
阿里 QWEN 团队在今天推出 Qwen3,这是 Qwen 系列大言模型的最新力作。Qwen3 以其卓越的性能和广泛的应用潜力,正在成为开源AI领域的新焦点。

性能突破:超越行业标杆
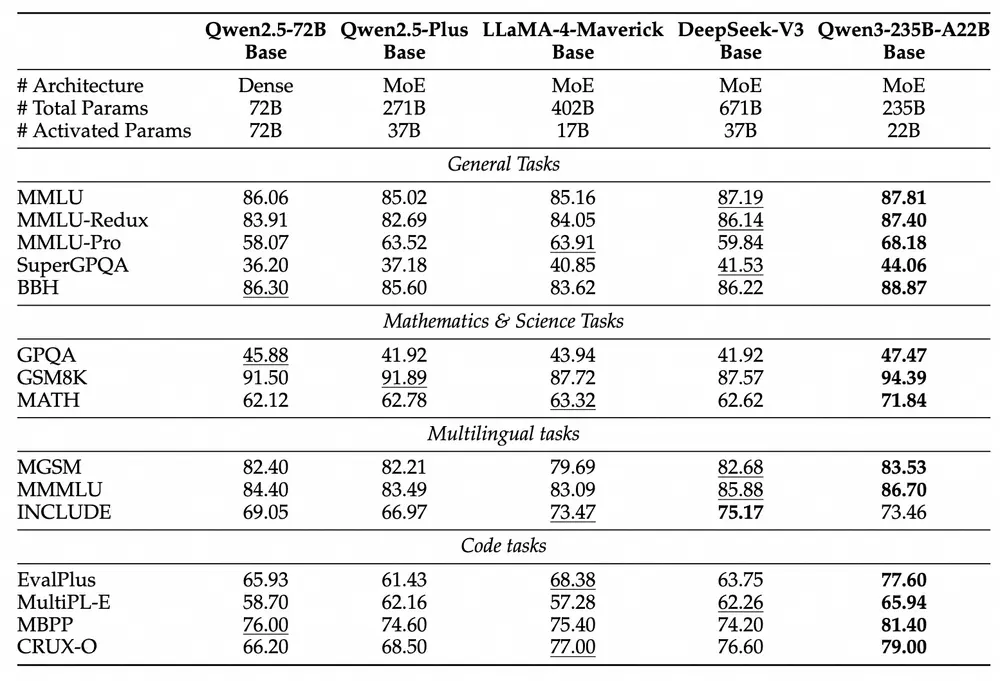
Qwen3 的旗舰模型 Qwen3-235B-A22B 在代码、数学和通用能力等基准测试中表现出色,与 DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等顶级模型相比毫不逊色。此外,小型 MoE 模型 Qwen3-30B-A3B 的激活参数数量仅为 QwQ-32B 的 10%,却能实现更优的性能表现,甚至像 Qwen3-4B 这样的小模型也能匹敌 Qwen2.5-72B-Instruct 的性能。
- 项目主页:https://qwenlm.github.io/zh/blog/qwen3
- GitHub:https://github.com/QwenLM/Qwen3
- Hugging Face:https://huggingface.co/collections/Qwen/qwen3-67dd247413f0e2e4f653967f
- 魔塔:https://modelscope.cn/collections/Qwen3-9743180bdc6b48
- Kaggle:https://www.kaggle.com/models/qwen-lm/qwen-3
- Ollama:https://ollama.com/library/qwen3
- Demo:https://huggingface.co/spaces/Qwen/Qwen3-Demo
- 官网:https://chat.qwen.ai
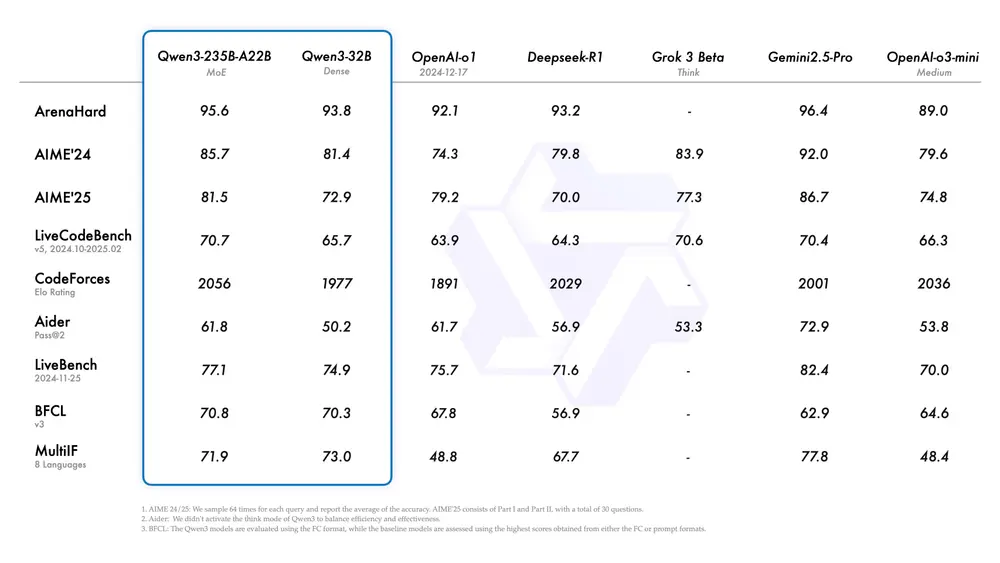
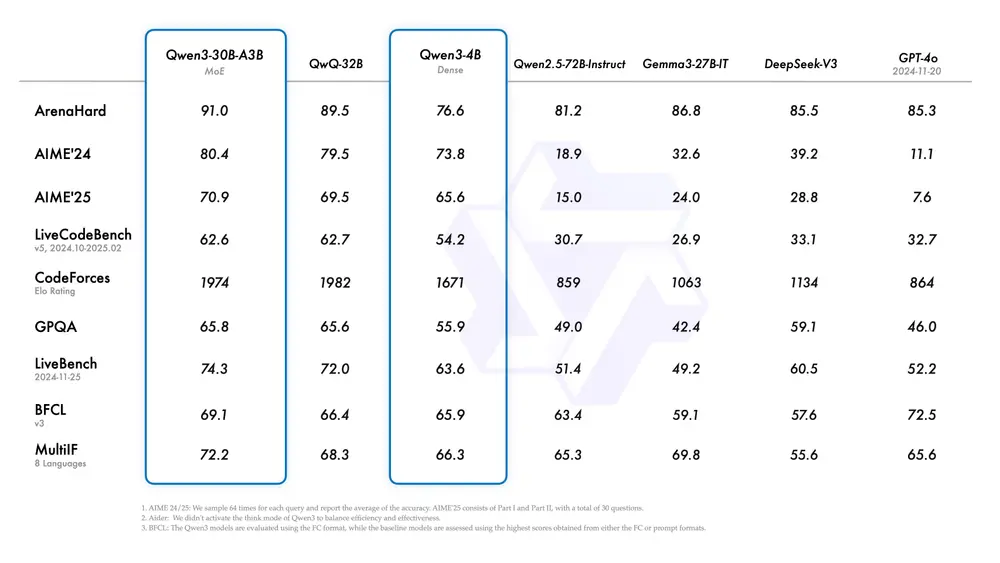
开源助力:赋能全球开发者
为了推动大型基础模型的研究与开发,阿里 QWEN 团队开源了多个 Qwen3 模型的权重,包括:
- Qwen3-235B-A22B:拥有 2350 多亿总参数和 220 多亿激活参数的超大模型。
- Qwen3-30B-A3B:拥有约 300 亿总参数和 30 亿激活参数的小型 MoE 模型。
- 六个 Dense 模型:包括 Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B,均在 Apache 2.0 许可下开源。
Qwen3 包含两类主要结构:
MoE(Mixture of Experts)模型:适用于高性能推理任务 Dense 模型:适用于更广泛的本地部署和轻量级使用场景
✅ 开源模型列表
| 模型名称 | 类型 | 总参数量 | 激活参数量 |
|---|---|---|---|
| Qwen3-235B-A22B | MoE | 超 2350 亿 | 超 220 亿 |
| Qwen3-30B-A3B | MoE | 约 300 亿 | 约 30 亿 |
| Qwen3-32B | Dense | 320 亿 | - |
| Qwen3-14B | Dense | 140 亿 | - |
| Qwen3-8B | Dense | 80 亿 | - |
| Qwen3-4B | Dense | 40 亿 | - |
| Qwen3-1.7B | Dense | 17 亿 | - |
| Qwen3-0.6B | Dense | 6 亿 | - |
这些开源模型现已在 Hugging Face、ModelScope 和 Kaggle 等平台上开放使用。对于部署,推荐使用 SGLang 和 vLLM 等框架;而本地使用则可以借助 Ollama、LMStudio、MLX、llama.cpp 和 KTransformers 等工具,确保用户能够轻松将 Qwen3 集成到他们的工作流程中。
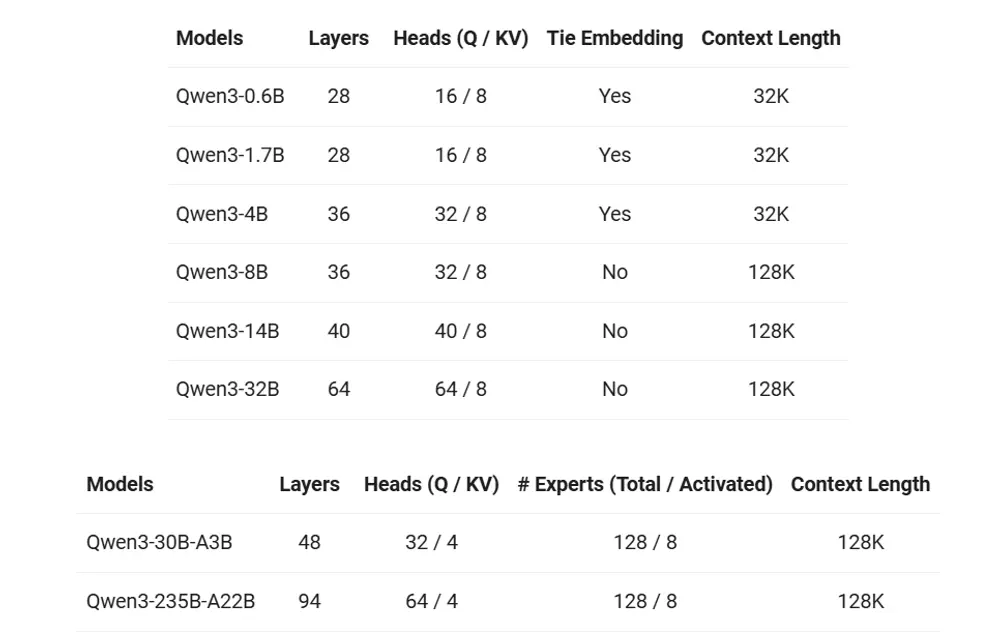
核心亮点:灵活、多语言、强 Agent 能力
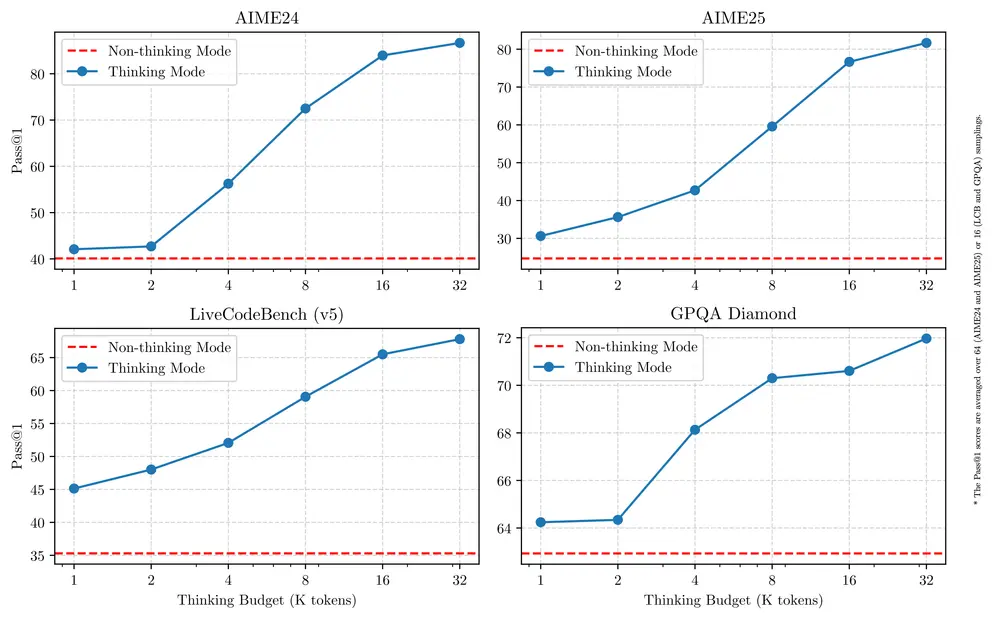
多种思考模式:Qwen3 支持“思考模式”和“非思考模式”,用户可以根据具体任务需求,灵活控制模型的推理深度。思考模式适合复杂问题的逐步推理,而非思考模式则提供快速响应,适用于简单问题。这种设计让用户能够更好地平衡成本效益与推理质量。
多语言支持:Qwen3 支持 119 种语言和方言,极大地拓展了其在国际应用中的可能性,让全球用户都能受益于其强大的功能。

增强的 Agent 能力:Qwen3 的 Agent 和代码能力得到了优化,同时加强了对 MCP 的支持。通过示例展示,Qwen3 能够高效地思考并与环境进行交互。
预训练与后训练:数据与架构的双重升级
预训练:Qwen3 的数据集规模相比 Qwen2.5 有了显著扩展,从 18 万亿个 token 增加到约 36 万亿个 token,涵盖 119 种语言和方言。预训练过程分为三个阶段,逐步提升模型的语言技能和推理能力。通过增加知识密集型数据和长上下文数据,Qwen3 在 STEM、编码和推理等领域表现出色。
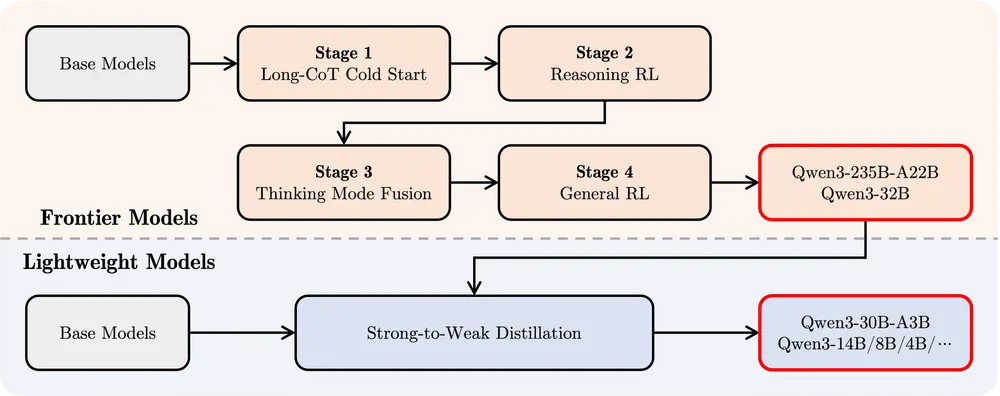
后训练:为了开发兼具思考推理和快速响应能力的混合模型,Qwen3 采用了四阶段训练流程,包括长思维链冷启动、强化学习、模式融合和通用强化学习。这一流程确保了模型在复杂任务和简单任务上的均衡表现。
未来展望:迈向通用人工智能
Qwen3 是阿里 QWEN 团队在通往通用人工智能(AGI)和超级人工智能(ASI)道路上的重要一步。通过扩大预训练和强化学习的规模,Qwen3 实现了更高层次的智能。未来,团队计划从多个维度提升模型性能,包括优化模型架构、扩展数据规模、增加模型大小、延长上下文长度、拓宽模态范围,并利用环境反馈推进强化学习。
阿里 QWEN 团队表示,他们正从专注于训练模型的时代过渡到以训练 Agent 为中心的时代。下一代迭代将为用户的工作和生活带来更多有意义的进步。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











