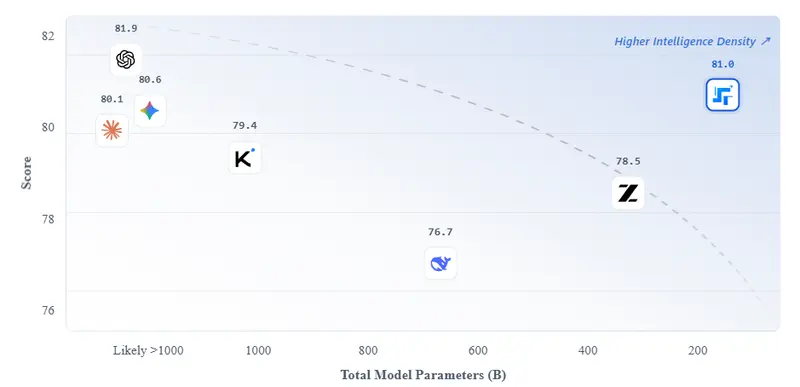
英伟达近日发布了 OpenReasoning-Nemotron 模型家族,这是一组专为数学、科学和编程推理任务优化的大语言模型。
该系列模型基于 DeepSeek R1 0528 671B 模型生成的高质量推理数据集进行训练,涵盖了 1.5B、7B、14B 和 32B 四种参数规模,已在 Hugging Face 平台开放下载,适用于强化学习(RL)研究、推理效率优化以及任务定制化探索。
多规模模型,适配不同研究需求
为满足不同计算资源下的研究需求,OpenReasoning-Nemotron 提供了四种模型:
- 1.5B
- 7B
- 14B
- 32B
这些模型基于 Qwen 2.5 架构构建,虽然 DeepSeek R1 0528 671B 仅发布了 8B 精炼模型,但英伟达通过数据精炼方法,成功训练出多种规模的模型,以支持更广泛的研究场景。
高质量数据精炼是关键
OpenReasoning-Nemotron 的核心优势在于其训练数据。英伟达利用 DeepSeek R1 0528 模型生成了 500万个高质量推理样本,涵盖:
- 数学问题求解
- 科学推理
- 编程任务
这些数据为模型提供了强大的推理基础。尽管数据集尚未公开,但训练和评估所用的完整代码已在 NeMo-Skills 平台开放,便于研究者复现实验并进一步优化。
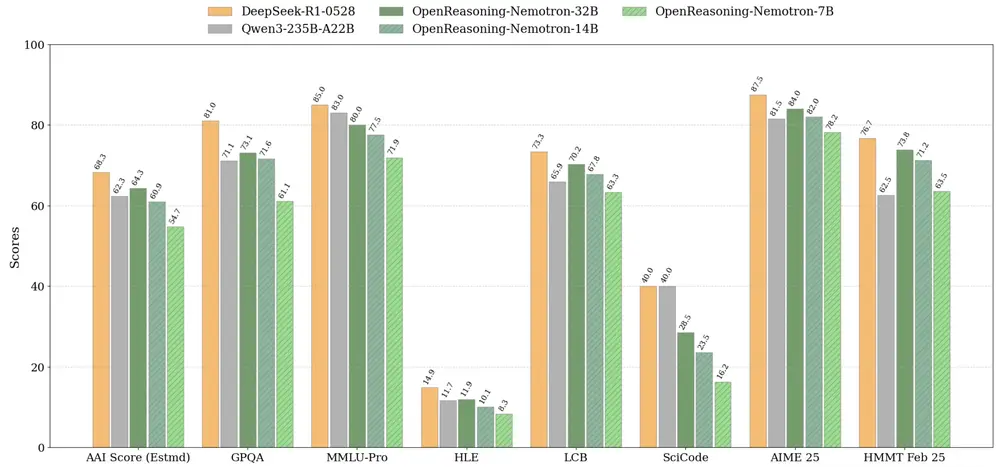
基准测试表现亮眼,树立新标准
OpenReasoning-Nemotron 模型在多个推理基准测试中表现出色,尤其在 数学与编程任务 上达到当前各规模模型中的最先进水平。
| 模型规模 | 基准表现 |
|---|---|
| 7B | 达到同规模最优 |
| 14B | 超越主流模型 |
| 32B | 接近甚至超越 o3(高)水平 |
这一成果表明,仅通过高质量数据的监督微调(SFT),就能在推理任务中取得显著突破。
多代理协作能力加持
OpenReasoning-Nemotron 还支持一种“重型”推理模式:GenSelect。
该模式通过并行生成多个解题方案并从中选择最优解,显著提升模型的准确率与鲁棒性。训练中使用了 DeepSeek R1 0528 的完整推理轨迹,虽然仅针对数学问题进行训练,但却意外泛化到了编程任务。
在 GenSelect 模式下,32B 模型在多个基准测试中得分接近甚至超越 o3(高)水平。
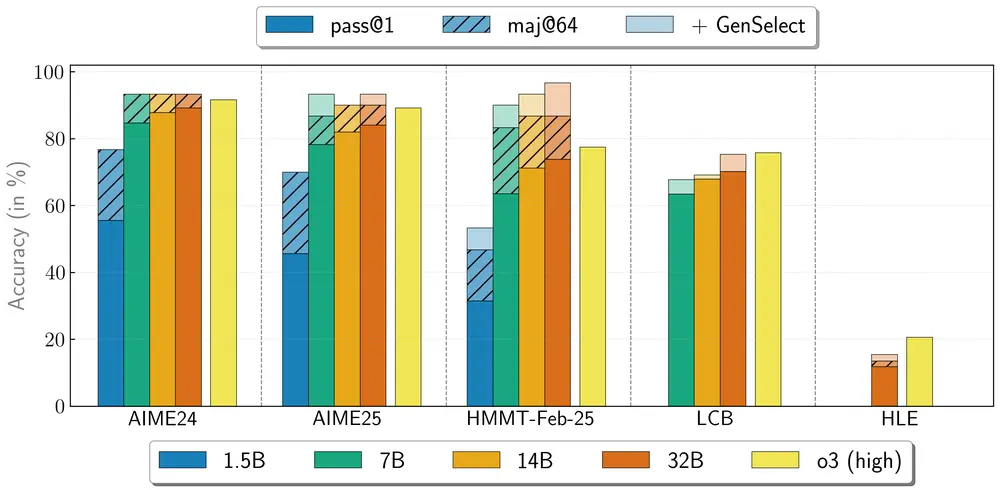
为强化学习研究提供坚实基础
此次发布的模型仅通过 监督微调(SFT)训练,并未引入强化学习(RL)机制。这一设计有意为之,旨在展示仅靠数据精炼能达到的推理上限,并为后续 RL 研究提供高质量起点。
结合 AceReasoning-Nemotron 的研究经验,英伟达团队提出了一种课程式 RL 训练策略,先训练数学推理,再引入科学与编程任务,显著提升了模型训练的稳定性。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章



暂无评论...











