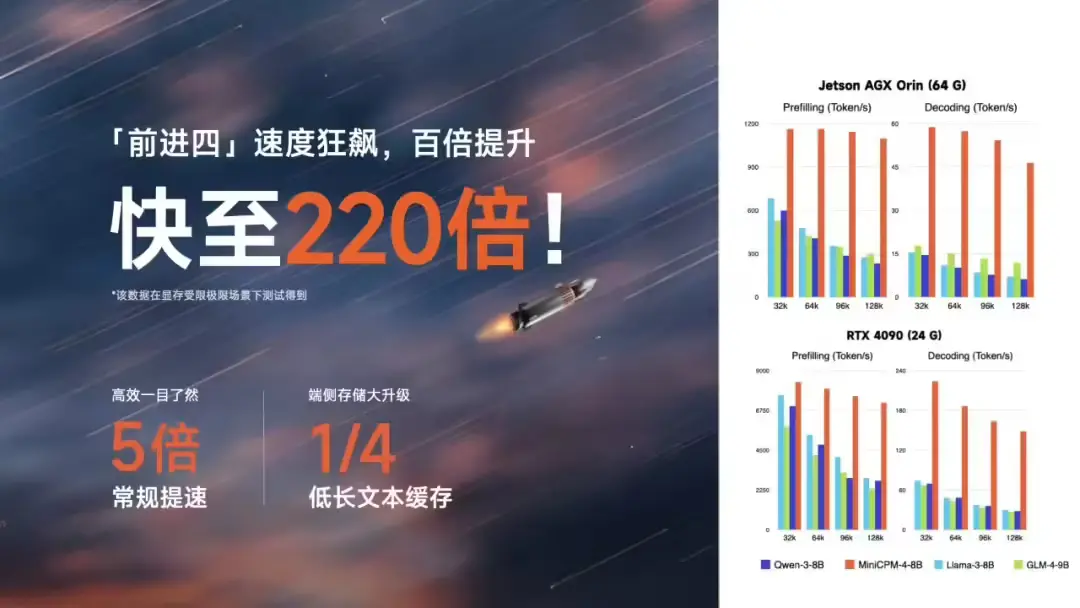
6 日晚,面壁智能正式发布了新一代高效端侧大语言模型 MiniCPM 4.0。该系列模型以极致轻量化和高效推理为核心目标,结合自研 CPM.cu 推理框架 和稀疏注意力机制,在端侧设备上实现了惊人的性能提升——极限场景下最高提速达 220 倍,常规任务平均提速约 5 倍。
MiniCPM 4.0 提供两个核心版本:
- 8B 版本:主打“双频换挡”架构,兼顾长文本处理效率与短文本精度
- 0.5B 版本:小巧灵活,号称“轻巧灵动的最强小小钢炮”
两款模型均可部署于 vLLM、SGLang、LlamaFactory、XTuner 等主流开源框架,为开发者提供高度灵活的使用体验。
- GitHub:https://github.com/OpenBMB/MiniCPM
- 模型:https://huggingface.co/collections/openbmb/minicpm4-6841ab29d180257e940baa9b

核心技术亮点
1. 极致高效的模型架构:InfLLM v2 + 双频换挡机制
MiniCPM 4.0-8B 引入了全新的「高效双频换挡」机制,能够根据任务类型自动切换注意力模式:
- 长文本 / 复杂推理:启用稀疏注意力机制,每个词元仅需与不到 5% 的其他词元计算相关性,大幅降低计算复杂度
- 短文本 / 高精度需求:切换至稠密注意力,确保输出质量
这种动态切换机制解决了传统单一架构难以兼顾长短文本效率的问题,真正实现“快而不失准”。
2. 高效学习算法:模型风洞 2.0 + BitCPM 三值量化
- 模型风洞 2.0(Model Tunnel 2.0):引入下游任务 Scaling 预测方法,使训练配置搜索更加精准高效
- BitCPM 技术:将模型参数压缩为三值,实现位宽减少高达 90%,显著降低内存占用与推理开销
此外,MiniCPM 4.0 还采用了 FP8 低精度训练 和 多词元预测策略,进一步提升训练效率。
3. 高质量训练数据体系:UltraClean + UltraChat v2
- UltraClean:构建基于验证驱动的迭代式数据清洗流程,开源高质量中英文预训练数据集
- UltraChat v2:覆盖知识密集型、推理密集型、指令遵循、长文本理解、工具调用等多个维度,全面提升模型能力边界
4. 高性能推理系统:CPM.cu + ArkInfer
- CPM.cu:专为 CUDA 平台设计的轻量级高效推理引擎,融合稀疏注意力、模型量化与投机采样技术,充分发挥 MiniCPM 4.0 的效率优势
- ArkInfer:跨平台部署系统,支持一键适配多种后端环境,极大简化模型落地流程
MiniCPM 4.0 家族成员一览
| 模型名称 | 参数规模 | 功能特点 |
|---|---|---|
| MiniCPM4-8B | 80 亿 | 主力模型,训练 8 万亿 token,旗舰性能 |
| MiniCPM4-0.5B | 5 亿 | 轻量级版本,训练 1 万亿 token,适用于边缘设备 |
| MiniCPM4-8B-Eagle-FRSpec | - | Eagle 头用于 FRSpec 加速推测推理 |
| MiniCPM4-8B-Eagle-FRSpec-QAT-cpmcu | - | 结合量化与推测推理,加速效果更强 |
| MiniCPM4-8B-Eagle-vLLM | - | vLLM 格式 Eagle 头,提升生成速度 |
| MiniCPM4-8B-marlin-Eagle-vLLM | - | 量化版 Eagle 头,进一步提升推理效率 |
| BitCPM4-0.5B / BitCPM4-1B | 5 亿 / 10 亿 | 极端三值量化版本,位宽压缩 90% |
| MiniCPM4-Survey | 80 亿 | 支持用户输入查询,自主生成可信调研报告 |
| MiniCPM4-MCP | 80 亿 | 支持 MCP 工具调用,实现 AI 自主执行任务 |

实测性能表现亮眼
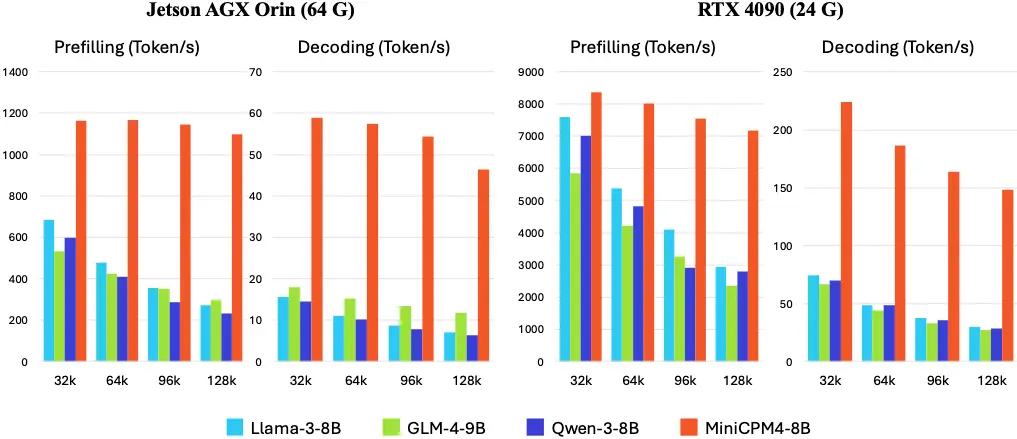
在典型端侧芯片上的测试结果显示,MiniCPM 4.0 在长文本处理任务中表现出远超同类模型的性能优势:
- Jetson AGX Orin 平台:相比 Qwen3-8B,生成速度提升约 7 倍
- RTX 4090 平台:在 128K 长文本的“大海捞针”任务中,展现出极高的准确率和响应效率
尤其值得注意的是,随着文本长度增加,MiniCPM 4.0 的性能优势愈发明显,充分体现了其对长文本任务的优化深度。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章


暂无评论...