在语言模型(LLM)领域,尽管通用任务性能取得了显著进展,但实现强大的多步推理能力仍然是一个重大挑战。这种能力对于复杂问题解决场景(如科学研究和战略规划)至关重要。然而,传统方法如监督微调(SFT)虽然有效,却依赖于昂贵的高质量推理轨迹,容易导致肤浅模仿而非真正的逻辑探索。相比之下,强化学习(RL)通过直接从奖励信号中学习,能够鼓励更广泛的推理探索,但其高昂的资源需求和复杂性成为普及的主要障碍。
为了解决这一问题,南加州大学的研究团队推出了 Tina,一种利用LoRA技术实现低成本强化学习的小型推理模型系列。Tina 不仅显著降低了训练成本,还在性能上超越或匹敌了现有的最先进模型,展示了小型模型的巨大潜力。
背景与挑战
1.多步推理的重要性
复杂的推理任务需要模型能够逐步解决问题,而不是简单地生成答案。例如,在数学问题、科学研究或战略规划中,模型必须能够分解问题、探索多种可能性并得出逻辑推导的结果。
2.现有方法的局限性
监督微调(SFT):依赖于高质量推理轨迹,这些轨迹通常由更高级模型生成,成本高昂且可能导致模型仅仅“模仿”而无法真正理解推理过程。 强化学习(RL):虽然能够促进更深层次的探索,但其资源密集性和复杂性使其难以广泛采用。
3.创新方向
为了降低 RL 的成本,研究人员转向了LoRA(低秩自适应)方法。LoRA 通过对模型参数的一小部分进行更新,既减少了计算需求,又保留了模型的基础知识和推理能力。
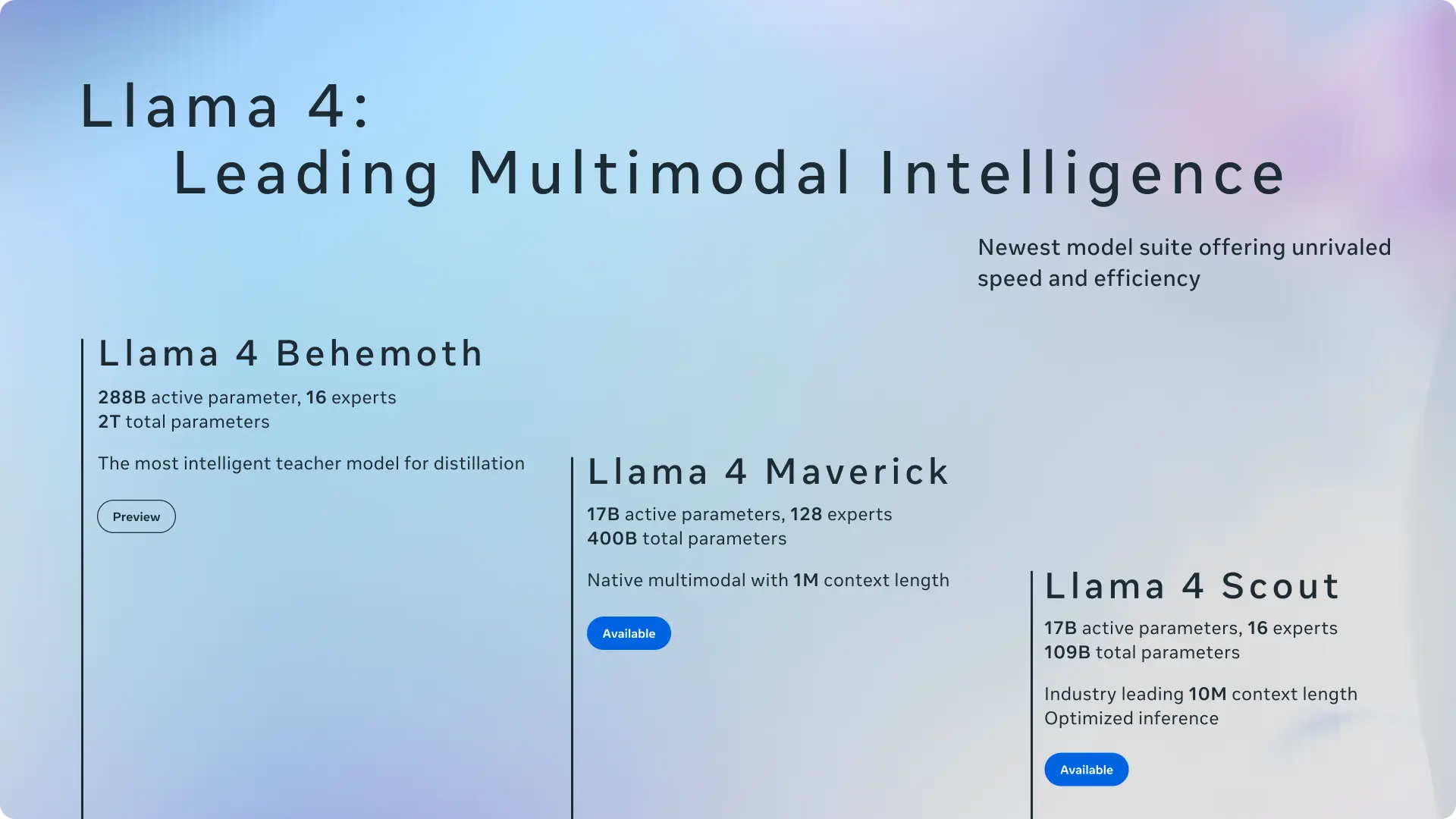
Tina:轻量级推理模型的核心设计
1.基础架构
Tina 基于DeepSeek-R1-Distill-Qwen-1.5B模型构建,这是一个仅有 15 亿参数的小型基础模型。通过在强化学习过程中应用 LoRA 技术,Tina 在保持高效的同时实现了强大的推理性能。
2.训练策略
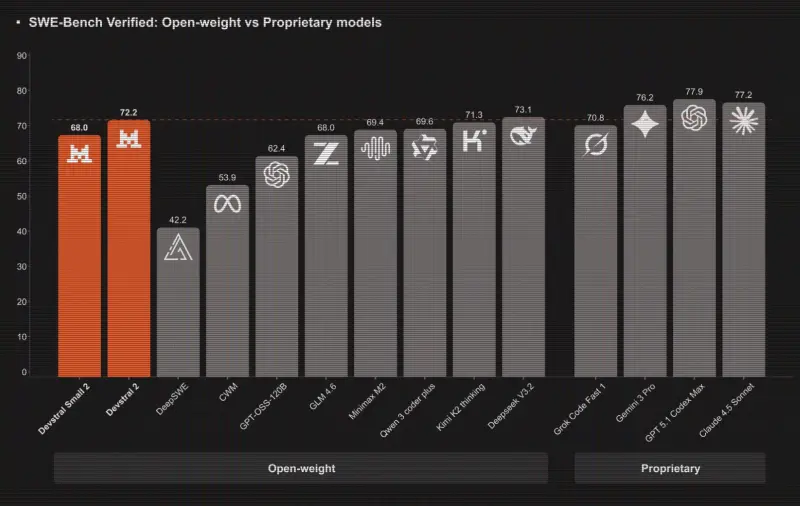
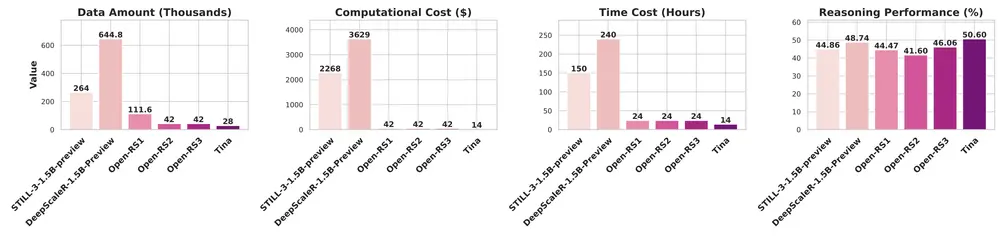
GRPO 式方法:Tina 使用了类似群体相对策略优化(GRPO)的技术,消除了对独立价值网络的需求,从而提高了训练效率。 公共数据集:训练数据来自开源项目(如 STILL-3、DeepScaleR 和 Open-RS),确保了数据的多样性和可访问性。 极简硬件需求:整个训练过程仅使用两个 NVIDIA L40S GPU(偶尔辅以 RTX 6000 Ada GPU),每个实验的平均预算远低于 100 美元。
3.性能亮点
高性价比:Tina 的最佳模型在 AIME24 上实现了43.33% 的 Pass@1 准确率,同时训练后成本仅为9 美元。 推理性能提升:相比基线模型,Tina 的推理能力提升了20% 以上。 高效训练:即使在极少的训练数据(仅完成 19%-57% 的一个 epoch)下,Tina 的表现仍优于全参数微调的大型模型。
实验与评估
为了验证 Tina 的性能,研究人员采用了以下方法:
公平比较:使用 LightEval 框架和 vLLM 引擎重新评估基线模型,确保评估环境一致。 推理基准测试:包括 AIME 24/25、AMC 23、MATH 500、GPQA 和 Minerva 等六个推理基准。 消融研究:结果表明,较小的高质量数据集、适当的学习率、适中的 LoRA 秩以及精心选择的 RL 算法显著影响了性能。
实验结果显示,Tina 在多个基准测试中表现出色,甚至在某些任务上超越了更大规模的全参数微调模型。
Tina 的优势与局限性
优势
低成本:通过 LoRA 和 GRPO 式方法,Tina 将训练成本降至最低,适合资源有限的研究者和开发者。 高性能:尽管模型规模小,Tina 的推理能力不输于更大的最先进模型。 完全开源:所有代码、日志和模型检查点均已公开,促进了社区的进一步研究和改进。
局限性
模型规模较小:15 亿参数的模型在处理极端复杂任务时可能仍有不足。 推理任务多样性有限:目前主要针对特定领域的推理任务,未来需扩展到更多场景。 超参数调整较少:为了简化流程,实验中未进行过多的超参数优化,可能存在进一步提升空间。
未来展望
Tina 的推出为小型推理模型的研究开辟了新方向。通过结合 LoRA 和高效的 RL 方法,Tina 展示了如何以极低的成本实现强大的推理能力。未来的研究可以集中在以下方面:
扩展任务范围:将 Tina 应用于更广泛的推理任务,如自然语言理解、代码生成等。 优化超参数:进一步调整学习率、LoRA 秩等参数,提升模型性能。 探索更大规模模型:在保持低成本的前提下,研究如何将 LoRA 技术应用于更大规模的模型。
© 版权声明
文章版权归作者所有,未经允许请勿转载。
相关文章

暂无评论...











