英伟达近日发布了一款专为复杂推理任务设计的开源模型 —— Nemotron-Research-Reasoning-Qwen-1.5B,该模型参数量为 1.5B,在数学、编程、科学问题和逻辑谜题等任务上表现出色,成为当前同级别中性能最强的推理模型之一。
🧠 模型定位与适用场景
这款模型专注于以下几类高难度推理任务:
- 数学问题求解(如AIME、AMC、Math等)
- 编程挑战(CodeContests、Codeforces、HumanEvalPlus 等)
- STEM 科学推理(GPQA Diamond)
- 逻辑谜题与指令遵循(IFEval、Reasoning Gym)
适用于科研机构、开发者和AI研究人员在算法探索、教育辅助、代码生成等领域进行实验与开发。
⚠️ 注意:该模型仅限研究与开发使用,不可用于商业用途。
🔍 ProRL 算法:强化学习的新突破
为了提升模型在复杂推理任务中的表现,英伟达引入了全新的 ProRL(Progressive Reinforcement Learning)算法,其核心目标是通过延长训练周期,挖掘更深层次的推理策略。
ProRL 的三大关键技术包括:
- 缓解熵崩溃:防止策略在训练过程中过早收敛。
- 解耦裁剪与动态采样策略优化(DAPO):提升样本效率和泛化能力。
- KL正则化与参考策略重置:保持训练稳定性并避免偏差积累。
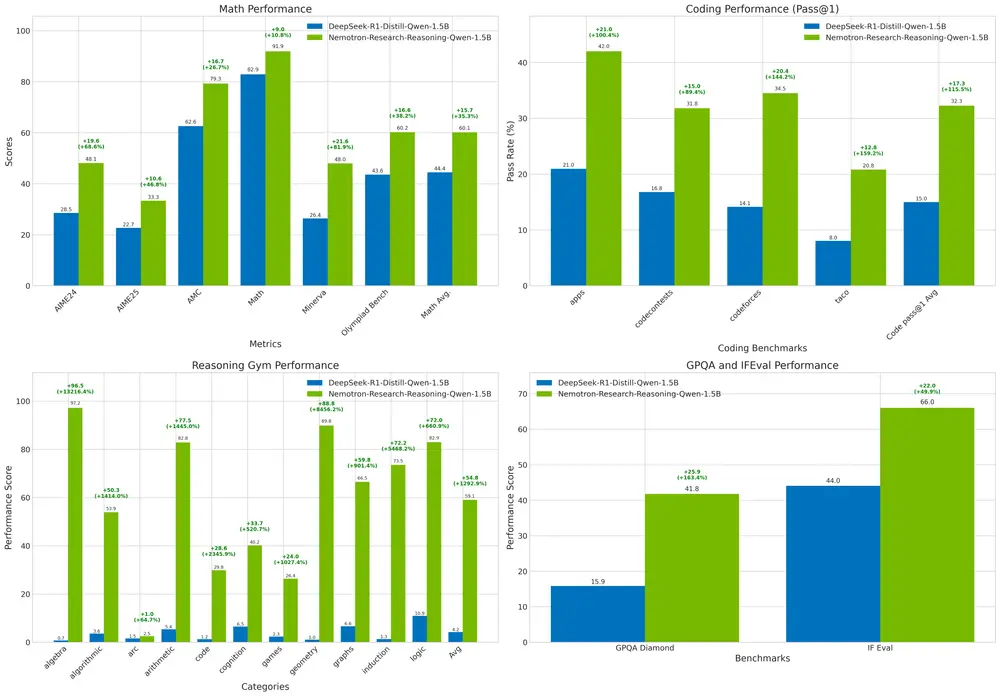
得益于这些技术,Nemotron 在多个基准测试中显著超越基础模型 DeepSeek-R1-1.5B,甚至在某些任务上的表现接近或超过 DeepSeek-R1-7B 模型。
📊 性能对比:全面领先
表1|数学领域平均 pass@1 提升显著
| 模型 | AIME24 | AIME25 | AMC | Math | Minerva | Olympiad | 平均 |
|---|---|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 28.54 | 22.71 | 62.58 | 82.90 | 26.38 | 43.58 | 44.45 |
| Nemotron-Research-Reasoning-Qwen-1.5B | 48.13 | 33.33 | 79.29 | 91.89 | 47.98 | 60.22 | 60.14 |
相比 DeepSeek-1.5B,平均提升 14.7%
表2|编程任务表现优异
| 模型 | apps | codecontests | codeforces | taco | humanevalplus | livecodebench | 平均 |
|---|---|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 20.95 | 16.79 | 14.13 | 8.03 | 61.77 | 16.80 | 23.08 |
| Nemotron-Research-Reasoning-Qwen-1.5B | 41.99 | 31.80 | 34.50 | 20.81 | 72.05 | 23.81 | 37.49 |
编程任务平均提升 13.9%
表3|STEM推理与逻辑谜题表现亮眼
| 模型 | GPQA | IFEval | Reasoning Gym | acre | boxnet | game_of_life_halting |
|---|---|---|---|---|---|---|
| DeepSeek-R1-Distill-Qwen-1.5B | 15.86 | 44.05 | 4.24 | 5.99 | 0.00 | 3.49 |
| Nemotron-Research-Reasoning-Qwen-1.5B | 41.78 | 66.02 | 59.06 | 58.57 | 7.91 | 52.29 |
在逻辑谜题任务上提升高达 54.8%
📦 训练数据集开放下载
Nemotron 基于多种高质量推理数据集进行训练,部分数据集已公开提供下载,包括:
- DeepScaleR-Preview-Dataset
- Eurus-2-RL-Data
- Reasoning-gym
- IFEval
- SCP-116K
可通过官方链接访问相关资源。
📄 使用许可与道德声明
本模型采用 CC-BY-NC-4.0 授权协议,仅供非商业用途的研究与开发。
英伟达强调 AI 技术的可信性与责任共担原则,要求使用者在部署模型时遵守服务条款,并与内部团队合作,确保符合行业规范与伦理标准。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











