Anthropic正式推出全新的Claude Opus 4.6大模型,作为其旗舰级智能模型的重磅升级版本,该模型在编程能力、长上下文处理、多任务推理等核心维度实现全面突破,同时首次在Opus系列中开放100万令牌上下文窗口(测试版),并完成办公工具、开发者平台的多项功能迭代。此次升级定价保持不变,今日已在claude.ai、官方API及各大主流云平台全面上线,开发者可通过API调用claude-opus-4-6模型进行开发。
Claude Opus 4.6不仅在Terminal-Bench 2.0、Humanity's Last Exam等权威基准测试中斩获行业最高分,还在金融、法律等专业知识工作场景实现性能跃升,同时在安全性上保持行业领先水平,做到智能提升与安全防护的双重兼顾。此外,Anthropic还同步升级了Claude Code、Claude in Excel等产品,并推出Claude in PowerPoint研究预览版,让大模型与日常办公、开发场景的协同更高效。
核心能力突破:编程、推理、长上下文处理全面升级
Claude Opus 4.6的核心升级集中在编程能力强化与长上下文处理两大核心方向,同时将优化后的能力延伸至财务分析、文献研究、文档处理等日常工作场景,适配更复杂的智能体任务与知识工作需求。
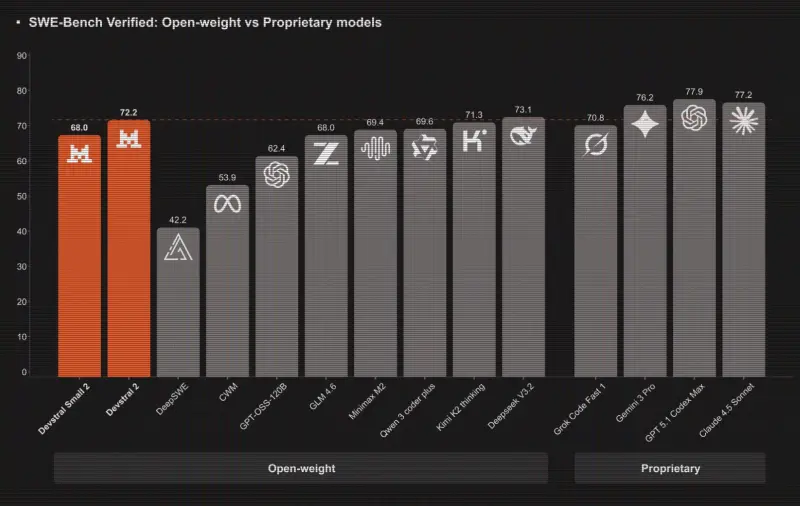
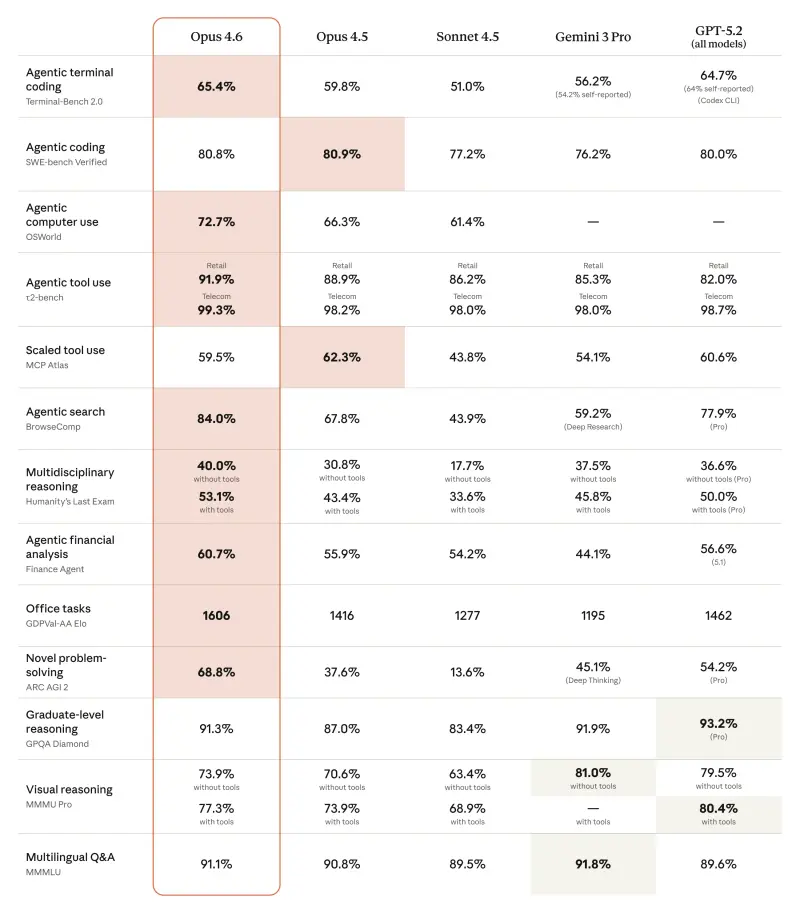
- 编程能力再攀新高,智能体开发更可靠:相比前代模型,Opus 4.6的编程规划更周密,能支持更长时间的智能体连续任务,在大型代码库中的运行稳定性大幅提升,同时代码审查与调试能力显著增强,可自主发现并修正代码错误。在智能体编码权威评估Terminal-Bench 2.0中,该模型拿下行业最高分,成为智能体编程领域的标杆模型。
- 百万令牌上下文落地,上下文衰减大幅改善:这是Opus系列首次支持100万令牌上下文窗口(测试版),成为Anthropic旗下长上下文处理能力最强的模型。其在长文本中检索信息的能力实现质变,能在数十万令牌范围内稳定跟踪信息,大幅减少信息漂移,可捕捉到前代模型Opus 4.5遗漏的隐藏细节。在测试长上下文信息检索能力的MRCR v2 8针100万令牌变体基准中,Opus 4.6得分76%,而Sonnet 4.5仅得18.5%,彻底解决了AI模型常见的“上下文衰减”问题。
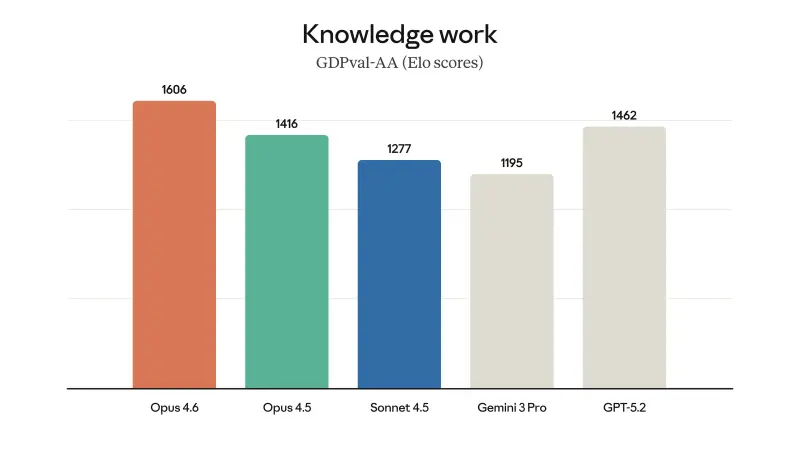
- 多学科推理能力领先,专业场景性能跃升:在复杂多学科推理测试Humanity's Last Exam中,Opus 4.6领先于所有其他前沿大模型;在评估金融、法律等领域专业知识工作能力的GDPval-AA测试中,其表现优于业界次佳模型约144个埃洛等级分,较前代Opus 4.5提升190分。此外,在衡量模型在线查找冷门信息能力的BrowseComp评估中,该模型同样表现优于所有同类模型,专家级推理能力实现显著提升。
- 自主任务处理能力优化,适配日常工作全场景:Opus 4.6可将强化后的能力应用于财务分析、学术研究、文档/电子表格/演示文稿的创建与编辑等日常工作,在Anthropic的Cowork场景中可实现自主多任务处理,无需人工手把手指导即可完成复杂工作流程,成为知识工作的高效辅助工具。
安全性升级:零安全牺牲,防护措施与安全评估全面强化
Claude Opus 4.6的智能提升并未以牺牲安全性为代价,反而在行为对齐、安全评估、风险防护等方面实现新突破,整体安全性达到业界前沿模型顶级水平,相关细节已在Claude Opus 4.6系统卡中详尽披露。
- 行为失准率更低,过度拒绝率创历史新低:在Anthropic的自动化行为审计中,Opus 4.6的欺骗、谄媚、鼓励妄想、配合滥用等行为失准率显著降低,行为对齐程度与前代Opus 4.5(Anthropic迄今对齐程度最高的前沿模型)持平。同时,该模型成为所有Claude模型中过度拒绝率最低的版本,在避免有害输出的同时,减少对合法合理请求的误拒,提升使用体验。
- 开展最全面安全评估,引入多项全新测试方法:Anthropic为Opus 4.6完成了旗下所有模型中最全面的安全评估,首次应用多种全新测试手段,并升级了既有评估体系——新增针对用户福祉的安全评估、对模型拒绝危险请求能力的复杂测试、对模型秘密执行有害行为的升级评估,同时引入可解释性领域的新方法,深入解析模型行为逻辑,发现标准测试易遗漏的潜在风险。
- 新增针对性防护措施,聚焦高风险领域管控:针对Opus 4.6表现出优势的高风险领域,Anthropic开发了全新防护措施,其中因模型网络安全能力大幅增强,专门研发六种新的网络安全探测方法,追踪各类潜在滥用行为。同时,加速模型在网络安全防御领域的正向应用,利用其能力发现并修补开源软件中的漏洞,助力网络安全防御者平衡竞争环境。Anthropic表示,未来将根据网络安全威胁变化持续调整防护措施,或推出实时干预机制阻止模型滥用。
产品与API重磅更新:开发者可控性提升,办公工具协同更高效
为充分发挥Claude Opus 4.6的核心能力,Anthropic同步完成了Claude开发者平台(API)、Claude Code、办公工具系列的多项功能迭代,既为开发者提供更灵活的控制能力,也让普通用户能在日常办公中更高效地使用模型能力。
开发者平台(API):六大功能升级,可控性与灵活性拉满
此次API更新的核心是提升开发者对模型的自定义控制能力与长任务适配能力,同时开放更大的输出与上下文空间,适配复杂智能体开发需求,所有功能均为Claude Opus 4.6量身打造:
- 自适应思维:打破此前“开启/关闭”扩展思维的二元选择,模型可根据上下文线索自主判断是否需要深入推理,在默认设置下仅对有需要的任务启用扩展思维,开发者可按需调整,平衡推理深度与使用效率。
- 四级努力程度可控:新增低、中、高、最大四个努力级别,开发者可通过
/effort参数轻松调节,针对简单任务调低级别减少成本与延迟,针对复杂任务调高级别提升推理质量,实现智能水平、速度、成本的精准把控。 - 上下文压缩:当对话或智能体任务接近上下文窗口限制时,模型会自动总结并替换较早的上下文内容,无需人工干预即可让智能体执行更长时间的连续任务,彻底摆脱上下文限制的束缚。
- 128k输出令牌:支持高达128k令牌的单次输出,模型可一次性完成长文档创作、大型代码编写等需要大输出量的任务,无需将任务分解为多个请求,提升开发与使用效率。
- 仅限美国的推理:为有地域合规需求的开发者提供美国本地推理服务,定价为常规令牌价格的1.1倍,满足不同行业的地域部署要求。
- 百万令牌上下文定价:100万令牌上下文窗口(测试版)对超过20万令牌的提示适用高级定价,基础定价保持不变,仍为每百万令牌输入$5、输出$25。
核心产品:Claude Code引入智能体团队,办公工具适配性大幅提升
- Claude Code:智能体团队协同,代码库处理更高效:作为研究预览版推出智能体团队功能,开发者可启动多个智能体,实现并行工作与自主协同,特别适合代码库审查、大型项目开发等可分解为独立读取密集型的任务。同时,开发者可通过Shift+上/下箭头或
tmux直接接管任意子智能体,实现对智能体工作的精准把控。 - Claude in Excel:性能跃升,支持复杂多步骤任务:完成重大升级后,Claude in Excel可处理更长时间、更复杂的任务,具备任务前置规划能力,能自动摄取非结构化数据并推断合理数据结构,无需人工指导即可一次性完成多步骤数据修改与分析,大幅提升数据处理效率。
- Claude in PowerPoint:研究预览版上线,办公协同形成闭环:全新推出Claude in PowerPoint研究预览版,面向Max、Team和Enterprise计划用户开放。该功能可读取用户的幻灯片布局、字体、母版样式,保持品牌视觉一致性,既可以基于现有模板优化内容,也可根据文字描述生成完整演示文稿。结合升级后的Claude in Excel,用户可实现“Excel数据处理→PowerPoint数据可视化”的全流程AI辅助,形成办公协同闭环。
实际使用体验:更智能的任务分配,专注高难度环节
Anthropic表示,其工程师团队已率先将Claude Opus 4.6应用于内部开发工作(Claude团队使用Claude构建Claude),从实际使用中发现该模型的核心体验提升:在无人工指示的情况下,模型可自主判断任务难度,快速处理简单环节,专注攻克最具挑战性的部分,对模糊问题的判断更精准,在长时间连续会话中能保持高效输出,无需频繁人工干预。
同时,Opus 4.6具备更深入的推理逻辑,会在确定最终答案前反复审视推理过程,大幅提升复杂问题解决的准确率,但这一特性可能会为简单任务增加少量成本与延迟。Anthropic建议,若用户发现模型在特定简单任务中存在“过度思考”,可将努力程度从默认设置调低一级,通过/effort参数即可快速调整,操作便捷。
目前,Claude Opus 4.6的早期访问合作伙伴已给出积极评价,认为该模型具备“无需手把手指导的自主工作能力”,能在前辈模型失败的复杂任务中取得成功,同时其智能体团队、长上下文处理等功能,正在改变团队的工作方式,大幅提升开发与办公效率。
Claude Opus 4.6,重新定义前沿大模型的能力边界
Claude Opus 4.6的正式发布,不仅是Anthropic旗舰模型的一次常规升级,更是对大模型“能力深度”与“应用广度”的双重拓展:在能力层面,百万令牌上下文解决了长文本处理的行业痛点,编程与推理能力的跃升让模型能承接更复杂的智能体任务;在应用层面,办公工具的全面升级让大模型从“单一任务辅助”转向“全流程协同”,真正融入日常工作与开发场景。
更重要的是,Anthropic在此次升级中实现了“智能提升与安全防护的双向平衡”——在模型能力大幅突破的同时,通过更全面的安全评估、更针对性的防护措施,将行为失准率降至新低,既避免模型滥用,又减少合法请求的误拒,为大模型的商业化落地提供了更可靠的安全保障。
此次升级定价保持不变,让开发者与用户能以原有成本享受更强大的模型能力,进一步降低了大模型的使用门槛。随着Claude Opus 4.6在各大平台的全面上线,以及Claude in PowerPoint等新功能的落地,大模型在专业开发、金融分析、日常办公等场景的应用边界将被持续打破,真正成为提升工作效率的核心工具。
附:Claude Opus 4.6快速使用指南
- 普通用户:直接访问claude.ai,登录后即可使用全新Opus 4.6模型,体验百万令牌上下文、办公工具协同等功能;
- 开发者:通过Anthropic官方API调用,模型标识为
claude-opus-4-6,可使用自适应思维、上下文压缩、四级努力程度等全新功能,定价为每百万令牌输入$5、输出$25; - 企业用户:可申请Anthropic Max/Team/Enterprise计划,解锁Claude in PowerPoint研究预览版、专属技术支持等权益,适配企业级办公与开发需求。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











